以前在这个系列中:
N=1:简介
历史
单一主题或单一案例研究设计至少可以追溯到 1980 年代——尽管从稀疏的维基百科页面可以看出,它们并没有得到太多关注。虽然单一主题研究的想法很好,但执行往往很糟糕。
最简单的单一受试者设计是“ABA”设计,您有几天的控制日(“A”)、几天的治疗(“B”),然后您回到控制日(“A”) ).例如,参见康涅狄格大学的这张图:
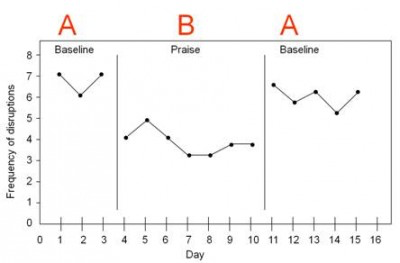
在这种情况下,我们可以看到“中断频率”(来自目标学生)在第一个基线 A 块中很高,在 B 块中下降了一段时间(“表扬”),然后在他们切换时又上升了回到A。
ABA 设计聊胜于无。它比案例研究更好,因为至少有一些实验控制。但它并没有给我们提供那么多信息。当然,他们有 15 天的数据,但只有三个阶段。这实际上更像是三个样本量(并不是说 15 个样本量更有说服力)。
一些消息来源可能会推荐更高级的 ABAB 方法……

……但是 ABAB 也不是那么令人信服。这是“积极关注”时期的变化,还是只是随机游走?这很难说。
ABA 方法是塞思·罗伯茨 (Seth Roberts) 用来证明他的“黄油思维”协议有效的方法,即多吃黄油让他更聪明。从他的一项自我实验中看一下这张 ABA 图表:
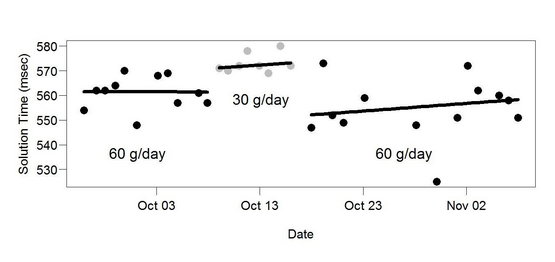
同样,这充其量是模糊的。是的,他用 30 克/天的黄油比用 60 克/天的黄油做算术题的时间更长。但变化不是很明显,三个时期明显重叠,不清楚时期是否随机确定等。最重要的是,样本量不是很大——我们可以做得更好,而不是从一个仅仅三个间隔。
你不应该完全忽视这些简单的设计。从这里开始可能很好(例如,参见Allan Neuringer 的自我实验)。简单很重要,如果您正在进行早期探索性工作,那么采用简单的研究设计具有明显的好处。如果您没有发现这种简单方法有任何区别,则可以继续进行其他操作。如果您在 ABA 中确实看到了差异,并且您想以更有说服力的方式证明这种差异,那么您可以将其扩展为真正的学科内研究。
Seth 的黄油 ABA 没有错——只是它看起来像是某件事的开始,而不是结论。如果他真的想说服人们,他应该把它分解成一个更长时间的自我实验。
被试内法
艾米丽是一名 20 多岁的女性,经常患偏头痛。她通常在午后偏头痛发作,而且几乎每天都会发生。艾米丽长期以来一直在追踪她的偏头痛,并确定每天下午 2:00 左右偏头痛发作的可能性为 80%,这会毁了她下午剩下的时间。
艾米丽最近注意到,如果她早上服用 400 毫克镁,那么她当天下午患偏头痛的可能性就会大大降低。这不是一件确定的事情——她在服用镁的日子里仍然会偏头痛——但它似乎不到 80%。
让 Emily 获得对这一假设的一些支持的一种方法是让她进行一个简单的 AB 自我实验。她可以连续两周不服用镁,然后连续两周每天早上服用 400 毫克镁,看看这对她的偏头痛是否有影响。如果她在没有服用镁的几周内有 80% 的时间偏头痛,而在她服用 400 毫克镁的几周内只有 40% 的时间偏头痛,这似乎是镁有帮助的证据。
