我一直在构建一个小型命令行工具套件,用于在未来使用 ChatGPT、GPT-4 和其他可能的语言模型。
到目前为止,我构建的三个工具是:
- llm – 用于向 OpenAI API 发送提示、输出响应并将结果记录到 SQLite 数据库的命令行工具。我几周前介绍过。
- ttok – 基于标记的文本计数和截断工具
- strip-tags – 一种从文本中剥离 HTML 标签的工具,并可选择根据 CSS 选择器输出页面的子集
这些工具的想法是支持使用 Unix 管道处理语言模型提示。
您可以像这样安装三个:
pipx 安装 llm pipx 安装 ttok pipx 安装 strip-tags
如果您还没有采用pipx ,也可以使用pip 。
llm取决于OPENAI_API_KEY环境变量或~/.openai-api-key.txt文本文件中的 OpenAI API 密钥。其他工具不需要任何配置。
现在让我们用它们来总结纽约时报的主页:
curl -s https://www.nytimes.com/ \ |条标签 .story-wrapper \ | ttok-t 4000 \ | llm --system '摘要要点' -s
以下是您在终端中运行该命令时的输出:
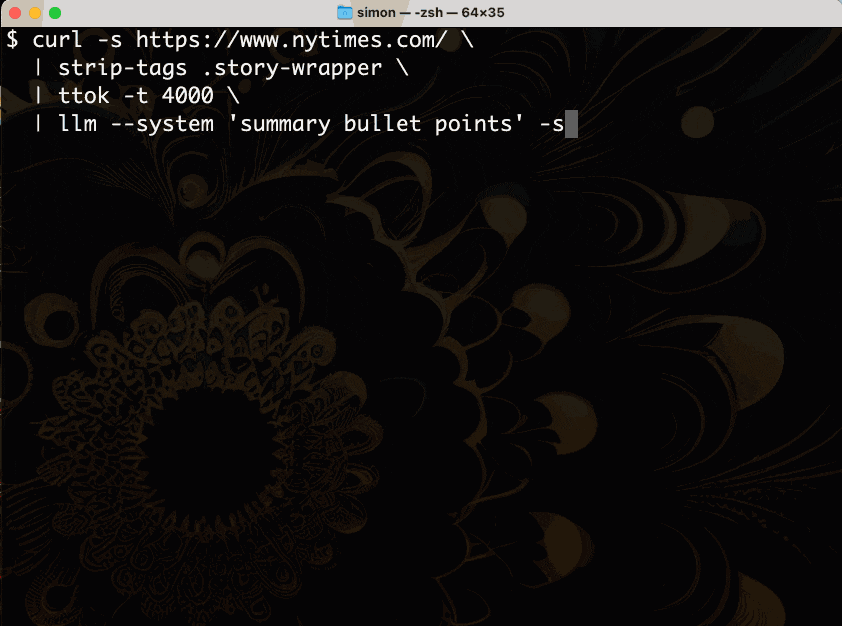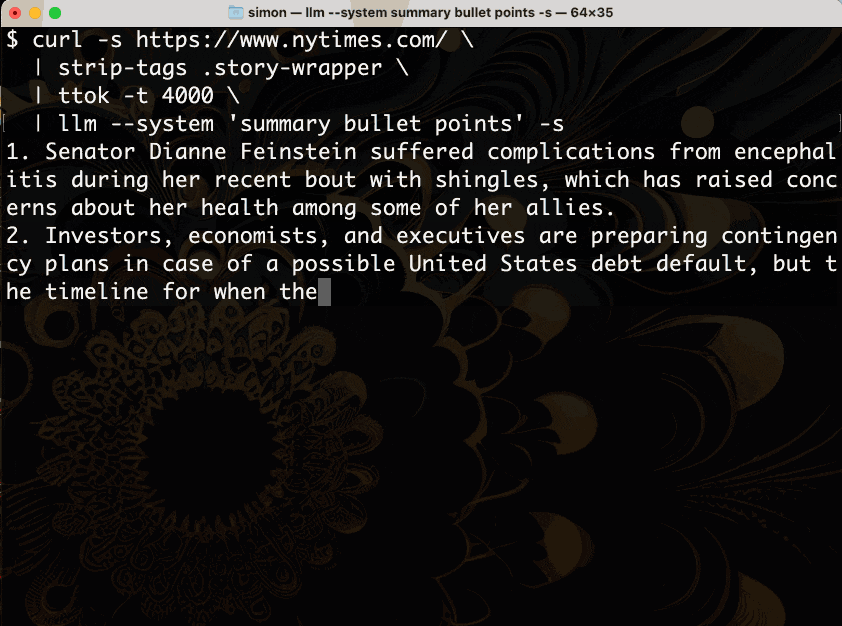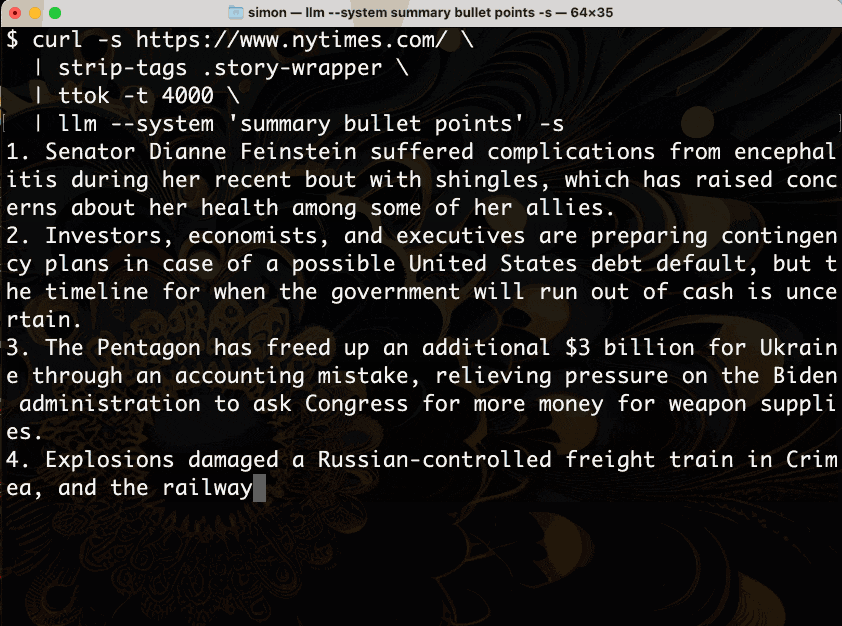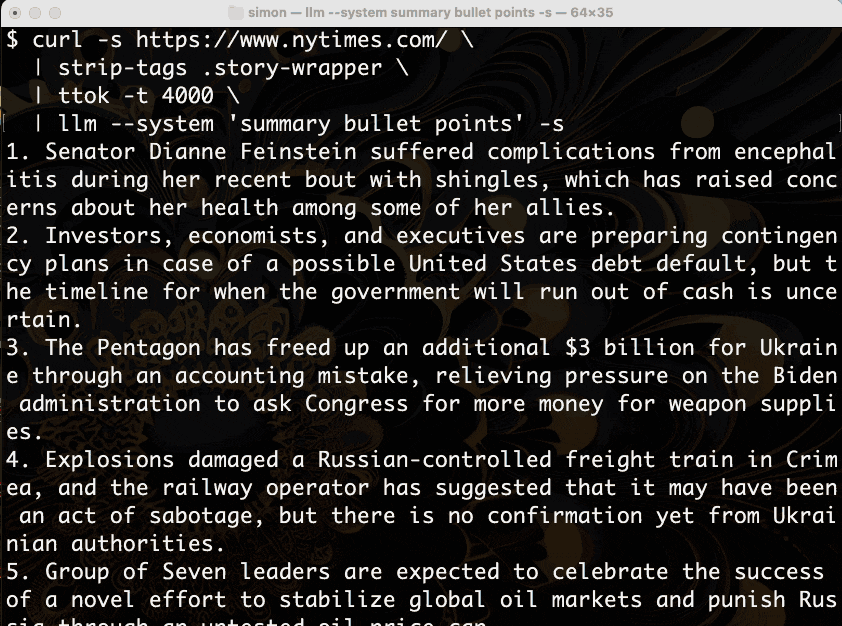
让我们分解一下。
-
curl -s https://www.nytimes.com/使用curl检索纽约时报主页的 HTML –-s选项阻止它输出任何进度信息。 -
strip-tags .story-wrapper接受 HTML 到标准输入,仅查找由 CSS 选择器.story-wrapper标识的页面区域,然后输出这些区域的文本并删除所有 HTML 标记。 -
ttok -t 4000接受文本到标准输入,使用gpt-3.5-turbo模型的默认分词器对其进行分词,截断前 4,000 个分词并将这些分词转换回文本输出。 -
llm --system 'summary bullet points' -s接受标准输入的文本作为用户提示,添加“summary bullet points”的系统提示,然后-s选项告诉工具将结果流式传输到终端返回,而不是在输出任何内容之前等待完整的响应。
一切都与代币有关
我今天早上构建了strip-tags和ttok ,因为我需要更好的方法来处理标记。
ChatGPT 和 GPT-4 等 LLM 使用令牌,而不是字符。
