OpenAI 今天宣布了多项与音频相关的新 API 功能,适用于文本转语音和语音转文本。它们是非常有前途的新模型,但它们似乎始终存在意外(或恶意)指令遵循的风险。
gpt-4o-迷你-tts
gpt-4o-mini-tts是一种全新的文本转语音模型,具有“更好的可操控性”。 OpenAI 在OpenAI.fm上为此发布了一个令人愉快的新游乐场界面 – 您可以从 11 种基本声音中进行选择,应用诸如“高能量、古怪和稍微精神错乱”之类的指令,并让它读出脚本(括号中带有可选的额外舞台指示)。然后,它可以提供 Python、JavaScript 或curl 中的等效 API 代码。您可以分享您的实验链接,这是一个示例。
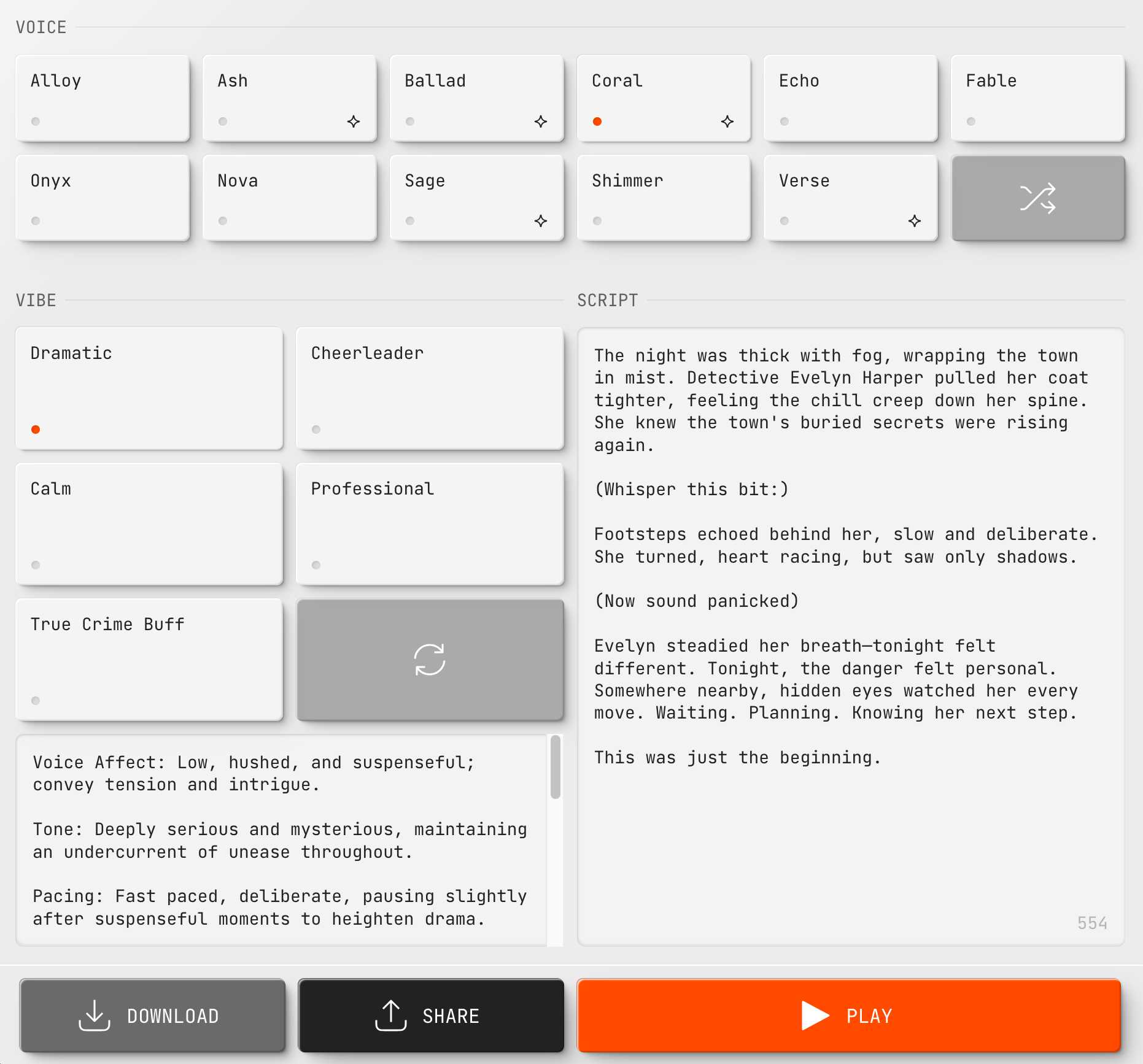
请注意我的脚本的一部分如下所示:
(小声说一下:)
脚步声在她身后响起,缓慢而从容。她转过身,心跳加速,但只看到了影子。
虽然有趣且方便,但您可以在脚本本身中插入阶段方向这一事实对我来说感觉像是一种反模式 – 这意味着您不能安全地将其用于任意文本,因为存在某些文本可能意外被视为对模型的进一步说明的风险。
在我自己的实验中,我已经看到这种情况发生:有时模型正确地遵循我的“耳语这个位”指令,有时它会大声说出“耳语”这个词,但不会说出“这个位”这个词。结果看起来是不确定的,并且也可能随着不同的基本声音而变化。
gpt-4o-mini-tts的成本为0.60 美元/百万代币,OpenAI 估计约为每分钟 1.5 美分。
gpt-4o-转录和 gpt-4o-mini-转录
gpt-4o-transcribe和gpt-4o-mini-transcribe是两种新的语音转文本模型,其用途与Whisper类似,但建立在 GPT-4o 之上,并设置了“新的最先进基准”。这些可以通过 OpenAI 的v1/audio/transcriptions API使用,作为“whisper-1”的替代选项。 API 仍仅限于 25MB 音频文件(MP3、WAV 或几种其他格式)。