它是证据,但它在弱的一面。取决于你如何切分它,这里的有效样本量是两个——一个两周有镁,一个两周没有。你不应该在这里得出强有力的结论,就像你不应该从实验组中的一个人和对照组中的一个人的研究中得出强有力的结论一样。只是没有那么多证据。
样本量小,可供选择的解释太多,很容易自欺欺人。也许她在春天开始服用镁,日光的增加是她的偏头痛得到改善的真正原因。或者她两个月前刚开始一份新工作,她花了两个月的时间才停止磨牙,这恰好与改用镁有关。或者她的洗涤剂制造商转向了一家新的香水供应商。或者她对邮递员的猫过敏,上周它跑了。它几乎可以是任何东西。
为了解决这些问题,Emily 可以继续获取更大的样本量。她可以使用随机数生成器随机分配服用镁或不服用镁的日期,然后按照随机分配进行操作。
通过添加这两个小步骤,她现在可以使用正常的受试者内实验方法。假设她发现在不服用镁的日子里有 80% 的几率患偏头痛,而在服用 400 毫克镁的日子里患偏头痛的几率为 30%。她可以以任意精度证明这种差异,只需运行更多天的试验。
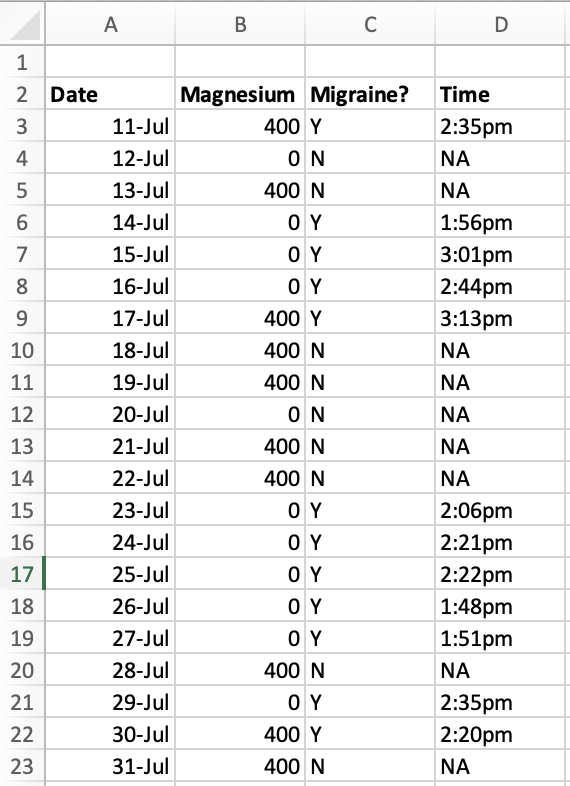 Emily 的数据可能看起来像这样。此处显示的数据还不足以达到统计显着性(χ2 给出 p = .051),但对于 30% 的镁偏头痛几率和 80% 的镁不偏头痛几率来说,这看起来相当不错。
Emily 的数据可能看起来像这样。此处显示的数据还不足以达到统计显着性(χ2 给出 p = .051),但对于 30% 的镁偏头痛几率和 80% 的镁不偏头痛几率来说,这看起来相当不错。即使差异要微妙得多——服用 400 毫克镁可能有 75% 的几率出现偏头痛,而没有摄入镁则有 80% 的几率——如果有足够的天数,她仍然可以任意自信地证明镁对她有观察到的效果,尽管这种影响可能很小。
这不会提供任何证据表明镁对任何其他人的偏头痛都有效。但即使它根本不能推广到其他任何人,艾米丽也可以得到尽可能多的证据,证明它确实在为她做点什么。这仍然对社区有帮助,因为它表明治疗至少有时对某些人有效。
这与传统的案例研究不同。即使它只看一个人,它也使用实验技术。与传统实验相比,你牺牲了外部有效性(这会推广到除了这个人以外的任何人吗?)但你仍然获得相同水平的统计严谨性,你仍然可以清楚地推断因果关系。
通过这种设计,您应该能够使用标准的受试者内统计方法。即使对于受试者内研究,只有一个样本量也是不寻常的,但并非完全闻所未闻。
这种方法在互联网研究社区中未得到充分利用(尽管 Scott Alexander 在这里做了一个,Gwern用 LSD 做了一个)。许多人在网上分享他们认为可能有助于反流/偏头痛/IBS/心悸/执行功能/等的事情的提示和技巧。这很好,但很难知道哪些建议是可靠的,哪些只是随机的。
如果你进行受试者内的自我实验,你可以为你的社区做一些不可思议的事情。它可能无法帮助所有人,但您可以证明它是否适合您。也发布你的无效结果——如果你怀疑咖啡因会引发你的反流,但在仔细检查后这个假设不成立,报告那个狗屎!