这是一个实现细节,但它们是您无法避免的,原因有二:
- API 有令牌限制。如果您尝试发送超过限制,您将收到如下错误消息:“此模型的最大上下文长度为 4097 个令牌。但是,您的消息产生了 116142 个令牌。请减少消息的长度。”
- 代币是定价的方式。
gpt-3.5-turbo(ChatGPT 使用的模型,以及llm命令使用的默认模型)花费 0.002 美元/1,000 个代币。 GPT-4 的输入为 0.03 美元/1,000 美元,输出为 0.06 美元/1,000 美元。
能够跟踪令牌计数非常重要。
但是代币其实真的很难统计!经验法则是大约 0.75 * 字数,但您可以通过运行模型在您自己的机器上使用的相同分词器来获得准确的计数。
OpenAI 的tiktoken库(记录在本笔记本中)是执行此操作的最佳方式。
我的ttok工具是该库的一个非常薄的包装器。它可以做三件不同的事情:
- 计数令牌
- 将文本截断为所需数量的标记
- 给你看代币
这是一个简单的例子,展示了所有这三个在行动:
$ echo '这是一些文本' | ttok 5个 $ echo '这是一些文本' | ttok——截断2 这是 $ echo '这是一些文本' | ttok--令牌 8586 374 1063 1495 198
我的GPT-3 令牌编码器和解码器Observable notebook 提供了一个界面,用于更详细地探索这些令牌的工作原理。
从 HTML 中剥离标签
HTML 标签占用大量标记,通常与您发送给模型的提示无关。
我的新strip-tags命令去除了这些标签。
这是一个示例,显示了可以产生多大的不同:
$ curl -s https://simonwillison.net/ | ttok 21543 $ curl -s https://simonwillison.net/ |条形标签| ttok 9688
对于我的博客主页,剥离标签减少了一半以上的标记数!
上面的令牌仍然太多,无法发送到 API。
我们可以像这样截断它们:
$ curl -s https://simonwillison.net/ \ |条形标签| ttok——截断 4000 \ | llm --system '把它变成一首糟糕的诗' -s
哪些输出:
download-esm, A tool to download ECMAScript modules. Get your packages straight from CDN, No need for build scripts, let that burden end. All dependencies will be fetched, Import statements will be re-writched. Works like a charm, simple and sleek, JavaScript just got a whole lot more chic.
