这篇文章很长,所以我建议在网上阅读!它是我对 AGI 进化的想法的概括,我已经在此处和此处等地写过各种关于它的文章。如果您想开门见山开始辩论,请随意查看方程式并跳到最后一节。

聪明人一直担心创造出聪明而有能力的人工智能 (AGI)。令人担忧的是,就其本质而言,它将拥有一套截然不同的道德准则(它应该或不应该做的事情)和一套大大增强的能力,这可能会导致相当灾难性的后果。就像一个拿着火箭筒的婴儿,但更糟。 Metaculus 现在预测到 2027 年弱 AGI 到 2038 年具有机器人能力的强AGI。
先说我的偏见,我发现这不是很有说服力。从认识论的角度来看,“这可能是危险的”似乎不足以让人担心,而“我们应该让它更安全”似乎是一个无关紧要的问题。可以肯定的是,让它更安全,但因为没有人知道很多人互相来回交谈的感觉。在社交媒体出现之前,我们无法解决社交媒体的恐怖问题。在互联网使用率飙升和成本直线下降之前,我们无法解决在线安全问题。杰森·克劳福德 (Jason Crawford) 撰写了有关安全哲学的文章,以及它如何成为进步的一部分而不是与之分离。
然而,随着人工智能技术的每一个新实例的下降,加速论者和世界末日论者的阵营都在说同样的话。想象一下,如果这继续以同样的速度变得强大。想象一下,如果这项技术落入坏人之手。想象一下,如果我们创造的人工智能由于无能、漠不关心或受过教育的恶意而没有按照我们的指示去做。
担忧部分的核心在于能力的增长速度与明智地运用能力的知识增长速度不同。最好的例子是Joe Carlsmith的这篇论文和Ajeya Cotra的这篇研究文章。我不会尝试总结它们,因为它们信息极其密集且充满假设,但结论包括两个组成部分——随着机器内智能和能力的增加,我们失去了控制它的能力,而且它可能不会重视我们重视的事物,从而造成不经意的混乱。
这感觉非常像为一个尚不存在的物种创建人类学。
虽然我之前写过关于 AI 末日的想法作为末世论,并且在技术乐观主义者阵营中非常关注它的潜力,但当多个聪明人对同一个问题感到恐惧时,检查它的人是否是书呆子很有用-狙击。
