欢迎来到这篇文章!作为“TIL”,它是一篇故意较小的博客文章,仅包含关键细节。如果您想了解更多信息,请查看技术报告或使用HuggingFace 上的模型!
长话短说
传统上(当然也有一些例外),BERT 等编码器模型与核心编码器模型之上的特定于任务的头一起使用。从功能上讲,这意味着我们放弃存储在掩码语言建模头(预训练期间使用的头)中的所有语言建模优点,并寻求简单地重新使用主干来执行各种任务。
这非常有效:它成为主导范例是有原因的!然而,如果生成头本身实际上可以执行大多数任务,甚至是零样本呢?这就是我们尝试过的,效果非常好!我们推出了 ModernBERT-Large-Instruct,这是一种在 ModernBERT-Large 之上进行微调的“指令调整”编码器,其机制极其简单。它可用于使用 ModernBERT 的 MLM 头而不是特定于任务的头来执行分类和多项选择任务。与以前的方法不同,我们的方法不需要架构更改,也不需要复杂的管道,并且仍然在各种任务中取得了很好的结果。
- 它在知识 QA 任务中的能力令人惊讶,而编码器通常很弱:在 MMLU-Pro 排行榜上,它优于 Qwen2.5-0.5B 和 SmolLM2-360M 等所有 sub-1B 模型,并且非常接近 Llama3-1B(使用更多的标记进行训练,并且参数是 3 倍)!
- 在 NLU 任务中,在同一数据集上进行微调时,ModernBERT-Instruct 的微调可匹配或优于传统分类头。
- 我们通过超级简单的训练方法实现了这些结果,这令人兴奋:未来肯定有很大的改进空间👀👀
我只是想尝试一下!
该模型在 HuggingFace 上以ModernBERT-Large-Instruct 形式提供。由于它不需要任何自定义注意掩模或类似的东西,因此零样本管道的设置和使用非常简单:
import torch from transformers import AutoTokenizer, AutoModelForMaskedLM # Load model and tokenizer model_name = "answerdotai/ModernBERT-Large-Instruct" tokenizer = AutoTokenizer.from_pretrained(model_name) device = 'cuda' if torch.cuda.is_available() else 'cpu' if device == 'cuda' : model = AutoModelForMaskedLM.from_pretrained(model_name, attn_implementation = "flash_attention_2" ) else : model = AutoModelForMaskedLM.from_pretrained(model_name) model.to(device) # Format input for classification or multiple choice. This is a random example from MMLU. text = """You will be given a question and options. Select the right answer. QUESTION: If (G, .) is a group such that (ab)^-1 = a^-1b^-1, for all a, b in G, then G is a/an CHOICES: - A: commutative semi group - B: abelian group - C: non-abelian group - D: None of these ANSWER: [unused0] [MASK]""" # Get prediction inputs = tokenizer(text, return_tensors = "pt" ).to(device) outputs = model( ** inputs) mask_idx = (inputs.input_ids == tokenizer.mask_token_id).nonzero()[ 0 , 1 ] pred_id = outputs.logits[ 0 , mask_idx].argmax() answer = tokenizer.decode(pred_id) print ( f"Predicted answer: { answer } " ) # Outputs: B
如需了解更多信息,您需要查看我们的迷你食谱 GitHub 存储库,其中包含有关如何微调模型的示例!
