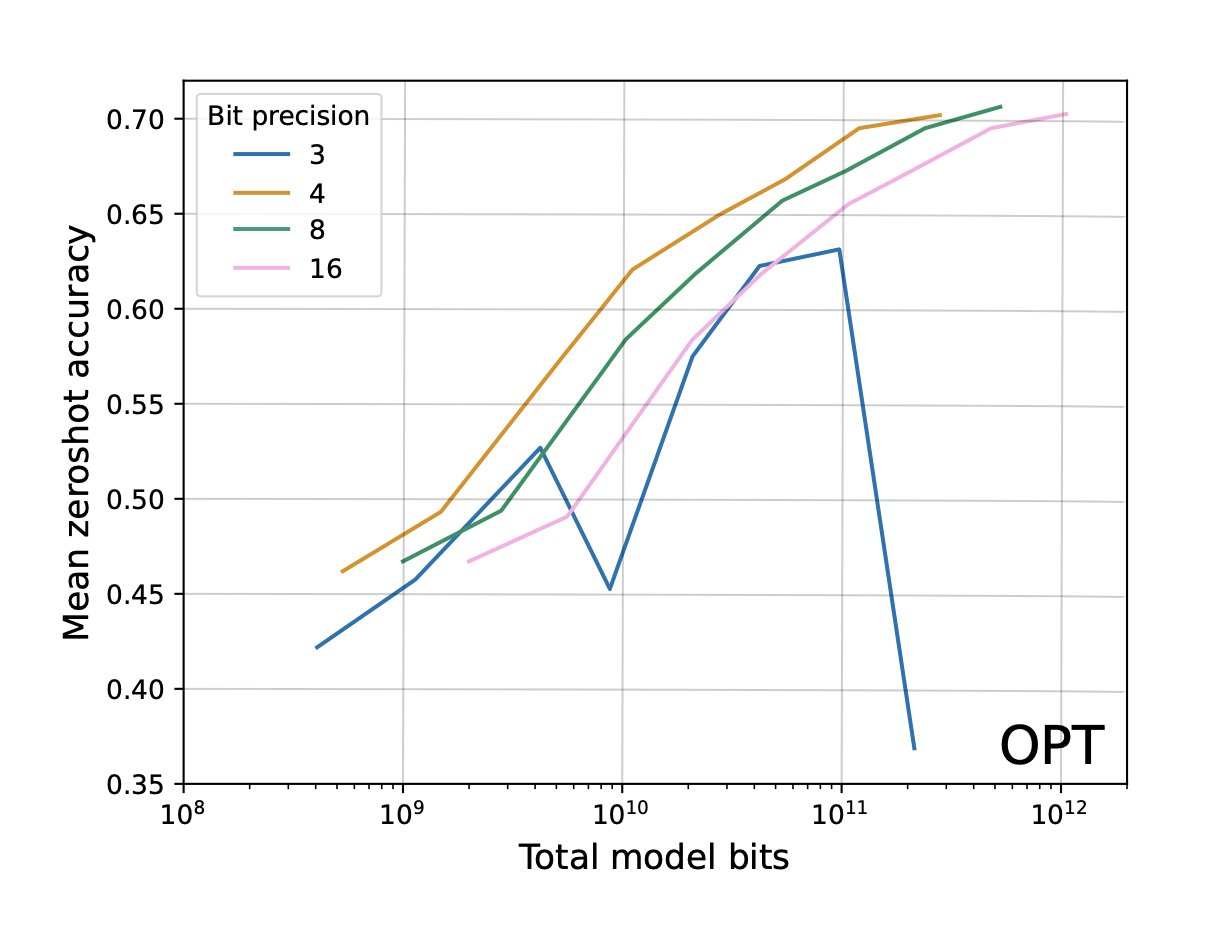
原推:Suggests that a language model inferring at 4 bit precision can deliver ~same performance as an 8 bit model at 2x the memory/latency
Double your AI performance for ~free
I wonder if this is broadly applicable
Tesla FSD uses 8 bit precision iirc
翻译英文优质信息和名人推特
原推:Suggests that a language model inferring at 4 bit precision can deliver ~same performance as an 8 bit model at 2x the memory/latency
Double your AI performance for ~free
I wonder if this is broadly applicable
Tesla FSD uses 8 bit precision iirc