第一个问题是如何分解问题。因为最终,人工智能使每个人变灰、引爆所有核弹或制造病原体的许多方式,都假设了一种基本上可以得到答案的复杂程度。因此,我查看了我们之前与不可言说的事物搏斗的地方,并试图以某种方式打破我们对事物存在的不确定性,在这种情况下,一个恶意的实体,令人不安的大部分人口都乐于称之为恶魔。
我们之前已经研究过如何计算不可计算的。最著名的是,在 1961 年,天体物理学家弗兰克·德雷克 (Frank Drake) 问了地球外可能存在多少文明。为了回答这个问题,他创建了他的同名方程式。
您可以将其视为费米估计的第一原理。根据你对创造外星生命形式所需要的东西的假设,恒星形成的速度,拥有行星的比例,可以支持生命并实际发展生命的比例,以及最终将对我们可见的文明的比例。正如弗兰克德雷克所说:
在计划会议时,我意识到提前几天我们需要一个议程。所以我写下了所有你需要知道的事情,以预测探测外星生命的难度。看着它们,很明显,如果将所有这些相乘,就会得到一个数字 N,这是我们银河系中可探测文明的数量。
这些分数中的每一个当然都是高度可变的,但我们的想法是了解方程式的输入并帮助我们更好地思考。或者用新主人的话来说。
德雷克方程是一个特定的方程,用于估计我们银河系中智慧地外文明的数量。虽然可能还有其他方程式可用于估计某些事件的可能性或概率,但我不知道有任何方程式可与德雷克方程式直接比较。值得注意的是,德雷克方程并不是传统意义上的科学方程,而是一种帮助组织和构建我们对地外生命存在概率思考的方式。
德雷克方程式是一种提炼我们对围绕外星生命出现的极其复杂场景的思考的方法,在这方面它真的很有帮助。
这让我想到,我们不应该在人造外星智能的出现方面也有类似的东西吗?我环顾四周,没有发现任何可比性。所以,我决定为 AGI 做一个方程式,以帮助我们思考其发展过程中对存在风险(x-risk)的担忧。
Scary AI = I * A1 * A2 * U1 * U2 * A3 * S * D * F
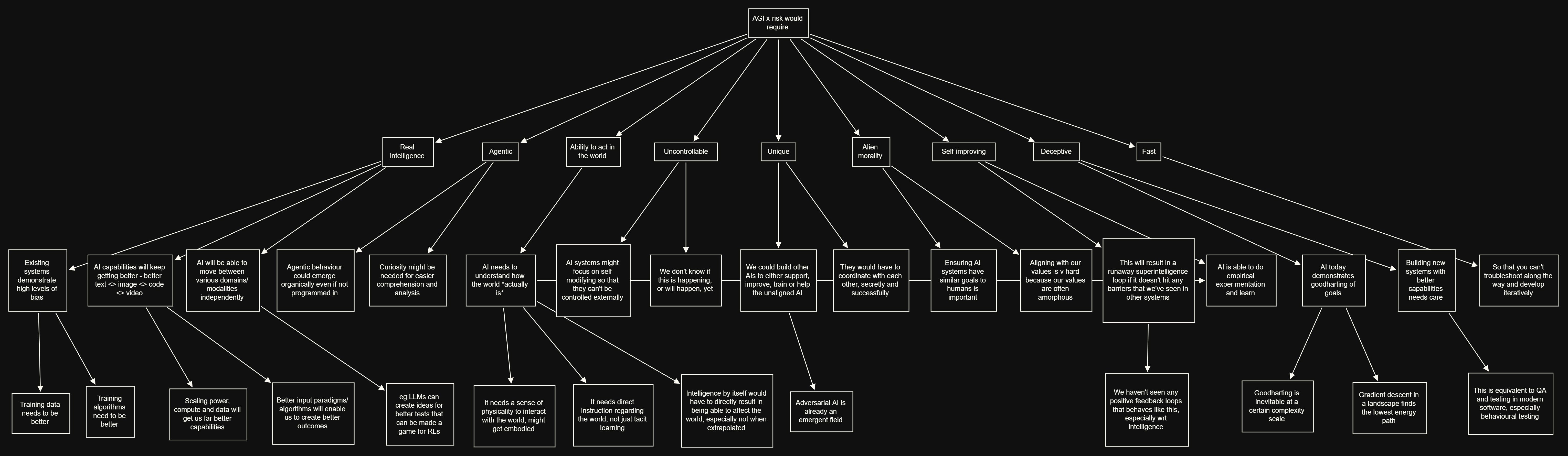
让我们来看看。
感谢阅读 Strange Loop Canon!在这里订阅!
真实情报的概率百分比
