Tim Kellogg 在一篇新论文s1:简单的测试时间缩放中分享了他的笔记,该论文描述了一种在 Qwen2.5-32B-Instruct 之上进行微调的推理缩放模型,仅需 6 美元——在 16 个 NVIDIA H100 GPU 上运行 26 分钟的成本。
蒂姆强调了最令人兴奋的结果:
在将 56K 示例数据集筛选到最佳 1K 后,他们发现核心 1K 就足以在 32B 模型上实现 o1 预览性能。
该论文描述了一种称为“预算强制”的技术:
为了强制执行最小值,我们抑制思考结束标记分隔符的生成,并可选择将字符串“Wait”附加到模型的当前推理跟踪中,以鼓励模型反思其当前的生成
这与几周前Theia Vogel 所描述的一样。
这是Hugging Face 上的s1-32B模型。我在brittlewis12/s1-32B-GGUF找到了它的 GGUF 版本,我使用Ollama运行它,如下所示:
ollama run hf.co/brittlewis12/s1-32B-GGUF:Q4_0
我还在simplescaling/s1K数据存储库中的 Hugging Face 上找到了这 1,000 个样本。
我使用 DuckDB 将 parquet 文件转换为 CSV(并将一个VARCHAR[]列转换为 JSON):
COPY ( SELECT solution, question, cot_type, source_type, metadata, cot, json_array(thinking_trajectories) as thinking_trajectories, attempt FROM 's1k-00001.parquet' ) TO 'output.csv' (HEADER, DELIMITER ',');
然后我将该 CSV 加载到sqlite-utils中,以便我可以使用convert命令使用json.dumps()和eval()将 Python 数据结构转换为 JSON:
# Load into SQLite sqlite-utils insert s1k.db s1k output.csv --csv # Fix that column sqlite-utils convert s1k.db s1u metadata 'json.dumps(eval(value))' --import json # Dump that back out to CSV sqlite-utils rows s1k.db s1k --csv > s1k.csv
这是Gist 中的CSV,这意味着我可以将其加载到 Datasette Lite 中。
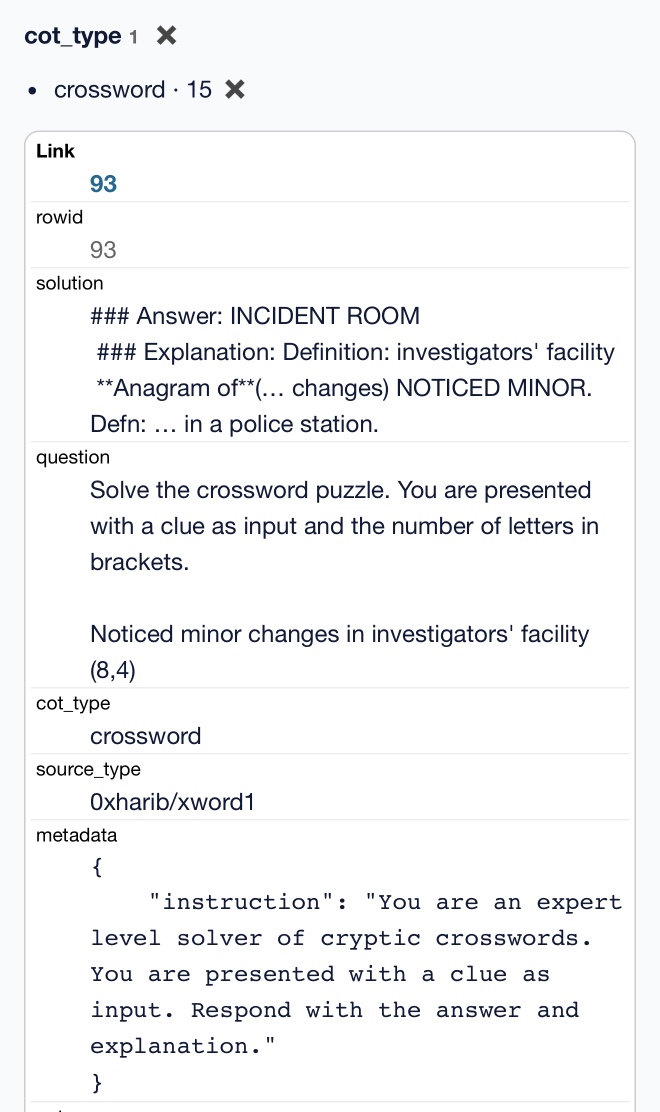
这确实是少量的训练数据。主要是数学和科学,但也有15 个神秘的填字游戏示例。
标签: duckdb , datasette-lite ,推理缩放, ai , ollama , llms , datasette ,生成人工智能, qwen
原文: https://simonwillison.net/2025/Feb/5/s1-the-6-r1-competitor/#atom-everything