
克里斯汀阿德森2022 年 12 月 6 日 – 凌晨 2:12
分箱是一种用于对数据值进行分类或查看数据分布的技术。它通常用于将连续数据减少为更易于管理的离散类别、通过聚合保护数据隐私、生成直方图或为有序色标创建中断。为图表或地图选择正确数量的 bin 通常被描述为一种权衡。 bin 太少,数据的细微差别,例如数据分布可能会丢失;太多的 bins 会导致直方图嘈杂,使形状信息难以恢复。
有多种方法可以分解数据,每种方法都可能给读者带来不同的视觉印象。选择最好的装箱方法通常是支持作者想要告诉他们的观众的故事或支持数据探索的方法。例如,下面的三张地图都显示了相同的基础数据:美国每个县的贫困人口百分比。
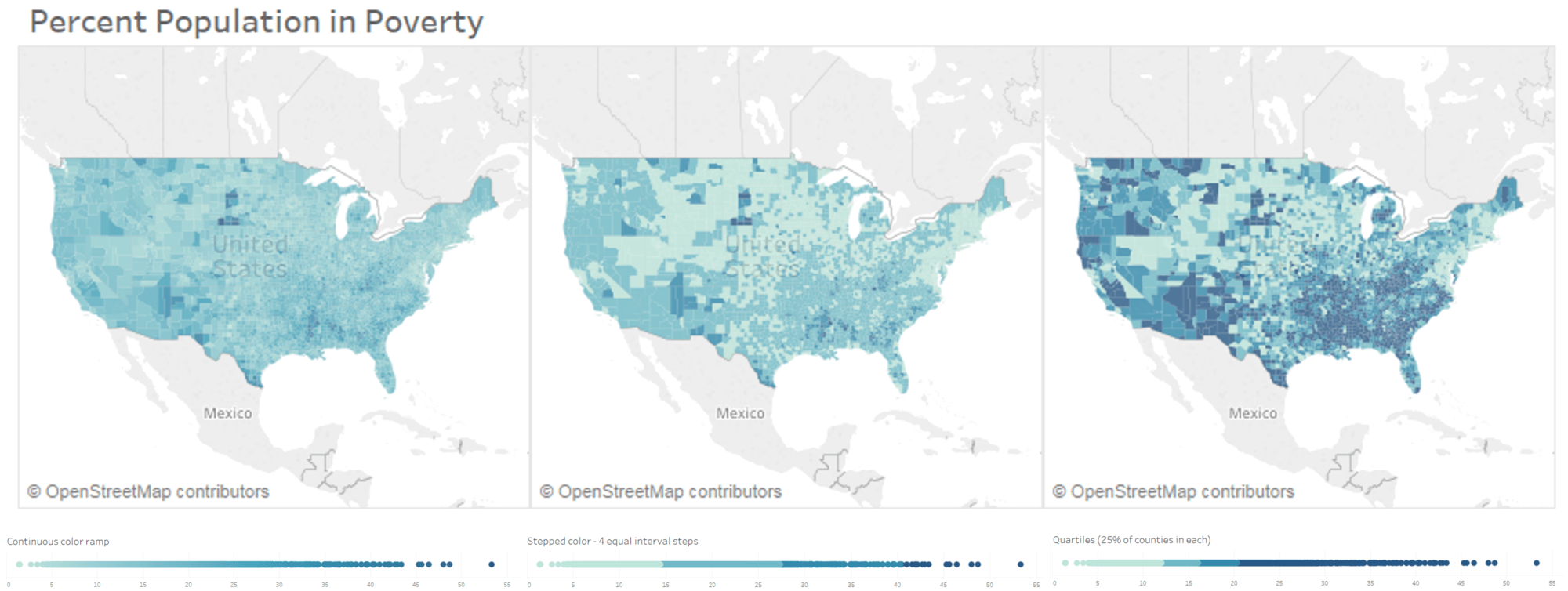
图 1. 不同的 bin 中断如何影响数据中感知的模式。
图 1 中的左侧地图显示了一个连续的色带,其中约 3000 个县中的每个县都由其数据值独有的阴影表示。中间的地图显示了由数字线上的相等间隔确定的四个 bin 分隔符。最后,在右边的地图上,我们有基于由四种颜色阴影表示的分位数的分箱,其中每种颜色代表大致相同数量的县。因此,正如我们在这里看到的,它是相同的基础数据,但可以对模式进行完全不同的解释。
虽然基于等间隔、分位数和 Jenks 自然中断分类等统计属性使用了各种分箱技术,但这些技术通常忽略了用于可视化的分箱方案最关键的属性:垃圾箱的易读性和语义连贯性。
使用调查和 Tableau Public 工作簿中的语义
我们的研究专门探讨了年龄、人口、薪水等已知的、通常定义的属性的语义如何用于在数据中创建有意义的中断。它的灵感来自 Tableau之前进行的一些颜色命名研究,该研究使用颜色名称及其对应颜色值的语义查找,自动为已知的可着色数据值(例如,水果、蔬菜、公司徽标)生成语义共鸣的调色板。
这篇博文讨论了一种称为 OSCAR 的新型分箱技术,这是一种以人为中心的分箱技术,它利用数据语义和易读性约束来建议用于直方图、地图和其他图表的定量数据的分箱。
以下是创建语义 bin 查找表的流程。

图 2:语义 bin 查找表的构建。
为了生成语义类别的查找,我们采用数据驱动的方法来挖掘调查问卷的公共语料库,其中包含对信息进行分类的问题,例如人口统计、健康和信息问题,例如“表明您的年龄组”或“您的年龄段是多少”薪水的范围?”。我们还在工作簿中包含包含分箱字段的Tableau Public可视化,作为分箱字段数据集的一部分。这个过程如图 2A 所示。