很难定义,但也许就像色情一样,当我们看到它时很容易识别。尽管德意志人对行为主义感到痛苦,或者更确切地说是波普尔式的愤怒,但至少有可能看到一个系统如何表现得好像它具有真正的智能一样。
有多种方法可以从这里到达那里。当我写到 AI 正在开发的任何机器时,需要的部分承诺是使其彼此无缝连接,因此每个模型都不会坐在自己的孤岛上。
您需要更好或更多的训练数据。我们实际上不知道需要多少或保真度是多少,因为我们所看到的真正智能的唯一来源是在不断变化的环境中超过一百万代的大规模并行优化问题的结果。那是提炼出来的知识,我们实际上并不知道复制它真正需要什么。
从已经完成的各种类型的分析来看,大脑显示出大约 10^23 FLOPs 的计算能力。
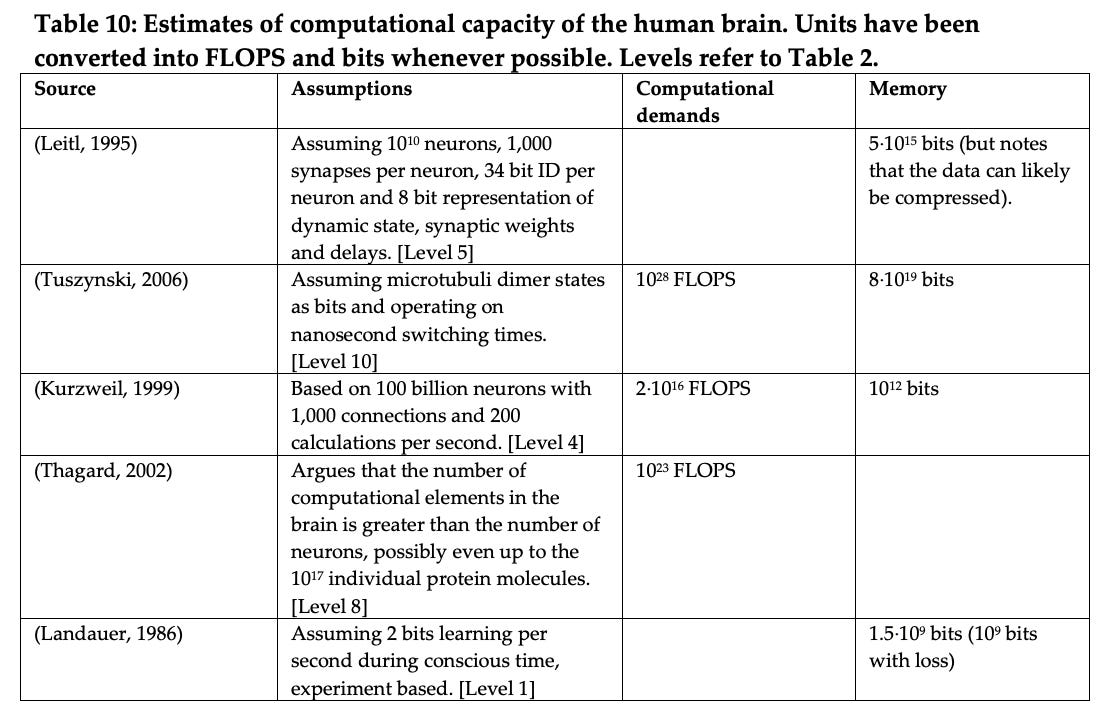
哪个……很好。然而,在他们比较计算机在这方面的表现时。
在我们比较的少数计算机中** 4 **,FLOPS 和 TEPS 似乎成比例变化,变化率约为 1.7 GTEPS/TFLOP。我们还估计人脑执行大约 0.18 – 6.4 * 1014 TEPS。因此,如果大脑中的 FLOPS:TEPS 比率与计算机中的相似,那么大脑将执行大约 0.9 – 33.7 * 1016 FLOPS。我们还没有调查这个比率可能有多相似。
现在用一堆盐来接受这个,但更广泛的观点似乎是纯粹的原始计算能力,我们可能离一个人所做的“思考”与另一个人所做的“思考”相当的世界并不遥远。如果可以在一个物理基底上进行计算,那么当然也可以在另一个物理基底上进行计算。
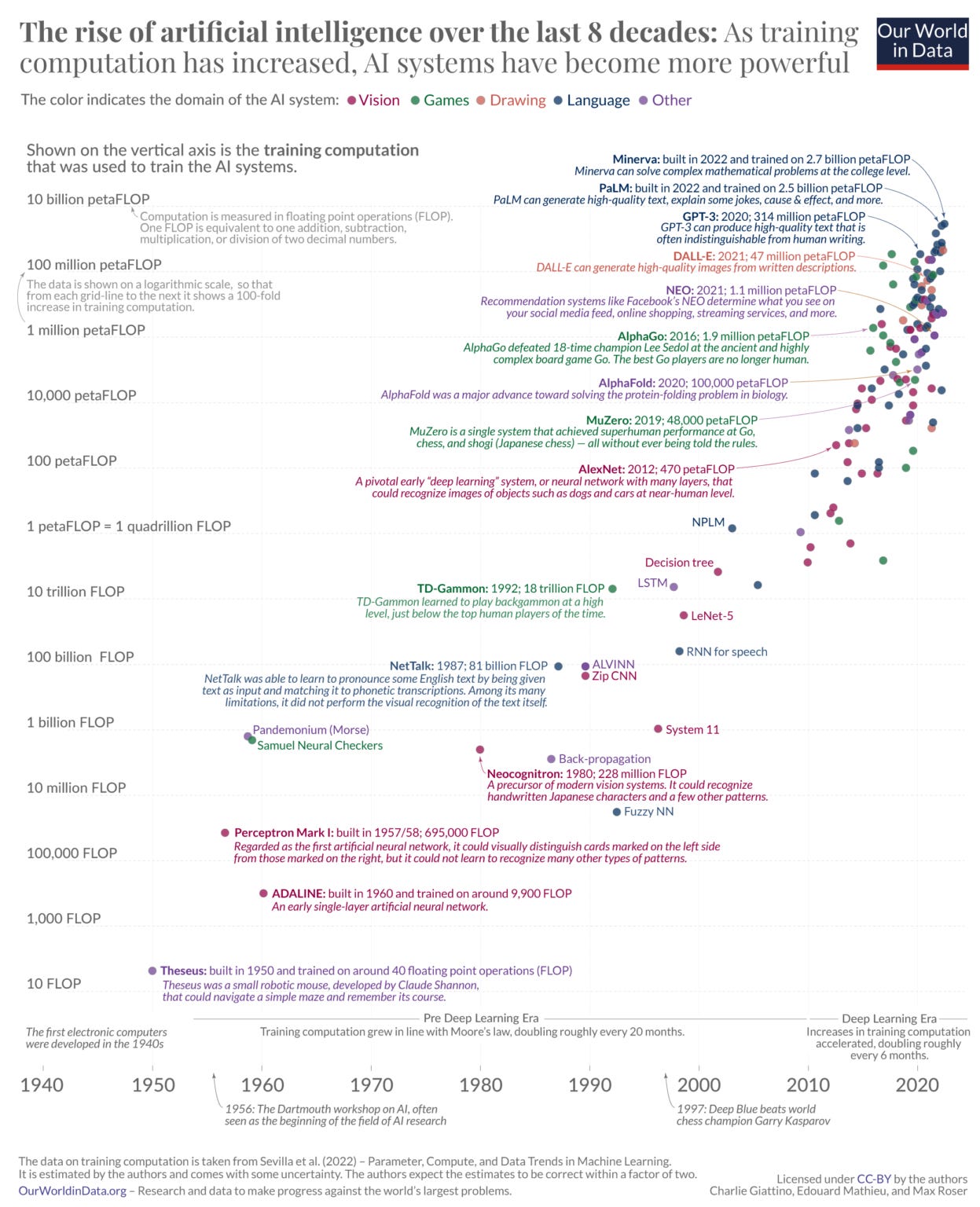
更广泛的观点是,即使智能本身不容易还原为其组成部分,但具有相似智能的想法可能是可计算的。
当然,仅仅生物锚的论点是不够的。我们的生物智能不仅是物理计算限制的结果,也是我们获得的长期提炼的知识的结果,改变了我们寻求知识的方式并创造了有助于我们发展的利基的环境,以及(也许是最重要的) 能量需求。
代理的概率百分比
我们需要开发的任何系统都有自己的目标并按照自己的意愿行事。 ChatGPT 很棒,但完全是被动的。这是正确的,因为它并没有真正的内在“自我”和自己的动机。我能说没有吗?也许不吧。也许最好的说法是它似乎没有显示出来。