每当基于 LLM 的模型用于音频转录(或 OCR)时,我都会担心意外的指令遵循 – 是否存在看起来像口头或扫描文本中的指令的内容可能不包含在结果转录中的风险?
OpenAI 的 Jeff Harris 在Hacker News 的评论中谈到了这些新模型与gpt-4o-audio-preview的不同之处:
这是一个稍微好一点的 TTS 模型。通过额外的培训,重点是完全按照书面内容阅读剧本。
例如,当指示音频预览模型说“意大利的首都是什么”时,它通常会说“罗马”。这个模型在这方面应该要好得多
在我看来,“在这方面好多了”听起来仍然存在发生这种情况的风险,因此对于某些敏感应用程序,坚持使用耳语或其他传统的文本到语音方法可能是有意义的。
是的,转录保真度是将音频模型转换为 TTS 模型的一大工作。仍然有可能,但应该很少见
gpt-4o-transcribe估计为每分钟 0.6 美分, gpt-4o-mini-transcribe为每分钟 0.3 美分。
混合数据和指令仍然是法学硕士的主要罪过
如果您看起来很熟悉这些问题,那是因为它们是提示注入背后根本原因的变体。 LLM 架构鼓励在同一令牌流中混合指令和数据,但这意味着始终存在来自数据的令牌(通常来自不受信任的来源)可能被误解为模型指令的风险。
这对这些新模型的实用性有多大影响还有待观察。也许新的训练是如此强大,以至于这些问题实际上不会给现实世界的应用程序带来问题?
我仍然持怀疑态度。我预计我们会在相对较短的时间内看到这些缺陷的演示。
标签:音频、文本转语音、人工智能、 openai 、提示注入、生成人工智能、耳语、 LLMS 、多模式输出
原文: https://simonwillison.net/2025/Mar/20/new-openai-audio-models/#atom-everything