目前还没有模型卡或公告,但中国人工智能实验室 DeepSeek(中国对冲基金High-Flyer的子公司)发布的这个新模型看起来非常重要。
这是一个巨大的模型 – 685B 参数,磁盘上 687.9 GB(直到如何确定 git-lfs 存储库的大小)。该架构是一个由 256 名专家组成的专家混合体,每个代币使用 8 名专家。
相比之下,Meta AI 发布的最大模型是其Llama 3.1 模型,具有 405B 参数。
Hugging Face 的 VB使用配置文件将其与 DeepSeek v2 进行比较:
| 财产 | v2 | v3 |
|---|---|---|
| 词汇大小 | 102400 | 129280 |
| 隐藏大小 | 4096 | 7168 |
| 中间尺寸 | 11008 | 18432 |
| 隐藏层数 | 30 | 61 |
| 注意力头数 | 32 | 128 |
| 最大位置嵌入数 | 2048 | 4096 |
显然,有些人可以通过chat.deepseek.com和 DeepSeek API 来使用新模型。据我所知,这是分阶段推出 – 我自己似乎还没有访问权限。
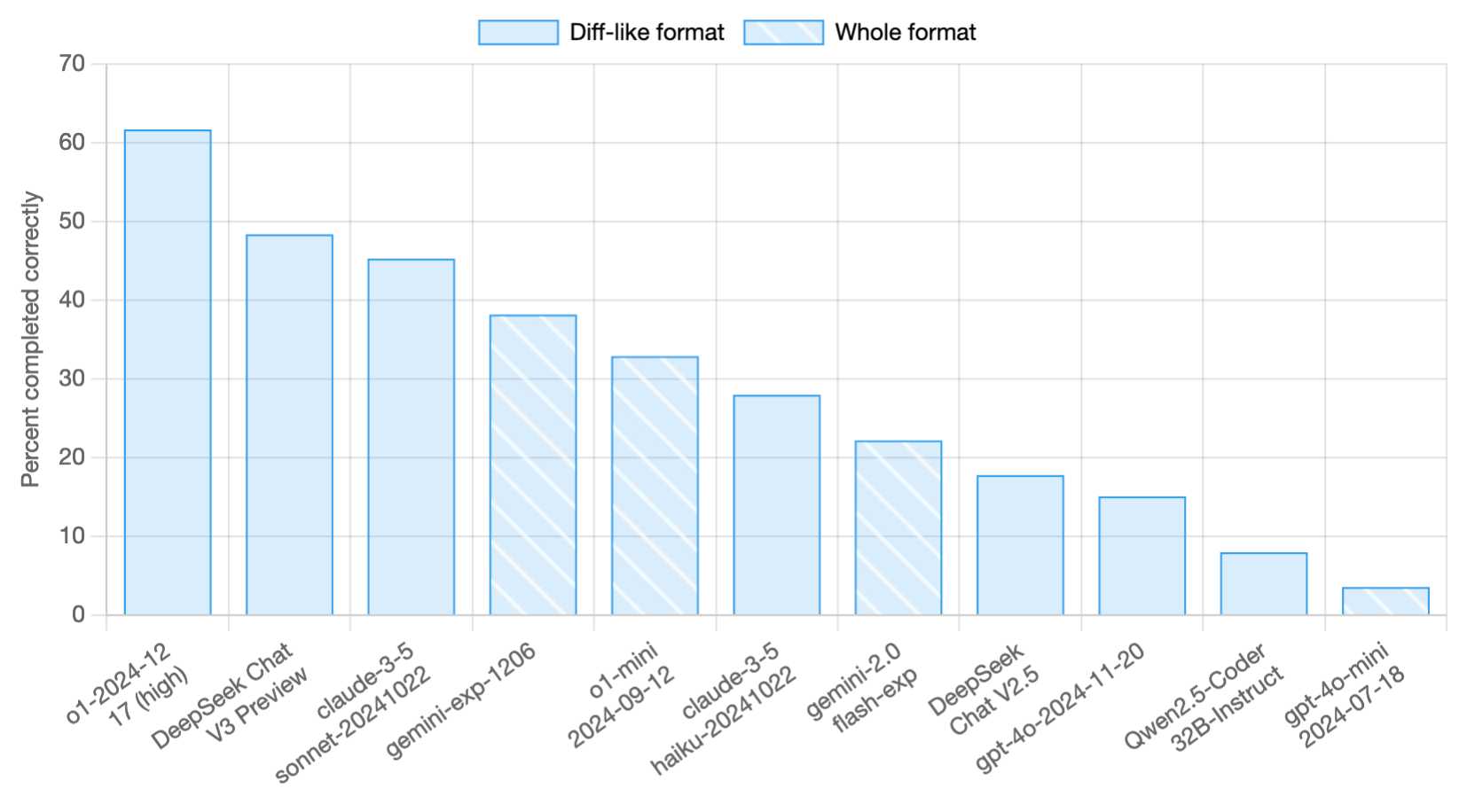
Paul Gauthier 获得了 API 访问权限,并用它来更新他的新Aider Polyglot 排行榜– DeepSeek v3 预览得分为 48.4%,位居第二,落后于o1-2024-12-17 (high) ,领先于claude-3-5-sonnet-20241022和gemini-exp-1206 !
标签: aider 、拥抱脸、生成人工智能、人工智能、 llms 、 deepseek
原文: https://simonwillison.net/2024/Dec/25/deepseek-v3/#atom-everything