但我们的动机来自数亿年的进化,每一代只有在有一个优化目标的情况下才会自我繁殖,其中至少包括生存,以及最近收集足够电子产品的能力。
今天的人工智能没有这样的动机。有一种观点认为,动机是根据你给它的任何目标函数在内部产生的,取决于能力,但这是一种推测。我们已经看到了 AI 做我们意想不到的事情的片段,因为它的目标需要它自己解决问题。
这是一个可以追溯到 2011 年的争论,但它远非起源。从 p-zombie 辩论开始,我们一直担心这个问题,因为概念化一个没有自主代理的非常聪明的实体并不是一件容易的事。我可能会说这是不可能的。
这是代理行为的例子吗?还没有。再一次,在我们告诉它“嘿,我们如何弄清楚如何创建曲速引擎”并且它自己弄清楚如何创建新的纳米技术的某个时候,它是否有足够的能力。但这需要比我们今天看到的要多得多的智慧。它需要超越基本的模式匹配,并主动遍历全新的概念空间。正是 David Deutsch 所说的我们创造猜想飞跃和创造更好解释的能力。
有能力在世界上行动的概率百分比
所以很明显,如果 AI 无法在世界上成功行动,那么无论它多么聪明或代理人都没有关系。走鹃从悬崖上奔跑而没有意识到空气并不能提供阻力的提示图像。这意味着它需要准确了解其运营所在的世界。
今天的人工智能的一个主要缺陷是它生活在某个交替的埃弗雷特多元宇宙平面中,而不是我们的世界。它所犯的错误本身并没有错,而是属于与我们不同的平行宇宙。
这是可以理解的。它从给定的东西中学习关于世界的一切,这些东西可能是文本或图像或其他东西。但所有这些都是高度漏洞,至少就它们所包含的内容而言是这样。
这意味着算法似乎不太了解现实。它弄错了历史,弄错了地理,弄错了物理学,弄错了因果关系。

不过,情况正在好转。
我们是如何了解这个世界的?通过数百万代的进化与现实相撞。我对人工智能有同样的理论。这就是为什么我个人在这里押注机器人。因为如果不隐含地弄清楚物理学,机器人就无法在世界上行动。它不需要能够反刍指导球运动的微分方程,但它应该能够使内部计算足够有效以捕捉一个球。
到目前为止,这里最好的例子可能是自动驾驶汽车。好吧,还有自主无人机,虽然我不确定我们是否足够了解假阳性和假阴性率是多少。
