机器学习和人工智能领域的研究,现在几乎是每个行业和公司的一项关键技术,对于任何人来说都过于庞大,无法通读。本专栏Perceptron旨在收集一些最相关的最新发现和论文——特别是但不限于人工智能——并解释它们为何重要。
过去几周吸引我们眼球的项目之一是使用声纳读取面部表情的“ earable ”。 ProcTHOR也是如此,这是一个来自艾伦人工智能研究所 (AI2) 的框架,它以程序方式生成可用于训练现实世界机器人的环境。在其他亮点中,Meta 创建了一个人工智能系统,该系统可以在给定单个氨基酸序列的情况下预测蛋白质的结构。麻省理工学院的研究人员开发了新的硬件,他们声称这些硬件可以以更少的能量为人工智能提供更快的计算。
由康奈尔大学的一个团队开发的“earable”看起来像一副笨重的耳机。扬声器将声音信号发送到佩戴者的脸部侧面,而麦克风则拾取由鼻子、嘴唇、眼睛和其他面部特征产生的几乎无法察觉的回声。这些“回声配置文件”使耳机能够捕捉眉毛抬起和眼睛飞镖等动作,人工智能算法将其转化为完整的面部表情。
图片来源:康奈尔
耳塞有一些限制。它仅能持续使用电池三个小时,并且必须将处理任务转移到智能手机上,并且回声翻译 AI 算法必须训练 32 分钟的面部数据才能开始识别表情。但研究人员认为,与传统上用于电影、电视和视频游戏动画的记录器相比,它的体验要流畅得多。例如,对于神秘游戏 LA Noire,Rockstar Games 构建了一个装备,在每个演员的脸上训练了 32 个摄像头。
或许有一天,康奈尔的可穿戴设备将用于为类人机器人制作动画。但这些机器人必须先学会如何在房间里导航。幸运的是,AI2 的 ProcTHOR 朝着这个方向迈出了一步(不是双关语),创建了数千个自定义场景,包括教室、图书馆和办公室,模拟机器人必须在这些场景中完成任务,比如捡起物体和在家具周围移动。
具有模拟照明并包含大量表面材料(例如木材、瓷砖等)和家用物品的子集的场景背后的想法是让模拟机器人尽可能多地接触。模拟环境中的性能可以提高现实世界系统的性能,这是人工智能中一个成熟的理论;像 Alphabet 的 Waymo 这样的自动驾驶汽车公司会模拟整个社区,以微调他们在现实世界中汽车的行为方式。

图片来源:艾伦人工智能研究所
至于 ProcTHOR,AI2 在一篇论文中声称,扩展训练环境的数量可以持续提高性能。这对于适用于家庭、工作场所和其他地方的机器人来说是个好兆头。
当然,训练这些类型的系统需要大量的计算能力。但情况可能不会永远如此。麻省理工学院的研究人员表示,他们已经创建了一种“模拟”处理器,可用于创建“神经元”和“突触”的超高速网络,进而可用于执行识别图像、翻译语言等任务。
研究人员的处理器使用排列成阵列的“质子可编程电阻器”来“学习”技能。增加和减少电阻器的电导模拟大脑中神经元之间突触的增强和减弱,这是学习过程的一部分。
电导由控制质子运动的电解质控制。当更多的质子被推入电阻器的通道时,电导增加。当质子被去除时,电导降低。

计算机电路板上的处理器
一种无机材料,磷硅玻璃,使麻省理工学院团队的处理器速度非常快,因为它包含纳米尺寸的孔,其表面为蛋白质扩散提供了完美的路径。作为一个额外的好处,玻璃可以在室温下运行,并且在蛋白质沿着毛孔移动时不会被蛋白质损坏。
“一旦你有了一个模拟处理器,你将不再训练其他人都在研究的网络,”主要作者和麻省理工学院博士后 Murat Onen 在新闻稿中被引述说。 “你将训练具有前所未有的复杂性的网络,这是其他人无法承受的,因此将大大超越所有网络。换句话说,这不是一辆更快的汽车,这是一艘宇宙飞船。”
说到加速,机器学习现在正被用于管理粒子加速器,至少以实验形式。在劳伦斯伯克利国家实验室,两个团队已经证明,基于 ML 的整台机器和光束模拟可以提供比普通统计分析高出 10 倍的高精度预测。

图片来源: Thor Swift/伯克利实验室
实验室的 Daniele Filippetto 说:“如果您能够以超过其波动的精度预测光束特性,那么您就可以使用该预测来提高加速器的性能。”模拟所涉及的所有物理和设备并非易事,但令人惊讶的是,各个团队的早期努力都取得了可喜的成果。
在橡树岭国家实验室,一个由人工智能驱动的平台让他们使用中子散射进行高光谱计算机断层扫描,找到最佳……也许我们应该让他们解释一下。
在医学界,基于机器学习的图像分析在神经病学领域有了新的应用,伦敦大学学院的研究人员已经训练了一个模型来检测引起癫痫的脑损伤的早期迹象。
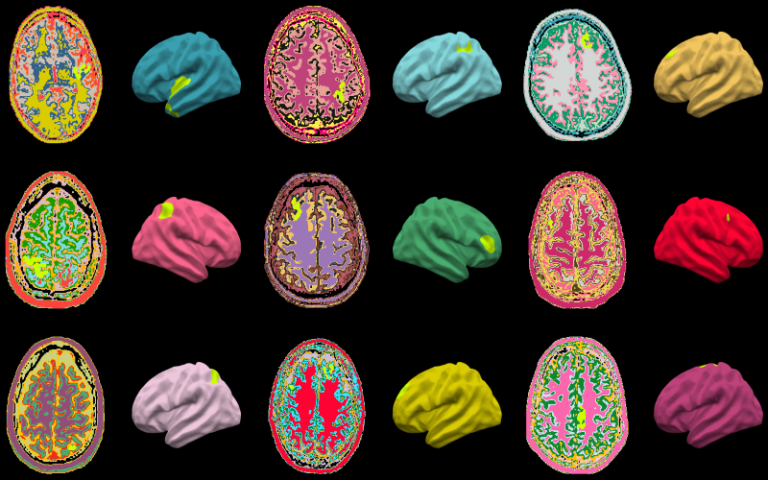
用于训练 UCL 算法的大脑 MRI。
耐药性癫痫的一个常见原因是所谓的局灶性皮质发育不良,这是大脑中发育异常但无论出于何种原因在 MRI 中未出现明显异常的区域。及早发现它非常有帮助,因此 UCL 团队在数千个健康和受 FCD 影响的大脑区域的例子上训练了一个称为多中心癫痫病变检测的 MRI 检查模型。
该模型能够检测到它所显示的三分之二的 FCD,这实际上非常好,因为迹象非常微妙。事实上,它发现了 178 例医生无法找到 FCD 但可以找到的病例。当然,最终决定权在专家手中,但有时只需一台暗示可能有问题的计算机,就可以仔细观察并获得自信的诊断。
“我们强调创建一种可解释的人工智能算法,可以帮助医生做出决定。向医生展示 MELD 算法如何做出预测是该过程的重要组成部分,”UCL 的 Mathilde Ripart 说。