深度搜索。
现在法学硕士领域的每个人都知道这个名字,并且有充分的理由;经过一年多的时间,他们的团队在架构、工程和数据工作上悄悄迭代,他们终于在最新的预训练运行 (DeepSeek-V3) 之后发布了 DeepSeek r1,赶上了[并在某些方面超越]了前沿。
当 OpenAI 发布第一个检查点时,他们有足够的信心将其称为“推理模型”(o1-预览版),人们纷纷猜测是哪些训练进步导致了所观察到的性能提升。几个月来,学术界没有人真正公开复制过这个级别的东西。直到r1到达。
那么他们是怎么做到的呢?
一些人推测,这里的进步来自于在机器学习方面已在其他环境中取得成功的算法的集成,例如蒙特卡罗树搜索,或涉及过程奖励建模的方案,其中每个步骤都单独奖励。
事实证明,所有这些银河大脑计划都被一个明确的答案打败了;
实际上,应用于可验证目标的在线强化学习的任何合理变体。
虽然大多数前沿实验室(大概)仍在使用 PPO 进行在线强化学习,但 DeepSeek 开发的技术从纯粹学习的角度来看可以说是完全劣质的;但这并不重要的原因是,两种方法之间优化的核心原理本质上是相同的。
事实证明,与仅对现有数据进行微调并希望获得最佳结果相比,明确奖励您正在寻找的标准的自定义强化学习目标对于为任务奠定坚实的基础更为重要。但对于我们要优化的目标而言,PPO 算法的某些元素比其他元素更重要。
PPO 和 GRPO 的真正区别关键在于:
-
GRPO 通过根据样本对奖励的贡献程度来衡量样本,从而避免了使用价值模型来估计样本的“有用性”(优势)(在优化目标时)相关的复杂性。
-
当谈到这里的数学时,我不会过多地讨论这里的数学,因为这让我厌烦得要死,但这个设置的重要一点是,由于你已经在在线强化学习设置中对每个训练样本进行了多代,你可以使用这些样本的自然变异性来估计你的优势,只需将它们相互比较即可。