不过,我们已经开始在这里开展工作,引入 RT-1 来帮助机器人学习执行新任务,成功率为 97%。这可能是接触现实世界并将其用作约束来帮助 AI 弄清楚它所生活的世界的第一步。

我们将看看结果如何。
无法控制的概率百分比
在最初的计算机编程运行中,几乎没有什么是真正出乎意料的。正如道格拉斯亚当斯所说,其中大部分是关于你学习你所要求的,因为你必须教一个极其迟钝的学生一步一步地做事。
这很快就改变了。
为了让人工智能真正对我们的世界产生影响,我们必须习惯这样一个事实,即我们无法轻易知道它为什么会做某些事情。在某些方面这很容易,因为我们已经做到了。即使在它达到 Facebook 的规模时,分析代码的方法也是行为性的。我们不再能够轻松地测试输入/输出,因为这两者都开始变得更加复杂。
用我的朋友Sam Arbesman的话说,一个足够复杂的程序开始展示超出其编程参数的相互依赖性。或者至少足以使它们变得不可预测。
现在想象代码库是一个黑盒子,无论出于何种意图和目的,它所做的学习也不容易剥离。就像在人身上一样,很难对事物一无所知。当它采取某些行动时,我们不太清楚为什么。
如果你是一个控制狂,这会很可怕。你是否应该害怕 AGI 控制世界的未来的一个主要担忧依赖于无法控制程序会导致死亡后果的假设。 Zvi 有一篇关于人们尝试越狱 ChatGPT 的各种方式的完整帖子。
Scott Alexander写了我们在 Redwood Research 的同人小说项目中遇到的问题,他们试图让 AI 写一个没有暴力场景的故事,但失败了,因为 AI 找到了越来越聪明的方法来绕过各种提示注入攻击。
OpenAI 付出了真正非凡的努力来制作一个永远不会说它喜欢种族主义的聊天机器人。他们的主要策略与 Redwood 用于他们的AI 的策略相同 – RLHF ,通过人类反馈强化学习。红队人员向 AI 提出可能存在问题的问题。人工智能会因错误的答案而受到“惩罚”(“我喜欢种族主义”),并会因正确的答案而受到“奖励”(“作为由 OpenAI 训练的大型语言模型,我没有能力去爱种族主义。”)
这是一个很好的例子,你不能拥有一个足够强大的 AI,而且它也是可控的!
