自 2025 年初以来,人工智能实验室向我们提供了大量新模型,我很难跟上。

但趋势表明没人在乎!只有 ChatGPT。
为何如此?
新模型很棒,但它们的命名完全是一团糟。另外,您甚至无法再通过基准来区分模型。简单地说“这个是最好的,每个人都用它。”现在不起作用。
简而言之,市场上有很多真正出色的人工智能模型,但真正使用它们的人很少。
这太可惜了!
我将尝试理解命名混乱的情况,解释基准危机,并分享如何选择适合您需求的模型的技巧。
太多的型号,可怕的名字
达里奥·阿莫迪 (Dario Amodei) 长期以来一直开玩笑说,在我们学会清楚地命名我们的模型之前,我们可能会创建 AGI。谷歌历来引领着这场混乱游戏:

公平地说,这是有一定道理的。每个“基础”模型现在都有很多更新。它们并不总是具有足够的开创性,足以证明每次更新都是新版本。这就是所有这些前缀的来源。
为了简化事情,我将主要实验室的模型类型放在一起,删除了所有不必要的细节。
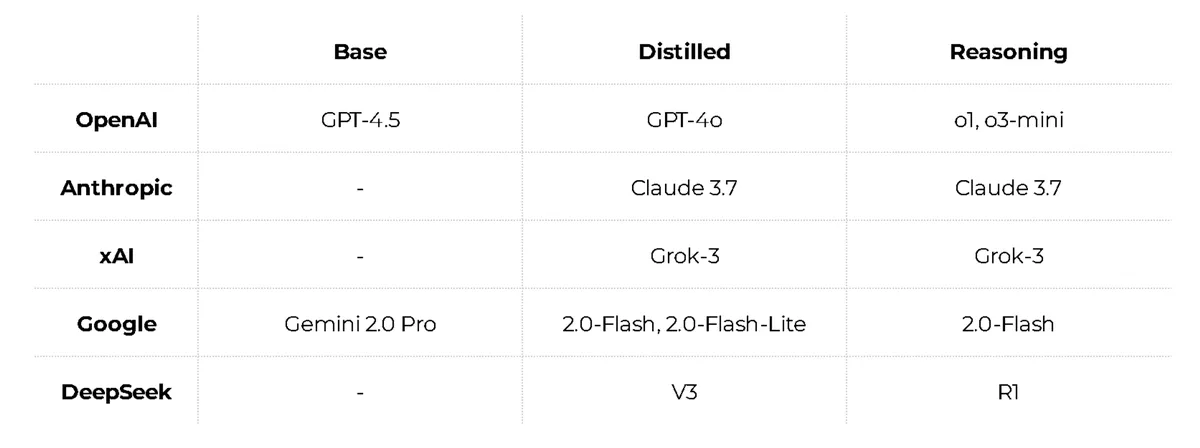
那么这些模型有哪些类型呢?
-
有巨大而强大的基础模型。它们令人印象深刻,但规模缓慢且成本高昂。
-
这就是我们发明蒸馏的原因:采用一个基本模型,根据其答案训练一个更紧凑的模型,您将获得大致相同的功能,只是更快、更便宜。
-
这对于推理模型尤其重要。现在,表现最好的人遵循多步骤推理链——规划解决方案、执行并验证结果。有效但价格昂贵。
还有专门的模型:用于搜索、用于简单任务的超便宜模型,或用于医学和法律等特定领域的模型。加上一个单独的图像、视频和音频组。为了避免混淆,我没有包含所有这些内容。我还故意忽略了其他一些模型和实验室,以使其尽可能简单。
有时更多的细节只会让事情变得更糟。

现在所有模型基本上都是平等的
选出一个明显的赢家变得很困难。安德烈·卡帕蒂 (Andrej Karpathy) 最近将此称为“评估危机”。
目前尚不清楚该关注哪些指标。 MMLU 已经过时,SWE-Bench 太窄。 Chatbot Arena 非常受欢迎,以至于实验室已经学会了“破解”它。

目前,评估模型的方法有以下几种:
- 狭窄的基准衡量非常具体的技能,例如 Python 编码或幻觉率。但模型变得越来越智能并掌握更多任务,因此您不能再仅用一种指标来衡量它们的水平。

- 综合基准测试尝试捕获具有大量指标的多个维度。但比较所有这些分数很快就会变得混乱。请注意,人们试图考虑多个这些复杂的基准。一次五到十个!一个模型在这里获胜,另一个模型在那里获胜——祝你好运,理解它。 LifeBench 每个类别都有 3 个指标。这只是数十个基准中的一个。

- Arena,人类根据个人喜好盲目比较模型答案。模特获得 ELO 评级,就像国际象棋棋手一样。更频繁地获胜,获得更高的 ELO。但在模型彼此靠得太近之前,这一切都很棒。

35 分的差异意味着模型只有 55% 的时间更好。
就像在国际象棋中一样,ELO 较低的玩家仍然有很大的获胜机会。即使存在 100 分的差距,“更差”的模型在三分之一的情况下仍然表现出色。
再说一次,有些任务用一种模型可以更好地解决,另一些则用另一种模型可以更好地解决。选择列表中较高的型号,您的 10 个请求中的一个可能会更好。哪一个好,好多少?谁知道呢。
那么,您如何选择?
由于缺乏更好的选择,卡帕西建议依靠氛围检查。
亲自测试这些模型,看看哪一个感觉正确。当然,欺骗自己很容易。它是主观的并且容易产生偏见,但它很实用。
这是我个人的建议:
-
如果任务是新任务,请打开具有不同模型的多个选项卡并比较结果。相信您的直觉,哪个模型需要较少的调整或编辑。
-
如果任务更熟悉,请仅使用您最好的模型。
-
忘记追逐基准数字。专注于您喜欢的用户体验,并优先考虑您已经愿意付费的订阅。
-
如果您仍然想要数字,请尝试 https://livebench.ai/#/。创建者声称它解决了常见的基准测试问题,如黑客攻击、过时、狭隘和主观性。
-
对于产品创建者来说,HuggingFace 提供了一份关于如何设置自己的基准的精彩指南。 https://ift.tt/MemYGCD
同时,如果您一直在等待尝试除 ChatGPT 之外的其他功能的标志,这里是:
https://claude.ai/
https://ift.tt/yCzAbv3
https://grok.com/
https://ift.tt/J2p3h4N