我们应该强调,N = 1 项研究证伪了一种非常特殊的无效假设:干预无效。如果干预对您有效,则表明该干预有效。
它可能对其他任何人都不起作用,并且在 N = 1 的情况下,您更有可能做一些特殊的事情,使干预看起来成功,而实际上是特殊的事情完成了所有工作。例如,也许在你服用镁的日子里,你总是和一大杯柠檬水一起服用。事实证明是柠檬水而不是镁对您的症状有帮助,这从数据中看不出来,因为柠檬水和镁是混杂的。
如果你想超越自我,你可以找几个朋友,只用几个人做一个更有说服力的测试。只要你们都做多次试验,从统计学的角度来看,你们的有效样本量仍然可以任意大。随着更多的人,我们更加确定没有什么奇怪的东西与实验变量混淆(但永远不会 100%)。每个慢性病 subreddit 都应该产生 2-10 人的研究小组,并测试他们认为值得研究的治疗方法。
限制
然而,即使有更好的随机化,这些设计仍然有很多局限性。
首先,它们受到研究周期速度的限制。例如,重复测量研究对研究肥胖症效果不佳,因为人们减肥和增重的速度往往非常缓慢。减肥和恢复体重可能需要数月时间,因此很难用这种方法研究体重增加情况。如果你必须随机化几个月的时间段,你将需要一整年的时间才能获得 12 个样本。相比之下,头痛会更容易研究,因为它们每天甚至每小时来来去去,你可以随机化你的治疗在更短的时间尺度上。
更糟糕的是,对于某些治疗,我们不知道合适的时间表是什么。让我们回到艾米丽和她的偏头痛。如果镁按周而不是天的顺序工作,她将不得不随机分配周而不是天,这意味着需要七倍的时间才能达到同等的样本量。但是她怎么能提前知道是使用几天还是几周呢?
如果一种治疗方法太强大,或者效果持久,那实际上会使研究变得更加困难。如果镁可以治愈 Emily 的偏头痛一个月,她将不得不在随机化周期之间等待一个月,而她将需要数年时间才能获得合适的样本量。
同样,这种协议可能无法检测到更复杂的关系。如果 Emily 的身体随着时间的推移积累了额外的镁,这可能很难建模并且可能会影响实验的清晰度。或者,如果她的身体更积极地从她的系统中清除多余的镁,那么随着时间的推移,镁的影响会越来越小,并且在她一个接一个地使用多个镁块的试运行中效果会更小。这些设计可以提供很多东西,但面对真正复杂的问题,它们不会让我们走得太远。
这种方法的另一个缺点是 Emily 已经找到了她喜欢的治疗方法。可能她想每天服用镁并尽可能少患偏头痛,但要进行此受试者内部自我实验,她必须在几个月的过程中多次尝试停用镁,以确保它确实有效作品。我们认为确定地知道通常是值得的,但要停止似乎有效的治疗并不容易。
最后,最大的限制是,只有在您已经确定了一种您怀疑可能对您有用的治疗方法时,您才能使用这种方法。如果您生病了并且没有任何线索,则此方法无法帮助您弄清楚要尝试什么。它只适用于测试或确认假设——它不能给你任何新的假设,不能缩小治疗范围或从可能使你生病的大量事物中触发。
原文: https://slimemoldtimemold.com/2023/01/19/n1-single-subject-research/