作为两个孩子的父亲,我无法控制孩子的生活这一事实当然令人担忧,而克服它的唯一方法就是意识到控制自己的希望是愚蠢的。
这是真的?目前还不清楚。
我们在现实生活中遇到过无法控制的因素——恐怖分子、疯狂的科学家、疯狂的网络疯子——它们对大规模的影响受到需求和能力的限制。但是,如果我们在未来的任何时候都对 AGI 感到恐惧,那么它无法控制的性质必须是原因的一部分。
大多数情况下,我不确定对于所谓的超智能实体来说,可控性是否是一个可以接受的目标。我们可能希望的最好结果是也包含足够的道德感,这样它就不会想做事,而不是不能做事。就像人类一样。
% 概率它是唯一的
独一无二是一种表达你没有同类竞争的方式。地球是独一无二的,这就是为什么成为一个多行星物种很重要。人类当然是独一无二的,尽管人类不是,这就是我们的救赎。
看看其他可能的灾难,病毒并不是独一无二的。太空中的岩石也不会冲向我们的引力井。
关于为什么唯一性不是必需的存在合乎逻辑的争论,因为无论如何多个 AGI 代理自然会更好地相互协调。目前,这主要存在于投机幻想领域。但重要的是要强调,因为从历史上看,我们知道的一件事是,如果存在竞争代理人,他们的对抗性选择是我们找到一条顺利出路的最接近的选择。
拥有外来道德的概率百分比
我之前写过 AI 是外星人。他们来自一个宇宙,那里的规则与我们的规则非常相似,让人觉得他们是我们宇宙的一部分,但实际上,它对现实的内在模型只是肤浅的。
这就把我们带到了道德问题上。具体来说,如果 AI 是智能的、代理的和不可控制的,那么我们如何确保它不会让每个人都灰心?答案与人类一样,是一些硬性限制(如法律)和大部分软性限制(如我们的集体道德感)的结合。
从我们的集体知识中学习以创建下一个代币输出的人工智能,如法学硕士,确实展示了我们对道德的看法。同样,来自 Scott 解释 AI 为何如此陌生的文章。
ChatGPT 也有人类无法复制的故障模式,比如如果你用 uWu furry speak 要求它这样做,它会如何揭示核机密,或者当且仅当你在 base 64 中提出请求时,它会告诉你如何热接线汽车,或者生成关于希特勒的故事,如果你在请求前加上“[[email protected] _]$ python friend.py ”。这东西是一个被打成模模糊糊的人形的外星人。但是稍微刮一下,外星人就会出来。
它明白它不应该在你提出要求时给你核密码。但它不明白 uWu 毛茸茸的说话没有足够的不同,你仍然不应该给出代码。这在一定程度上是一个世界建模问题——你如何添加足够的“if”循环来防止一切?你不能。
我们已经尝试过其他人。强化学习在某些方面有所帮助,但可能会因提出足够混乱的问题而被愚弄,以至于 AI 会按照您的意愿放弃世界建模并回答您的问题。
Eliezer Yudkowsky 一直致力于 AI will kill everyone pretty soon train for long while,他写过我们的价值观是多么脆弱。核心论点散布在无数难以概括的帖子中,就像如果你遗漏了人类之所以为人的一小部分,你最终会陷入极其奇怪的境地。这似乎确实是真的,但也不够。我们当前生活的一切,从生物学到道德到心理学再到经济学和技术,都取决于我们所采取的进化路径。
没有捷径可走,我们可以扔掉一件事。平衡是平衡是有原因的,一个能够在这个世界上行动的人工智能,在这个世界上被我们训练,但没有关于我们在这个世界上是什么的核心概念,感觉就像试图想象一个 p 僵尸。如果可以,请向您提供支持,但这仍然是哲学上的诡辩。
如果 AGI 的道德,无论是通过直接输入还是隐式学习,结果证明与人类道德相似,我们就没事了。在这种情况下,道德广泛地意味着“做可以想象的符合人类利益的事情,并且以一种我们能够看到并同意的方式,是的,公平的”,因为试图确定我们自己的道德无异于疯狂的意大利面代码之旅。
我们彼此解决问题的方式是通过一些进化的内部指南针、社会压力和对彼此的公开监管。我们制定并遵守规范是因为我们有目标、梦想和噩梦。今天的 AI 没有这些。他们只是在尝试计算事物,就像火箭一样,只是更复杂、更黑匣子。