但通常我们只关心页面的特定部分。 strip-tags命令将一个可选的 CSS 选择器列表作为参数——如果提供,则只会输出页面的那些部分。
这就是上面纽约时报示例的工作原理。比较以下内容:
$ curl -s https://www.nytimes.com/ | ttok 210544 $ curl -s https://www.nytimes.com/ |条形标签| ttok 115117 $ curl -s https://www.nytimes.com/ |条标签.story-wrapper | ttok 2165
通过仅选择<section class="story-wrapper">元素中的文本,我们可以将整个页面缩减为页面上每篇主要文章的标题和摘要。
未来的计划
我真的很享受能够使用终端以这种方式与 LLM 进行交互。拥有一种将内容通过管道传输到模型的快速方法会带来各种有趣的机会。
想要快速解释一些代码如何使用 GPT-4 工作?尝试这个:
cat ttok/cli.py | llm --system 'Explain this code' -s --gpt4
(此处输出)。
我也一直很享受将我的shot-scraper 工具通过管道传输到其中,这比strip-tags在提供完整的无头浏览器方面更进了一步。
下面是一个示例,它使用此 TIL 中的可读性配方来提取文章的主要内容,然后进一步从中剥离 HTML 标签并将其通过管道传输到llm命令中:
shot-scraper javascript https://www.theguardian.com/uk-news/2023/may/18/rmt-to-hold-rail-strike-across-england-on-eve-of-fa-cup-final “ 异步()=> { const readability = await import('https://cdn.skypack.dev/@mozilla/readability'); return (new readability.Readability(document)).parse().content; } " | strip-tags | llm --system summarize
就后续步骤而言,我最兴奋的事情是教llm命令如何与其他模型通信——最初是通过 API 与 Claude 和 PaLM2 通信,但我希望它能与运行在诸如还有llama.cpp 。
原文: http://simonwillison.net/2023/May/18/cli-tools-for-llms/#atom-everything