介绍
传统上,编码器模型在具有特定任务头的所有任务上表现最佳。虽然不一定是问题,但这感觉有点浪费:MLM 头(其原始预训练头)被完全丢弃。在实践中,这是可行的,但也感觉我们可能会留下一些东西。此外,这对零样本能力造成了很大的限制:由于通常总是需要特定于任务的头,因此有必要找到各种技巧来解决这个问题并仍然获得良好的零样本性能。
MLM 编码器下游使用的简短、不完整的历史
使用编码器模型的零样本分类一直是一个活跃的研究领域,多年来尝试了各种方法。最常见的方法是重新调整文本蕴涵的用途:在对 MNLI 等任务进行训练后,使用模型来预测输入文本是否蕴含给定标签。一些非常强大的模型已经在大规模TaskSource数据集上进行了训练,例如tasksource/ModernBERT-large-nli 。
这也绝对不是第一个探索生成式 BERT 作为多任务学习器的工作:已经有一些工作通过模式利用训练(PET)方法进行提示、样本高效训练,甚至使模型自回归!有些方法甚至与我们的方法非常相似,例如UniMC,它通过使用语义中性的语言表达器(例如,“A”、“B”而不是有意义的单词)将任务转换为多项选择格式并采用自定义注意掩码,显示出了前景。
然而,所有这些方法都有缺点:有些方法要么很脆弱(特别是对于不同的语言表达者来说),要么达到了有希望但并非完全有效的性能,而另一些方法虽然达到了非常好的结果,但增加了相当大的复杂性。与此同时,在解码器领域(或者,如果你愿意的话,LLMTopia),指令调优进展非常迅速,而且由于指令训练,大型、可怕的 LLM 已经变得非常擅长生成分类,尤其是零样本分类。
但这也有缺点:小型法学硕士通常会被编码器超越,而编码器经过微调后甚至可以与大型法学硕士相媲美!此外,运行自回归 LLM 的计算成本(即使是较小的一侧)通常也比在单次前向传递中执行任务的编码器大得多。
ModernBERT-大型指令
我们的方法旨在表明,也许,只是也许,我们可以鱼与熊掌兼得:如果传销可以通过单次前向传播以生成方式处理任务(甚至是零样本任务!),并且可以轻松地进一步微调以在域内执行更好的操作,而不增加任何管道或架构复杂性,那会怎么样?
这就是我们在这里展示的潜力!我们使用非常简单的训练方法,并使用 ModernBERT 的 MLM 头进行 FLAN 式指令调整。我们没有自定义注意力掩码,没有复杂的提示工程,也没有严厉的数据预处理管道:我们只是将 FLAN 过滤为仅可以使用单个标记回答的任务,并从我们用于下游评估的数据集中过滤掉一些示例。
它是如何运作的
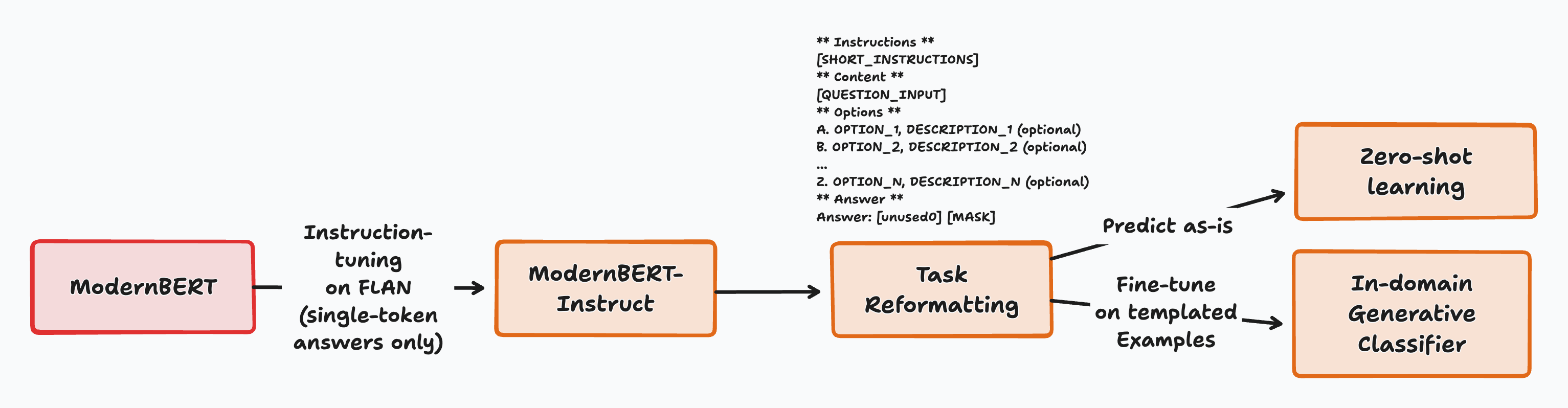
整个流程的高级概述
我们的关键见解有两个:ModernBERT 可以使用单头执行大多数 NLU 任务,无论是零样本还是完全微调,并且这种行为可以通过极其简单的训练方法来解锁,这表明它具有非常强大的潜力。
它的工作方式非常简单:
- 所有任务的格式都使模型可以使用单个标记进行回答,这也是输入的最终标记。这始终以锚标记 (
[unused0]) 开头,以告诉模型下一个标记需要是单个标记答案。 - 该模型会收到一个问题、简短说明以及一系列可能的选择。所有选择都以单标记语言器开头:这是模型在分配此标签时将预测的标记。
- 然后,模型预测最有可能的答案标记,并选择得分最高的潜在语言表达者作为答案。
这种方法有几个优点: – 训练或推理不需要进行架构更改。 – 可以在任何支持开箱即用的屏蔽语言建模的模型上进行尝试。 – 开始实验只需要很少的数据预处理。 – 同样,它大大减少了即时工程:只需编写一个非常短的模板和所有标签的描述即可执行任务。
培训详情
如上所述,训练方法自愿保持简单。这主要是为了避免范围蔓延:通过使用更好的处理管道或更现代的指令集,可以探索许多潜在的改进,但这些都需要复杂的过程才能将它们转变为单令牌任务。
- 数据:下采样(20M 样本)、过滤的 FLAN-2022 数据集,仅保留单标记答案。一种非常简单的过滤过程:对潜在答案进行标记,并排除答案包含多个标记的所有示例。我们的评估数据集中的示例也被过滤掉,以避免过度拟合。
- 目标:我们使用答案标记预测(ATP)目标,它是预测单个掩码标记,该标记应该是包含答案的语言描述器。最终的训练目标是 80% ATP 和 20% 虚拟 MLM 示例的混合,其中屏蔽令牌被赋予无意义的标签(见下文)。
- 基础模型: ModernBERT-Large (395M参数),这是我们最近在LightOn等地方与朋友们介绍的。事实证明,它是一个比其他替代方案功能更强大的基础模型。
虚拟示例
在训练模型时,我们推测答案标记预测可能会导致灾难性遗忘,因为模型仅学习预测某些标记并失去整体推理能力。为了解决这个问题,我们引入了训练目标组合,其中 20% 的示例被分配了正常的 MLM 目标(其中文本中的 30% 的标记被随机屏蔽,并且模型必须立即预测所有标记),其余 80% 采用答案标记预测目标。
除此之外,我们错误地实现了这一点,并有效地使这些样本变成了空示例,我们将其称为“虚拟 MLM 示例”。问题在于标签:它们都被赋予了[MASK]作为标签,而不是为 [ [MASK]标记分配了适当的标签。这意味着,如果文本中存在多个[MASK]标记,则模型学会了简单地预测所有示例的[MASK] ,并且这些示例的损失很快降至接近于零。
嗯,简单的错误,很容易修复,对吧?正确的。除此之外,我们观察到了一些我们没有预料到的事情:我们评估了三种预训练设置(100% ATP、80% ATP/20% MLM、80% ATP/20% 虚拟),我们发现虚拟示例变体是表现最好的一个,而且差距很大!虽然我们还没有足够深入地探索这种现象来解释正在发生的事情,但我个人的理论是,它充当正则化的一种形式,类似于 dropout。
表现
零样本结果
零样本结果非常令人鼓舞,并且在某种程度上非常令人惊讶!