为了创建 bin 字符串及其关联的 bin 大小的查找,我们使用 Latent Dirichlet Allocation (LDA),这是一种流行的统计主题建模形式。在 LDA 中,文档表示为主题的混合,而主题是一堆单词。对于每个 bin 概念,我们有一个标签名称和一组相关概念,例如同义词,以及可能的 bin 中断集,如图 2B 所示。
推荐垃圾桶休息
现在,让我们来看一个示例,说明 OSCAR 如何为给定的数据属性(例如“passenger_age”)生成分箱,如图 3 所示。

图 3:语义装箱过程。
我们应用模糊匹配和词形还原来将属性与图 2 所示过程中生成的语义 bin 查找表中的 bin 概念“Age”匹配。如果匹配,则将这些 bin 应用于属性以生成直方图。
在没有语义箱的情况下,比如对于“numOfLiters”这样的属性,OSCAR 通过应用一些智能默认值来选择人类可读的箱来计算默认箱,如图 4 所示。为了生成默认箱,OSCAR 将箱数限制为可管理的大小(最多 20 个 bin)以避免过多的 bin(图 4a),舍入 bin 范围以避免不适当的 bin 精度(图 4b),并将 bin 范围舍入到适当的 5 或 10 次方以避免任意中断数据 (图 4c) 以创建图 4d 中所示的最终分箱方案。
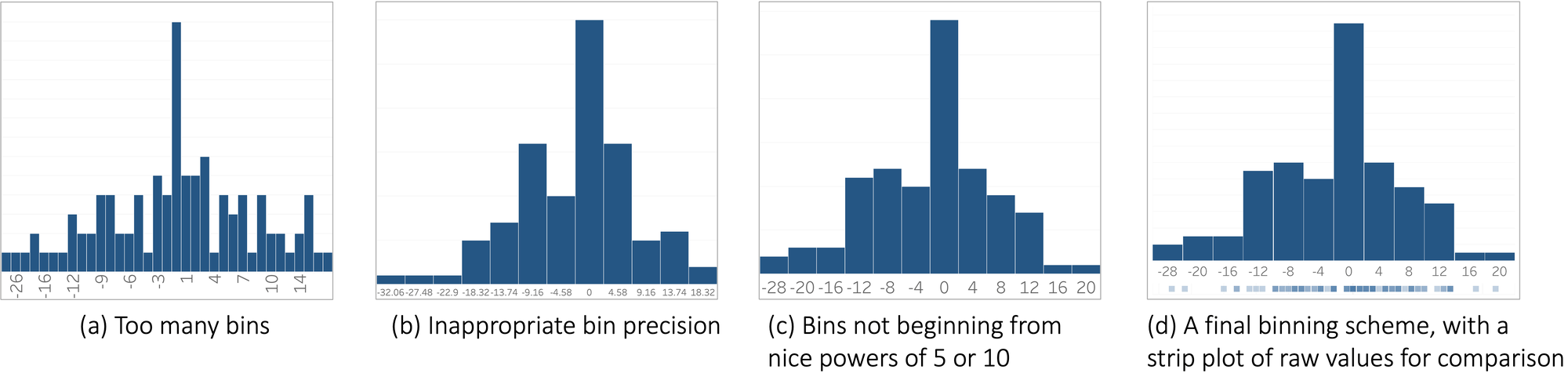
图 4. 默认装箱过程。
评估 OSCAR 生成的语义分箱发现参与者更喜欢语义分箱图表,因为休息感觉更熟悉和自然,并且更喜欢细粒度语义分箱而不是粗粒度语义分箱,这样他们可以更清楚地看到各种分箱中的值分布。我们设想将 OSCAR 用于可视化分析工具,其中可以为数值属性推荐 bin,并有机会修复和优化这些系统默认值。未来的工作应该着眼于在用户使用这些工具的分析工作流程中进一步评估 OSCAR 的语义箱质量。
最近在 IEEE 可视化会议上发表了一篇描述这项工作的论文,该论文基于Vidya Setlur 、 Michael Correll和Sarah Battersby的研究。
1 OSCAR 这个名字的灵感来自深受喜爱的芝麻街角色,他拥抱生活在垃圾桶里的生活。
原文: https://www.tableau.com/blog/oscar-creating-more-meaningful-bin-breaks