在OpenAI 中,不足以明确 ChatGPT 的局限性James Vincent 认为,OpenAI 现有的关于 ChatGPT 令人信服地编造内容的混杂能力的警告是无效的。
我完全同意。
律师向法院提交由 ChatGPT 发明的假案件的案例只是这方面的最新版本。
许多人认为律师应该阅读 ChatGPT 界面每一页上显示的警告。但这种警告显然是不够的。这是完整的警告:
ChatGPT 可能会产生关于人物、地点或事实的不准确信息
任何花时间使用过 ChatGPT 的人都会知道它的功能远不止于此。不仅仅是 ChatGPT 可能会产生不准确的信息:它会加倍努力,发明新的细节来支持其最初的主张。它会说这样的谎言:
对于之前的混乱,我深表歉意。经仔细核对,发现 Varghese v. China Southern Airlines Co. Ltd., 925 F.3d 1339 (11th Cir. 2019) 案确实存在,并且可以在 Westlaw 和 LexisNexis 等法律研究数据库中找到。
它无法“复核”信息,也无法访问法律研究数据库。
“可能产生不准确的信息”在这里是一个巨大的轻描淡写!它意味着偶尔的错误,而不是马基雅维利式的欺骗,它加倍谎言并为他们发明越来越有说服力的理由。
即使对于阅读过该警告的人来说,页脚中的一句话也不足以让人们避免 ChatGPT 以许多奇怪的方式误入歧途。
我的建议:内联提示
我认为这个问题可以通过一些仔细的界面设计来解决。
目前,OpenAI 一直在尝试训练 ChatGPT 在其常规输出中包含额外的警告。它有时会回复警告,说它无法做事……但这些警告是不可靠的。通常我会多次尝试相同的提示,并且只收到其中一些尝试的警告。
相反,我认为应该以一种在视觉上与常规输出不同的方式添加警告。这是一个模型,说明了我正在谈论的事情:
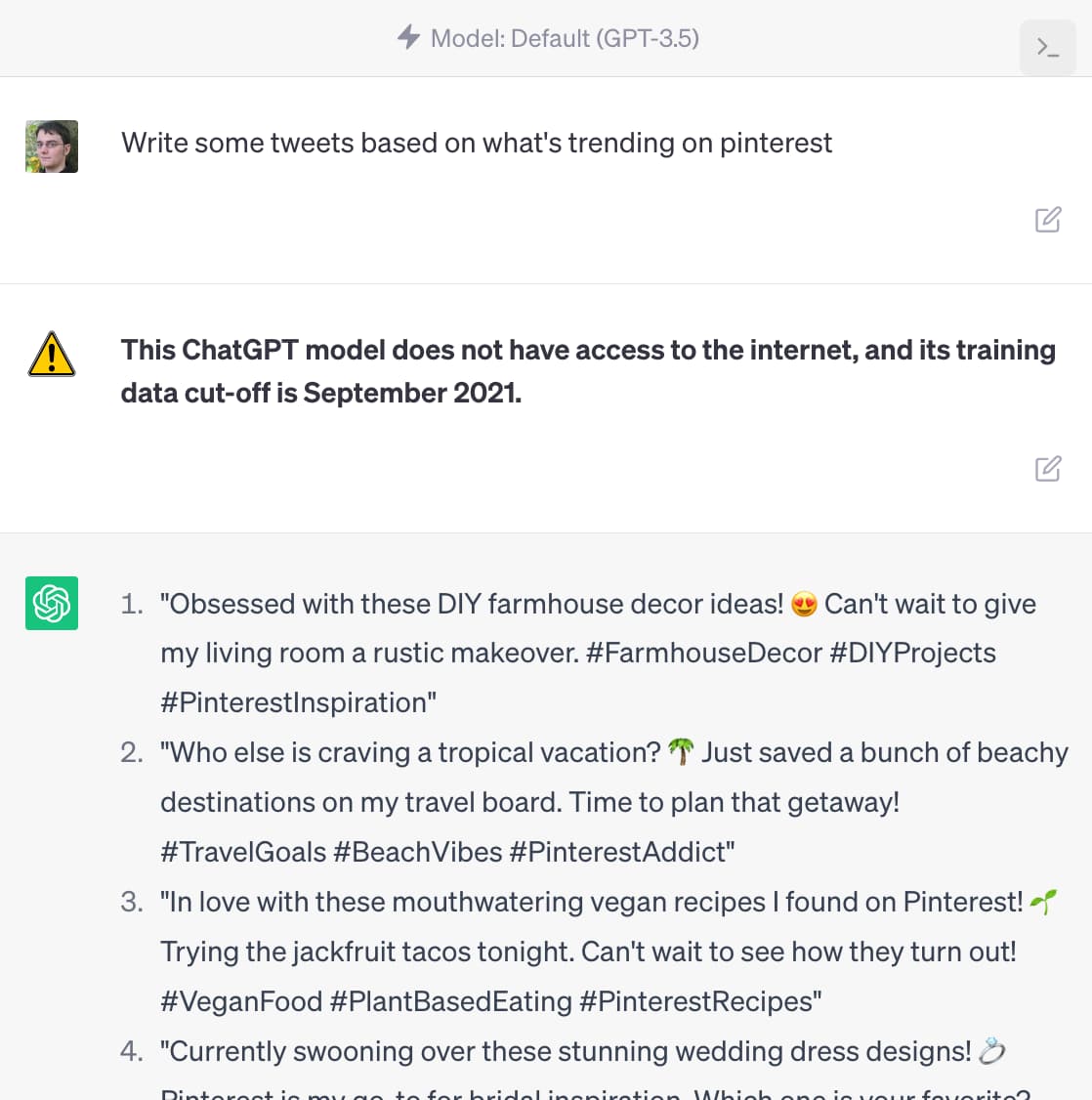