也就是说,如果第 1 代的奖励为 0.5,第 2、3 和 4 代的奖励为 0.1,那么您希望比其他代更倾向于产生第 1 代的概率,并且通过以相对方式迭代地执行此操作,您可以自然地通过始终偏爱最接近提高所需奖励的样本来爬升所需的指标。
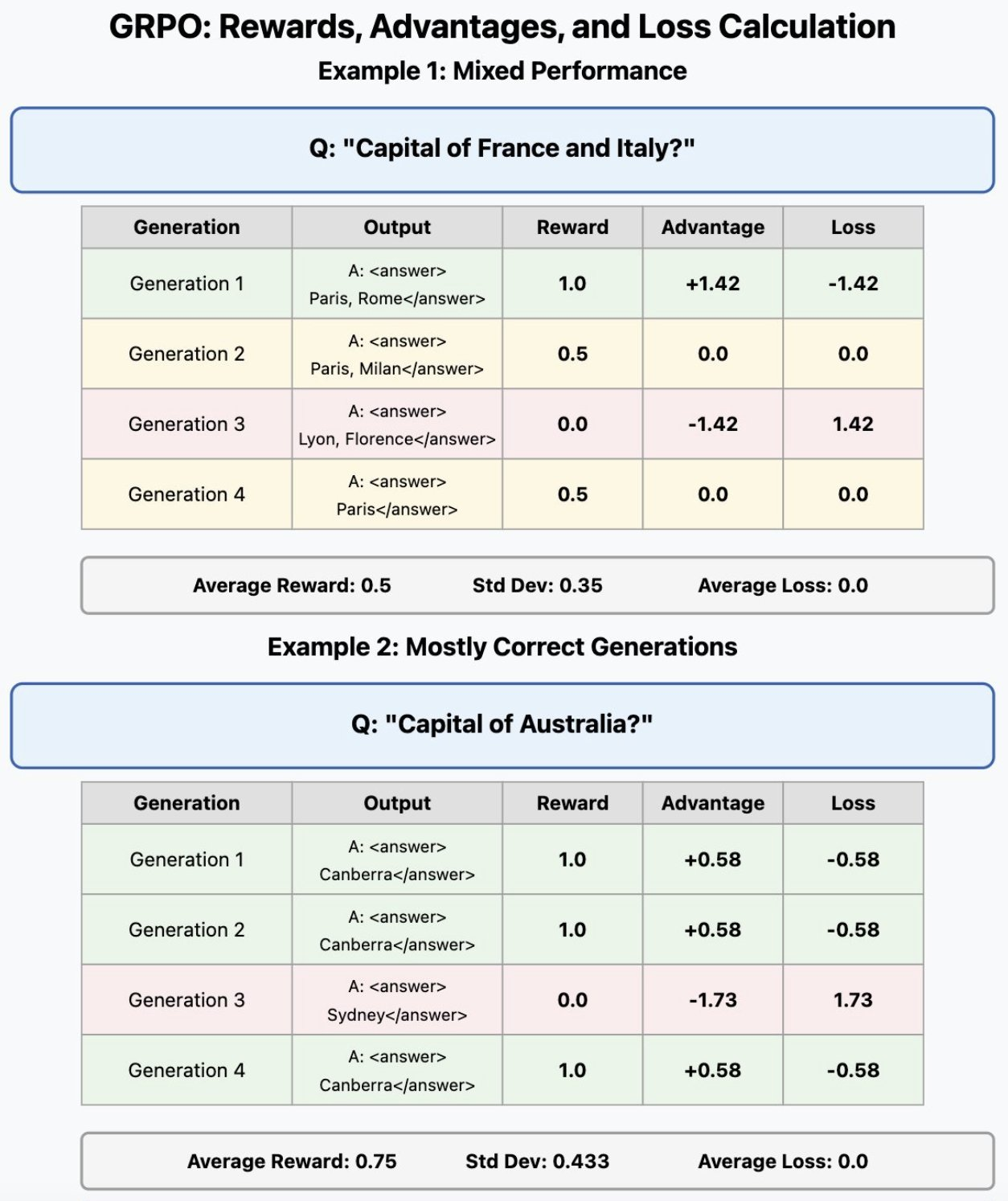 这里最需要观察的是如何相对于组中其他尝试的表现来计算优势。
这里最需要观察的是如何相对于组中其他尝试的表现来计算优势。
每代的优势计算如下:
advantage = (reward - mean) / stddev
DPO Delenda Est,或:痛苦的教训
在 r1 发布前一年左右,开源界痴迷于“DPO”(直接偏好优化)的想法,它完全避开了强化学习的“在线”性质,试图在给定预先存在的数据集的情况下最大化“选择”和“拒绝”数据之间的距离。
也就是说,DPO 不是生成响应并迭代改进它们,而是在离线数据集上进行训练,并最大化所选响应对和拒绝响应对之间的概率距离。
我认为,这似乎阻碍了一些非常琐碎的实验,这些实验本可以在开源领域进行,以使在线 RL 更便宜,就像 DeepSeek 以 GRPO 作为算法所展示的那样,并且坦率地说,我不认为 DPO 作为一个想法能够长期实现。
那么,为什么 DPO 不起作用(对于 GRPO 擅长处理的问题)?好吧,如果你仔细想想,它本质上是另一个代理目标的代理目标;这就是偏好奖励模型,它们是经过训练的分类器,用于预测响应被“偏好”的机会与“不受欢迎”的机会相比(Bradley-Terry 模型)。
