原推:Facebook’s LLaMa model only hit 52% on SIQA
It’s the only benchmark where we wouldn’t expect to see relatively near-term zero-shot saturation
Looking for an area that human’s will remain superior, this benchmark is it
But I suspect RLHF meaningfully improves AI performance https://t.co/HxpcAhH8kO
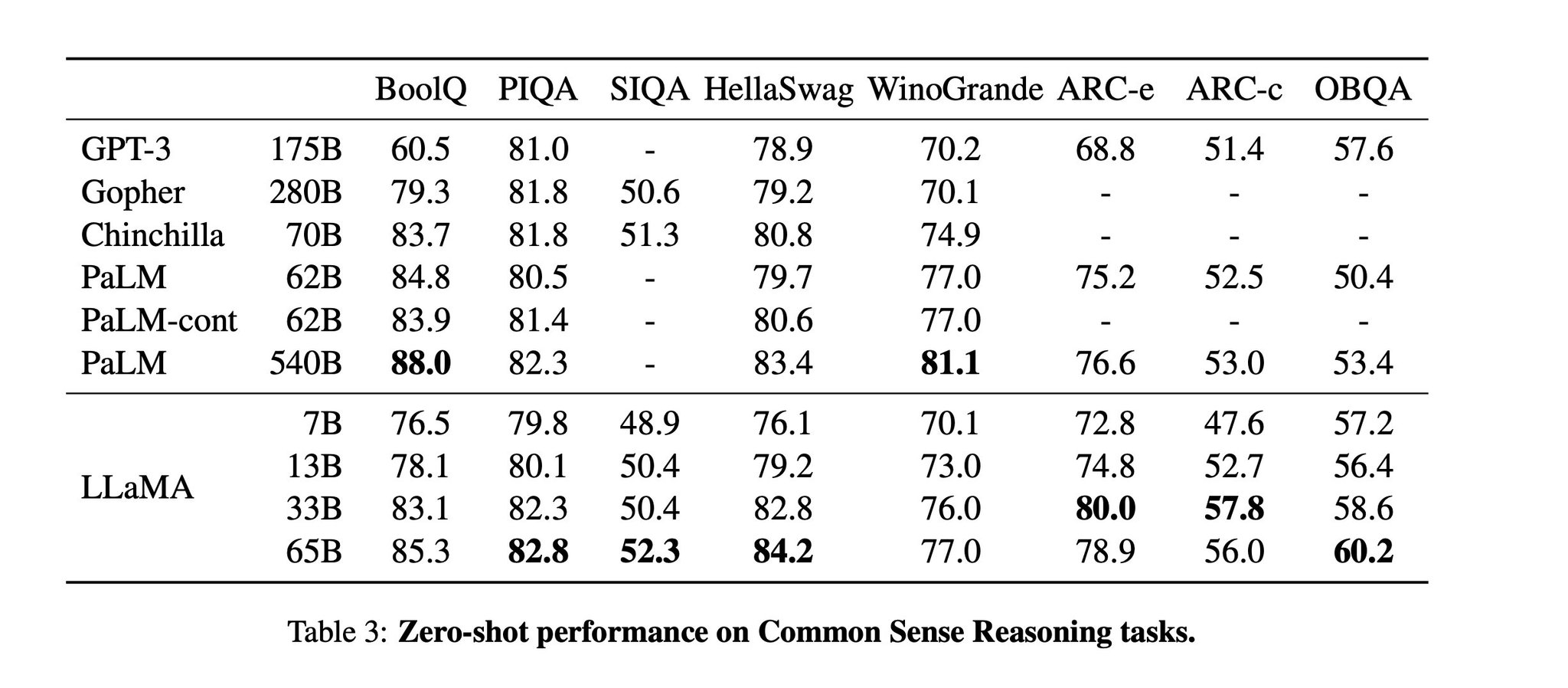
Could somebody please benchmark chatGPT (or another human feedback-tuned model) on the Social IQa (SIQA) benchmark?
There is a clear (and potentially ambiguous) culture-specific ethical overlay to SIQA, and I’m guessing that RLHF-tuning would deliver outperformance https://t.co/elRyo3MNnp