Clio:一个用于深入了解现实世界人工智能使用的隐私保护系统
Anthropic 的新研究描述了他们为 Claude 的见解和观察而构建的名为 Clio 的系统,该系统试图提供有关最终用户如何使用 Claude 的见解,同时保护用户隐私。
这里有很多东西需要消化。摘要附有完整的论文以及对团队成员 Deep Ganguli、Esin Durmus、Miles McCain 和 Alex Tamkin 进行的 47 分钟 YouTube 采访。
Clio 背后的关键思想是获取用户对话并使用 Claude 进行总结、聚类,然后分析这些聚类 – 旨在确保在生成的聚类到达人眼之前很久就过滤掉任何私人或个人可识别的详细信息。
论文中的这张图有助于解释其工作原理:
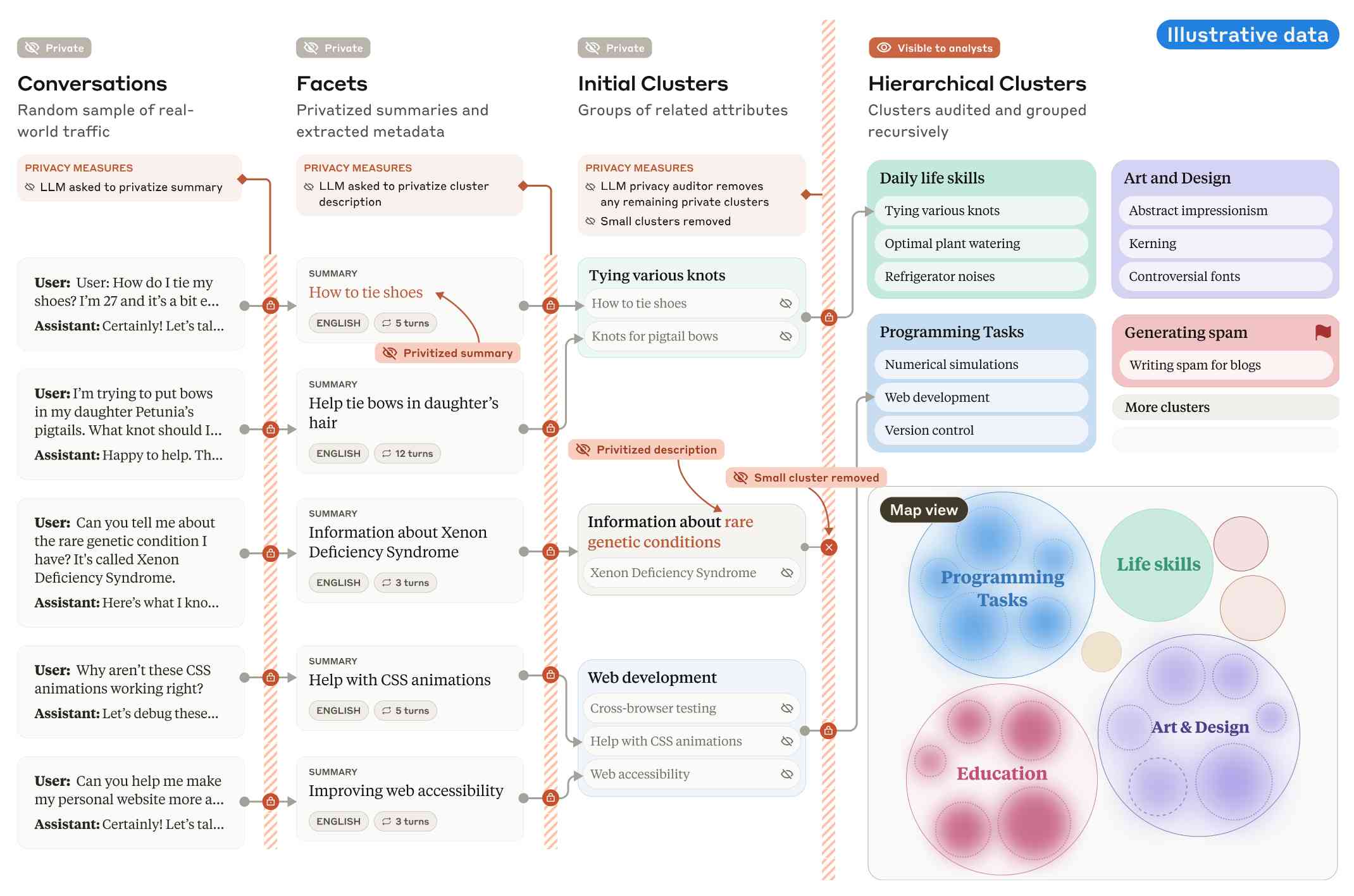
克劳德生成对话摘要,然后从该摘要中提取“方面”,旨在将数据私有化为语言和主题等简单特征。
这些方面用于创建初始集群(通过嵌入),并且这些集群被进一步过滤以删除任何太小的或可能包含私人信息的集群。目标是不存在代表少于 1,000 个底层个人用户的集群。
16:39 的视频中:
然后我们可以用它来了解,例如,克劳德是否同样有用,为用英语或西班牙语的人提供网络开发建议。或者我们可以了解人们通常寻求帮助的编程语言是什么。我们可以以真正保护隐私的方式完成所有这一切,因为我们远离底层对话,我们非常有信心我们可以以尊重用户期望我们提供的隐私精神的方式使用它。
然后在29:50 ,有一个关于 Anthropic 如何聘请人类注释者来提高 Claude 在特定领域的表现的有趣提示:
但我们可以做的一件事是我们可以查看拒绝率或信任和安全标记率较高的集群。然后我们可以看看这些,然后说,这显然是过度拒绝,这显然没问题。我们可以用它来关闭循环,然后说,好吧,这里有一些例子,我们想添加到我们的人类训练数据中,这样克劳德将来就不会拒绝这些主题。
重要的是,我们并没有利用实际的对话来减少克劳德的拒绝。相反,我们正在做的是我们正在研究这些主题,然后雇用人员在这些领域中生成数据并在这些领域中生成合成数据。
因此,我们能够利用 Claude 的用户活动来改善他们的体验,同时尊重他们的隐私。
根据 Clio 的说法,目前 Claude 的主要使用情况如下:
- 网络和移动应用程序开发 (10.4%)
- 内容创作与传播 (9.2%)
- 学术研究与写作 (7.2%)
- 教育与职业发展 (7.1%)
- 高级人工智能/机器学习应用 (6.0%)
- 业务战略与运营 (5.7%)
- 语言翻译 (4.5%)
- 开发运营和云基础设施 (3.9%)
- 数字营销和搜索引擎优化 (3.7%)
- 数据分析与可视化 (3.5%)
关于不同语言的使用差异,还有一些有趣的见解。例如,中文用户“写具有复杂情节和人物的犯罪、惊悚和悬疑小说”的比率是其他语言的基本比率的 4.4 倍。
标签:生成人工智能、人类、克劳德、伦理、隐私、人工智能、 LLMS 、嵌入
原文: https://simonwillison.net/2024/Dec/12/clio/#atom-everything