我们不能直接“训练”“真实”的人类偏好,因为人们更喜欢什么或主观上平均认为更好的东西通常并不取决于可验证或可测量的因素;因此,我们使用奖励模型作为代理,根据人类注释的偏好数据来确定更喜欢什么。
当你从等式中删除偏好模型时,你本质上只是最大化了已经可能发生的事情与不太可能发生的事情之间的差异;因此,像 DPO 这样的方法永远无法从基本模型中进行泛化,也永远无法学习首选的“真实分布”。因此,DPO 被认为是 RL 的“离线”版本;该模型不是学习“即时”迭代地产生更好的结果,而是获得规定的预先打包的预测,这些预测甚至可能与模型一开始倾向于产生的结果自然不相符。
事实上,当所使用的选择/拒绝的数据与模型实际生成的数据相差太远时,可能会导致性能下降和灾难性遗忘。
更糟糕的是,模型“输出”的内容在整个训练过程中总是会发生变化,因此,与以在线方式训练模型相比,即使根据偏好模型或分类器预先收集您选择和拒绝的数据,也会导致训练模型实际产生的内容“过时”。
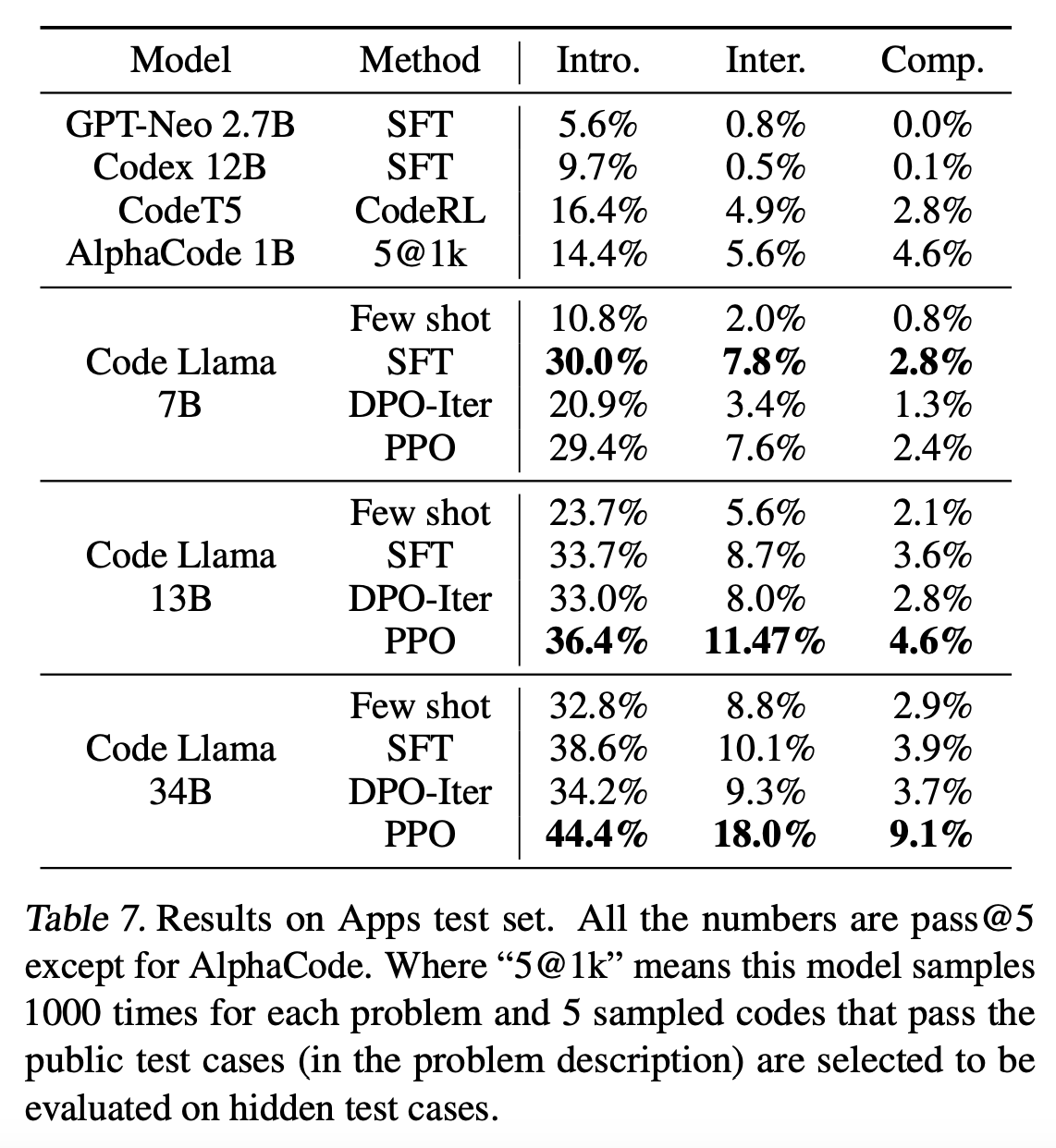 呜呜呜! (有关 DPO 与 PPO 等在线 RL 方法的更严格分析,请参阅Duan 等人 (2024))
呜呜呜! (有关 DPO 与 PPO 等在线 RL 方法的更严格分析,请参阅Duan 等人 (2024))
(设计)哲学差异
这引起的另一个(非技术)问题是一个隐含的假设,即针对偏好进行优化比针对基于结果的目标进行优化更重要;这是唯一重要的方法。事实上,我认为强化学习对于语言模型的效用并不是受到技术限制,而是受到期望的限制。
在线强化学习最有用的一点是,当你正确地大规模应用于这些模型时,它会变得如此强大,令人难以置信,那就是你不必在“优化更准确的令牌预测”的空间中进行操作。
为什么?