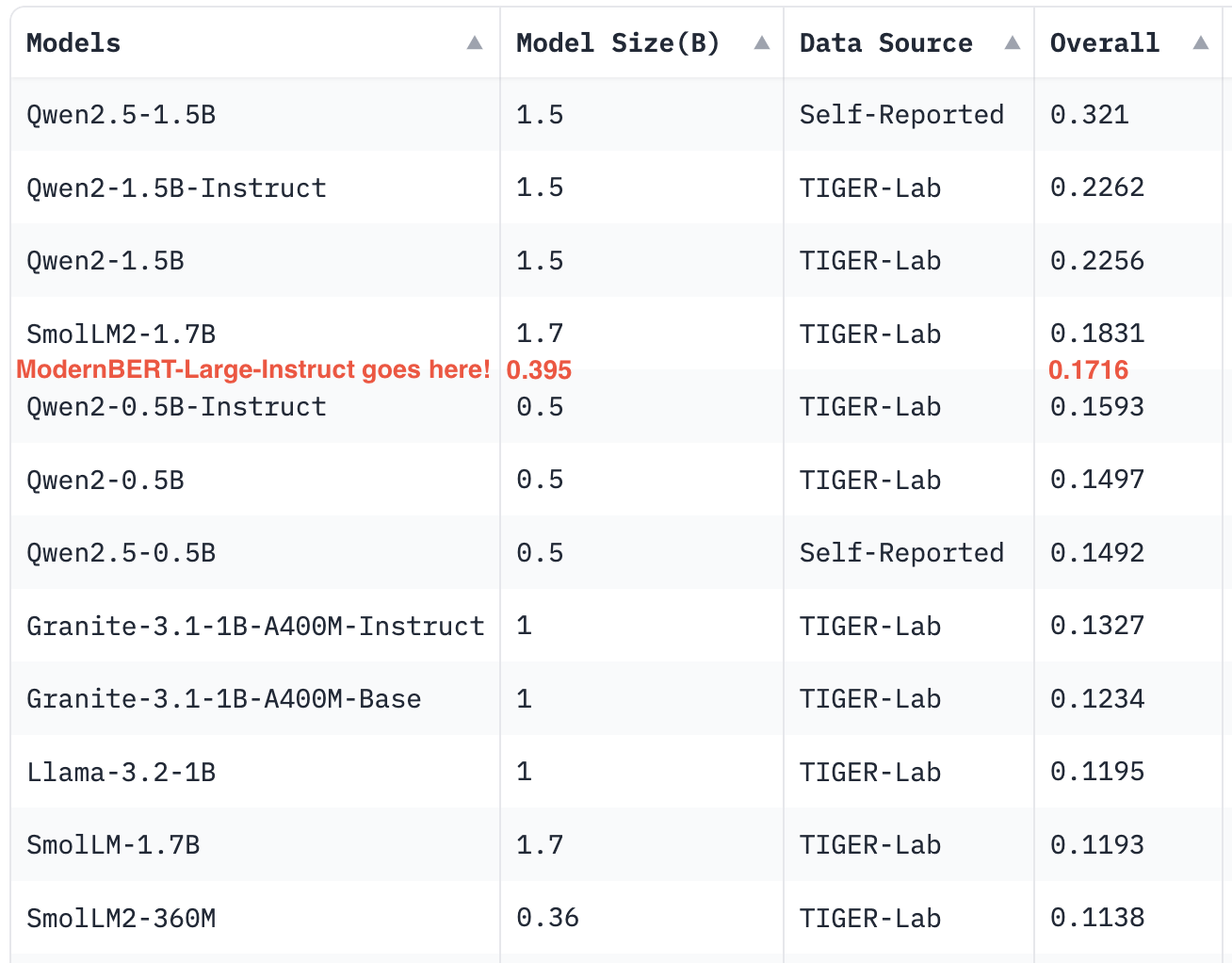
与最优秀者竞争(2B 以下型号的 MMLU-Pro 排行榜)
- 基于知识的多项选择题(MMLU 和 MMLU-Pro) :ModernBERT-Large-Instruct 在 MMLU 上的准确率达到43.06% ,击败了 SmoLLM2-360M (35.8%) 等类似大小的模型,并接近 Llama3-1B (45.83%)。在 MMLU-Pro 上,它的性能将使它在排行榜上占据非常好的位置,远远超过其重量级并与更大的法学硕士竞争!
