这是 Anthropic 的一个新的仅 API 功能,需要大量的组装才能释放其价值: Introducing Citations on the Anthropic API 。让我们来谈谈这是什么以及为什么它很有趣。
检索增强生成的引用
检索增强生成(RAG) 模式的核心是接受用户的问题,检索可能与该问题相关的文档部分,然后通过将这些文本片段包含在提供给法学硕士的上下文中来回答问题。
这通常效果很好,但仍然存在模型可能根据训练数据中的其他信息进行回答的风险(有时可以)或产生完全不正确的细节(绝对是糟糕的)。
帮助减轻这些风险的最佳方法是通过包含直接引用基础源文档的引用来支持答案。这甚至可以作为事实检查的一种形式:用户可以确认引用的文本确实来自这些文档,有助于提供相对强大的保护,防止幻觉细节导致错误答案。
实际上构建一个执行此操作的系统可能非常棘手。去年四月,Matt Yeung 描述了一种他称之为“确定性引用”的模式,其中答案附有来自源文档的直接引用,这些引用保证被模型复制而不是有损地转换。
这是一个好主意,但实际构建它需要一些相当复杂的提示工程和复杂的实现代码。
Claude 的新Citations API机制可以为您处理其中的困难部分。您仍然需要实现大部分 RAG – 识别潜在的相关文档,然后将这些内容作为提示的一部分输入 – 但 Claude 的 API 将完成提取相关引文并将其包含在发回给您的响应中的艰巨工作。
使用 uv run 尝试新的 API
我使用 Anthropic 的 Python 客户端库尝试了该 API,该库刚刚更新以支持引文 API。
我使用该包使用uv run运行了一个临时 Python 3.13 解释器,如下所示(首先使用llm keys get设置必要的ANTHROPIC_API_KEY环境变量之后):
导出ANTHROPIC_API_KEY = “ $( llm密钥获取克劳德) ” uv run --with anthropic --python 3.13 python
Python 3.13 有一个更好的交互式解释器,您可以更轻松地将代码粘贴到其中。像这样使用uv run为我提供了一个预安装了该软件包的环境,而无需我单独设置虚拟环境。
然后我运行了以下代码,改编自Anthropic 的示例。 text.txt Gist包含我从“我们在 2024 年学到的关于 LLM 的事情”一文中复制的文本。
导入urllib 。要求 导入json url = 'https://gist.githubusercontent.com/simonw/9fbb3c2e2c40c181727e497e358fd7ce/raw/6ac20704f5a46b567b774b07fd633a74944bab2b/text.txt' 文本= urllib .要求。 urlopen ( url ).读()。解码( 'utf-8' ) 进口人择 客户=人为的。人择() 响应=客户端。消息。创造( 型号= “claude-3-5-sonnet-20241022” , 最大令牌数= 1024 , 消息= [ { “角色” : “用户” , “内容” : [ { “类型” : “文档” , “来源” : { “类型” : “文本” , “media_type” : “文本/纯文本” , “数据” :文本, }, "title" : "我的文档" , "context" : "这是一份值得信赖的文档。" , “引用” :{ “启用” : True } }, { “类型” : “文本” , "text" : "最热门的趋势是什么?" } ] } ] ) print ( json . dumps ( response . to_dict (), indent = 2 ))
JSON 输出如下所示:
{ “id” : “ msg_01P3zs4aYz2Baebumm4Fejoi ” , “内容” : [ { "text" : "根据该文档,以下是 2024 年以来 AI/LLM 的主要趋势: \n\n 1. 打破 GPT-4 障碍: \n " , “类型” : “文本” }, { “引用” :[ { "cited_text" : "让我松了口气的是,在过去 12 个月里,这种情况已经完全改变。现在有 18 个组织在 Chatbot Arena 排行榜上拥有比 2023 年 3 月的原始 GPT-4 排名更高的模型(GPT-4-0314板) \u2014总共 70 个模型\n\n " , “文档索引” : 0 , "document_title" : "我的文档" , “结束字符索引” : 531 , “起始字符索引” : 288 , “类型” : “字符位置” } ], "text" : " GPT-4 壁垒被彻底打破,自 2023 年 3 月起,已有 18 个组织拥有排名高于原始 GPT-4 的模型,总共有 70 个模型超过了它。 " , “类型” : “文本” }, { "text" : " \n\n 2. 增加上下文长度: \n " , “类型” : “文本” },
这是完整的回复。
这个格式还蛮有趣的!这是标准的克劳德格式,但这些"content"块现在包含一个可选的附加"citations"键,其中包含支持"text"块中的声明的相关引文摘录列表。
呈现引文
观察 JSON 输出并不是特别有趣。我想要一个非常快速的工具来帮助我以更直观的方式查看输出。
我最近经常使用的一个技巧是,像 Claude 这样的法学硕士非常擅长编写代码,将这样的任意 JSON 形状转换为更易于人类阅读的格式。
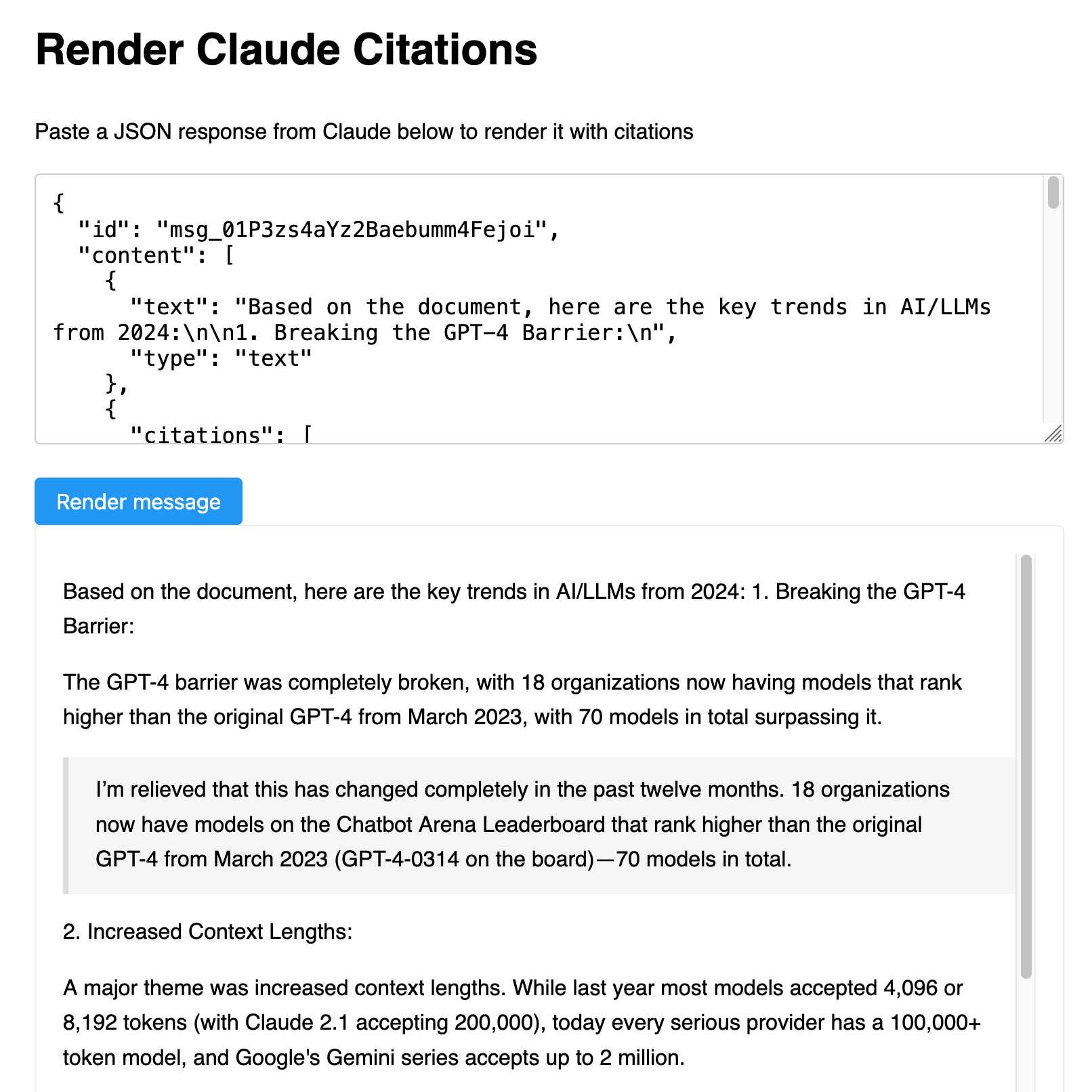
我启动了我的Artifacts 项目,粘贴到上面的 JSON 中并提示如下:
构建一个工具,我可以将这样的 JSON 粘贴到文本区域中,结果将以一种简洁的方式呈现 – 它应该将文本与引文穿插,其中每个引文都有以块引用呈现的引用文本
它帮助我构建了这个工具(此处的后续提示),它允许您粘贴 JSON 并生成文本的渲染版本:
现在我需要为LLM设计一个抽象层
我想升级我的LLM工具和llm-claude-3插件以包括对这个新功能的支持……但这样做相对来说并不简单。
问题是法学硕士目前假设所有法学硕士都以文本流响应。
有了引用,这不再是事实了! Claude 现在返回的文本块不仅仅是纯字符串,它们还带有引文注释,需要由 LLM 库以某种方式存储和处理。
这并不是此类的唯一边缘情况。 DeepSeek 最近发布了他们的 Reasoner API,它也有类似的问题:它可以返回两种不同类型的文本,一种显示推理文本,另一种显示最终内容。我在这里描述了这些差异。
我在 LLM 存储库中提出了一个设计问题来应对这一挑战:为响应设计一个抽象,而不仅仅是文本流。
Anthropic 的策略与 OpenAI 的对比
此版本的另一个有趣的方面是它如何帮助说明 Anthropic 和 OpenAI 之间的战略差异。
OpenAI 的行为越来越像一家消费品公司。他们刚刚凭借其Operator浏览器自动化代理系统引起了巨大轰动,这是几个月前 Anthropic 自己的计算机使用演示的更加精致的消费产品版本。
与此同时,Anthropic 显然更加关注开发者/“企业”市场。此引文功能仅限 API,可直接满足尝试在其平台上构建可靠的 RAG 系统的开发人员可能甚至没有意识到的特定需求。
标签:工具、人工智能、 openai 、即时工程、生成人工智能、 LLMS 、人工智能辅助编程、 LLM 、人类、克劳德、抹布、克劳德工件
原文: https://simonwillison.net/2025/Jan/24/anthropics-new-citations-api/#atom-everything