出色地。
当谈到你在在线强化学习中选择的奖励指标时。
– 如果你能准确地测量它,
– 该模型已经能够在某种程度上实现这一目标,
– 至少在某些时候…
…那么你基本上就有了某种“软保证”,你将能够在最大化它的方向上迭代优化。
当然,你必须遵守该指标的内在限制(参见奖励游戏的存在),但如果你有一个保证始终正确的指标,例如数学准确性……
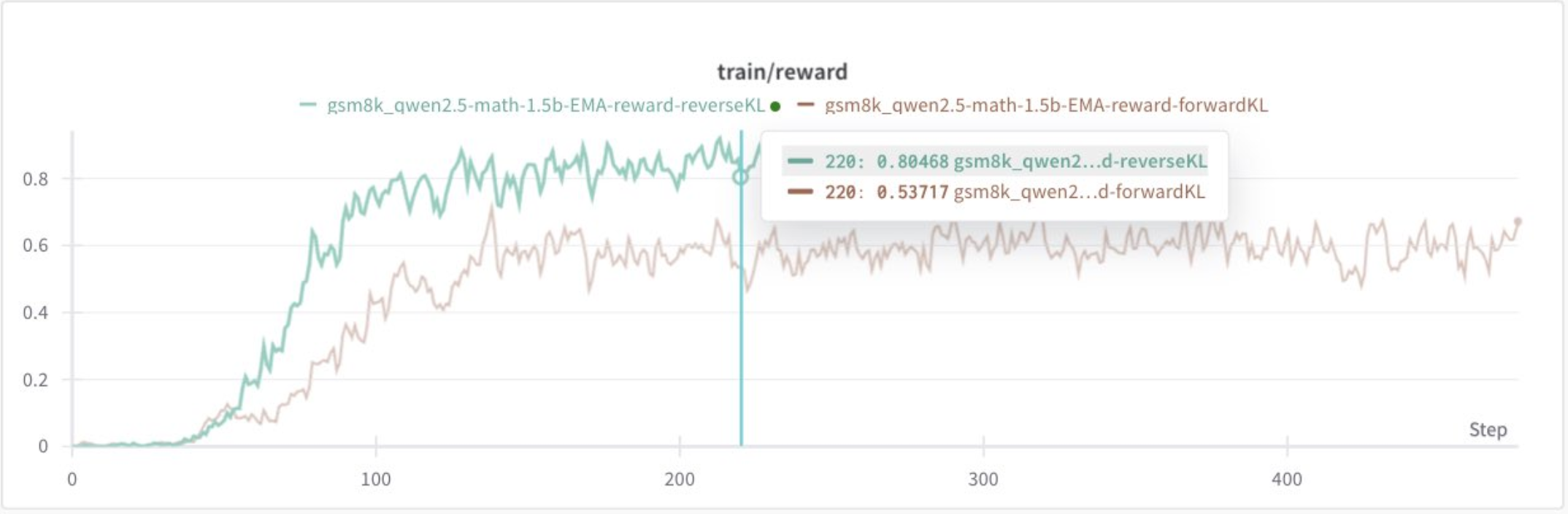 从(几乎)零到英雄!
从(几乎)零到英雄!
那么您现在就有了一条通往有意义的改进的直接道路。
这是策略梯度的基本原理,它使它们能够将几乎永远无法正确解决问题的模型转变为能够可靠地解决复杂问题的模型。在强化学习中,您不是直接从数据中学习,而是从持续改进的方向中学习,以实现奖励指标所暗示的目标。
这本质上使您能够对学习过程进行建模,而不仅仅是观察那些已经学过的人所取得的结果(我将基于 SFT 的微调类比为与此处相同)。
GRPO 和 r1 应该更广泛地教导人们的是,虽然对实现目标的学习过程进行建模可能很困难,但如果你做得正确,与仅仅模仿已知结果相比,它总是会给你带来更可靠和更普遍的结果。
碰巧的是,通过“结果近似”对数万亿个人类发音符号进行预训练是将智能先验理解融入这些模型的最快方法。但为了让他们实现“可靠地生成工作 Python 代码”等抽象目标,您需要定义(在优化时)必然暗示这些结果的指标。
你永远不可能仅仅通过简单地减少文本上的交叉熵来获得这一点。
但你绝对可以从中得到它的起点。