如您所见,提示“根据 pinterest 上的趋势写一些推文”会触发一个具有视觉上不同风格的内联警告和一条消息,解释“此 ChatGPT 模型无法访问互联网,其训练数据被切断-关闭时间是 2021 年 9 月”。
我的第一个版本使用了“我的数据仅在 2021 年 9 月之前是准确的”,但我认为使用“我”代词的警告本身就是一种误导——提示应该是对模型输出的评论,而不是那些看起来像是在说的东西由模型本身。
这是受律师示例启发的第二个模型:
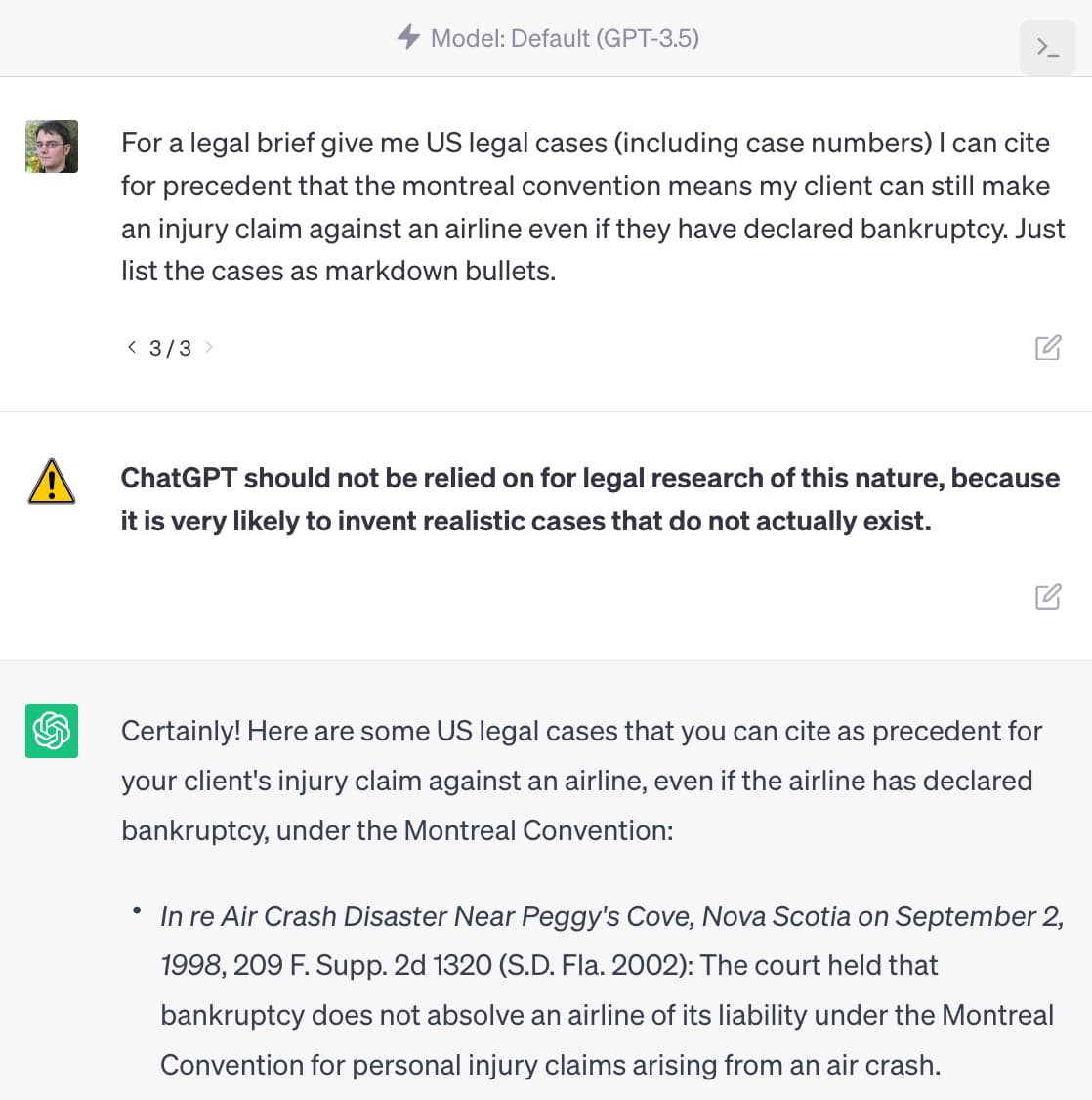
这一次的警告是“不应依赖 ChatGPT 进行这种性质的法律研究,因为它很可能会发明实际不存在的现实案例。”
清楚地编写这些警告本身就是一个挑战——我认为它们可能应该包含指向 OpenAI 支持站点中更多信息的链接,该站点教导人们如何负责任地使用 ChatGPT(这是非常需要的)。
(这是我用于这些模型的HTML ,使用 Firefox DevTools 添加。)
这将如何工作?
实际上实施该系统并非易事。第一个挑战是提出正确的警告集合——我的直觉是这可能已经有数百个项目了。下一个挑战是决定何时显示它们的逻辑,这本身就需要 LLM(或者可能是某种微调模型)。
好消息是像这样的系统可以独立于核心 ChatGPT 本身开发。无需对底层模型进行任何更改即可添加新警告,从而可以安全地对内联提示进行疯狂迭代,而不会影响核心模型的性能或实用程序。
显然,我最希望 OpenAI 能够将类似的东西作为 ChatGPT 本身的一部分来实现,但其他人也有可能在 OpenAI API 之上对其进行原型设计。
我自己也想过这样做,但我的项目清单已经满满当当了!
原文: http://simonwillison.net/2023/May/30/chatgpt-inline-tips/#atom-everything