- 分类:平均而言,它击败了之前所有的零样本方法。然而,在每个数据集的基础上情况并非如此:虽然这种方法具有强大的潜力并获得非常好的总体结果,但在某些数据集上它表现不佳,而在其他数据集上它表现优异。这表明该方法未来发展的巨大潜力。
微调结果
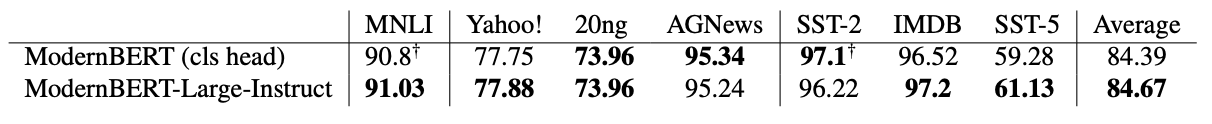
传销头就是您所需要的
在各种任务中,重点关注主题分类、文本蕴含 (MNLI) 和情感分析,对每个任务的 ModernBERT-Large-Instruct 进行微调似乎与传统的基于头的分类方法的性能相匹配。在某些数据集上,它甚至超越了它们!事实上,我认为这种方法是最终缩小最后一个差距并使 ModernBERT 成为比 DeBERTaV3 更好的分类器的关键。
这里需要注意的是,其中一些任务的训练集在我们的预训练组合中以相对较小的比例存在:然而,我们预计这种影响相当小,因为对多个时期进行的微调将这两种方法牢牢地带入“域内”领域。
现代性很重要

一个无耻的自我抄袭但合适的表情包
最后,我们想知道这种潜力是否是所有预训练的 MLM 编码器所固有的,或者是否是 ModernBERT 特有的。为了回答这个问题,我们对 RoBERTa-Large 等旧模型或具有现代架构但在较小规模、不太多样化的数据上进行训练的模型应用了相同的方法,并且性能显着下降:
| 模型 | MMLU |
|---|---|
| ModernBERT-大型指令 | 43.06 |
| GTE 大型传销 | 36.69 |
| 罗伯特·塔·拉格 | 33.11 |
这表明,鉴于 ModernBERT-Large-Instruct 和 GTE-en-MLM-Large 之间存在巨大的性能差距,MLM 编码器中强大的生成下游性能在很大程度上依赖于在足够大规模、多样化的数据混合上进行训练,GTE-en-MLM-Large 采用与 ModernBERT-Large 非常相似的架构(减去效率调整)。从 RoBERTa-Large 到 GTE-en-MLM-Large 的相对较小的性能增益似乎表明,虽然采用更好的架构确实发挥了作用,但它比训练数据的效果要小得多。
期待
虽然这些结果很有希望,但它们还处于早期阶段!他们真正所做的只是展示传销头作为多任务头的潜力,但他们还远远没有将其发挥到极限。除此之外:
- 探索更好、更多样化的模板
- 更深入地分析训练机制,以及虚拟例子的效果
- 在更新的指令数据集上进行测试,并具有更好的结构
- 研究小样本学习能力
- 缩放至更大的模型尺寸
- ……还有更多的事情!
所有这些都让我们对未来的工作非常有希望的方向!事实上,我们听说一些非常优秀的人已经在致力于其中的一些事情……
最终,我们相信这里提出的极其简单的方法的结果为编码器模型开辟了新的可能性。 ModernBERT-Large-Instruct 模型可在HuggingFace上找到。
原文: https://www.answer.ai/posts/2025-02-10-modernbert-instruct.html