我的shot-scraper CLI 工具的新版本,用于截取屏幕截图和抓取网页。
最大的新功能是HTTP Archive (HAR)支持。新的shot-scraper har 命令现在可以创建页面及其所有依赖项的存档,如下所示:
shot-scraper har https://datasette.io/
这会生成一个datasette-io.har文件(当前为 163KB),该文件是 JSON,表示用于呈现该页面的完整请求集。这是该文件的副本。您可以使用 ericduran.github.io/chromeHAR 在这里将其可视化。
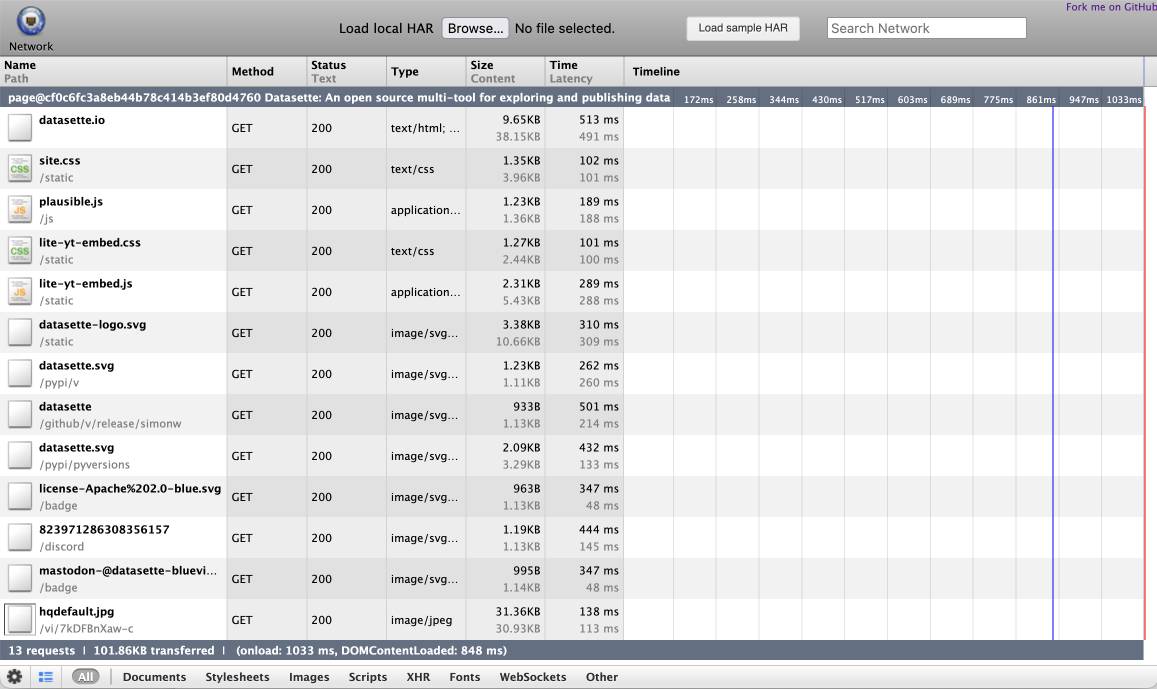
该 JSON 包含所有响应的完整副本,如果它们是图像等二进制文件,则进行 base64 编码。
您可以添加--zip标志来获取datasette-io.har.zip文件,其中包含har.har中的 JSON 数据,但响应正文另存为该存档中的单独文件。
shot-scraper multi命令允许您针对使用 YAML 文件指定的多个 URL 按顺序运行shot-scraper 。该命令现在采用--har选项(或--har-zip或--har-file name-of-file) ,如文档中所述,它将在截取屏幕截图的同时生成 HAR。
镜头通常在 YAML 中定义,如下所示:
-输出: example.com.png 网址:http: //www.example.com/ -输出: w3c.org.png 网址:https: //www.w3.org/
您现在可以省略output:键并生成 HAR 文件,而无需进行任何屏幕截图:
-网址:http: //www.example.com/ -网址:https: //www.w3.org/
像这样运行:
shot-scraper multi shots.yml --har
哪个输出:
Skipping screenshot of 'https://example.com/' Skipping screenshot of 'https://datasette.io/' Wrote to HAR file: trace.har
shot-scraper构建在 Playwright 之上,新功能使用browser.new_context(record_har_path=…)参数。
标签:项目, shot-scraper ,剧作家, python ,抓取
原文: https://simonwillison.net/2025/Feb/13/shot-scraper/#atom-everything