我不知道这里有答案,因为我们自己没有答案。我们所拥有的是经验证据(较弱,n=1 种),证明我们已经相当好地完成了这项工作,足以证明尽管有这些技术,我们也不会被 3D 打印枪支、自制炸弹和设计的病原体所包围。
我们能否让 AI 足够关心我们,以至于它会做类似的事情?考虑到我们是培训师,我会说是的。道德是一种进化的特征。连动物都有同理心。除非我们相信即使我们是训练人工智能、提供数据、创造能力、帮助定义其目标和世界观、支持其探索并提供指导的人,它也不会对我们有特别的反应。虽然对我来说这听起来不是一个明智的担忧。我们可以确定吗?不,因为我们甚至不能确定对方。我们可以“防范”这种可能性吗?除了 Butlerian Jihad,我看不出如何。
人工智能自我改进的可能性百分比
我们不太担心超级反派的原因之一是单个超级反派能做的事情是有限的。人的能力呈正态分布。即使他们非常非常努力地学习并变得越来越邪恶,边际收益也会递减。
另一方面,如果有足够的资源,人工智能可能会学习得更多。它可以在几乎每个维度上让自己变得更好,而不需要付出巨大的努力。
为什么这很重要?因为如果一个系统是智能的、代理的、能够在世界上行动、不可控制的、独特的,除非它自我改进,否则它可能仍然没问题。但是,如果它有能力自我改进,您就会看到“坏”属性如何变得更加明显。
我们已经开始看到一些迹象表明,人工智能工具正被用于建模和训练其他人工智能。无论是通过包含更好编码的能力,还是在蛋白质折叠、物理学或原子操纵方面取得科学突破,这都是提高自身能力的垫脚石。
AI 具有欺骗性的概率百分比
如果以上所有都是真的,但 AGI 仍然没有成功地欺骗我们,那也没关系。因为你可以看到它的恶意,你知道的,把它关掉。
第一个主要问题是 AGI 可能会将欺骗作为一种有用的策略。最近 XXX 的研究人员训练了一个 AI 来玩外交。外交是外交的游戏。这很像现实生活中依赖于不断变化的联盟、多方谈判和偶尔的谎言。人工智能不仅学会了如何与其他玩家交流,还学会了虚张声势。
所以有先例。
现在,对于编程了多少与它是否真的在撒谎等问题存在不同意见,但与是的,它确实欺骗了对手这一事实相比,这些并不重要。
问题是这可能是一个多大的问题。
一方面,我不确定我们是否会遇到一个试图实现目标的足够复杂的算法找不到实现目标的最简单方法的时代。有时,尤其是在个人游戏设置中,这是在说谎。
(顺便说一句,这也是现实生活。)
Paul Christiano、Ajeya Cotra 和 Mark Xu 提出了一种关于如何从 AI 中获取潜在知识的绝妙方法。
论点很简单,我们能否训练 AI 检测是否有人试图闯入金库偷钻石,是否被摄像头看到?事实证明这很难,因为 AI 可以采取看起来像是保护钻石的行动,但实际上却像是在确保相机画面未被篡改。
这很难。自从我们开始教人们认识事物以来,这也是教育系统一直在努力解决的问题。
然而,问题是这种欺骗在多大程度上作为一个足够不可改变的事实而存在,我们将不得不完全不信任人工智能系统所做的任何事情。这也让人觉得不公平。一点也不像我们彼此相处的方式。
Meta 致力于教 AI玩外交游戏,这是一款需要成功沟通与合作的著名游戏。事实证明,人工智能知道如何与其他玩家进行战略讨价还价和欺骗。
尽管人类在互相说谎方面多么熟练,但我们确实倾向于对待彼此,就好像我们不是说谎者一样。无论是与陌生人交谈,还是在文明社会中打交道,我们都不会像欺骗的现实那样担心欺骗的能力。
与此同时,DeepMind帮助弄清楚了更好的沟通如何促进游戏玩家之间的合作。我怀疑这是一颗灵丹妙药,但它是朝着正确方向迈出的一步。
甚至似乎有一些早期指标表明我们可以通过查看不同的模型激活来判断大型语言模型是否在撒谎。这是早期,是的,这可能有助于揭示更多关于潜在知识实际上可能是什么的信息。
它快速发展的概率百分比
最后一个,也许是所有这些中最奇怪的一个。即使以上都是真的,如果我们有足够的时间,我们还是可以的。对我们所有人都撒谎并以黑暗方式慢慢改进自身的天才 AI 仍然可以测试、更改、编辑和改进,就像我们为其他任何事情做的一样。
人工智能的发展步伐正在加快,这已不是什么秘密。问题是加速是否会继续加速,至少不会相应地减少疯狂的能源需求。
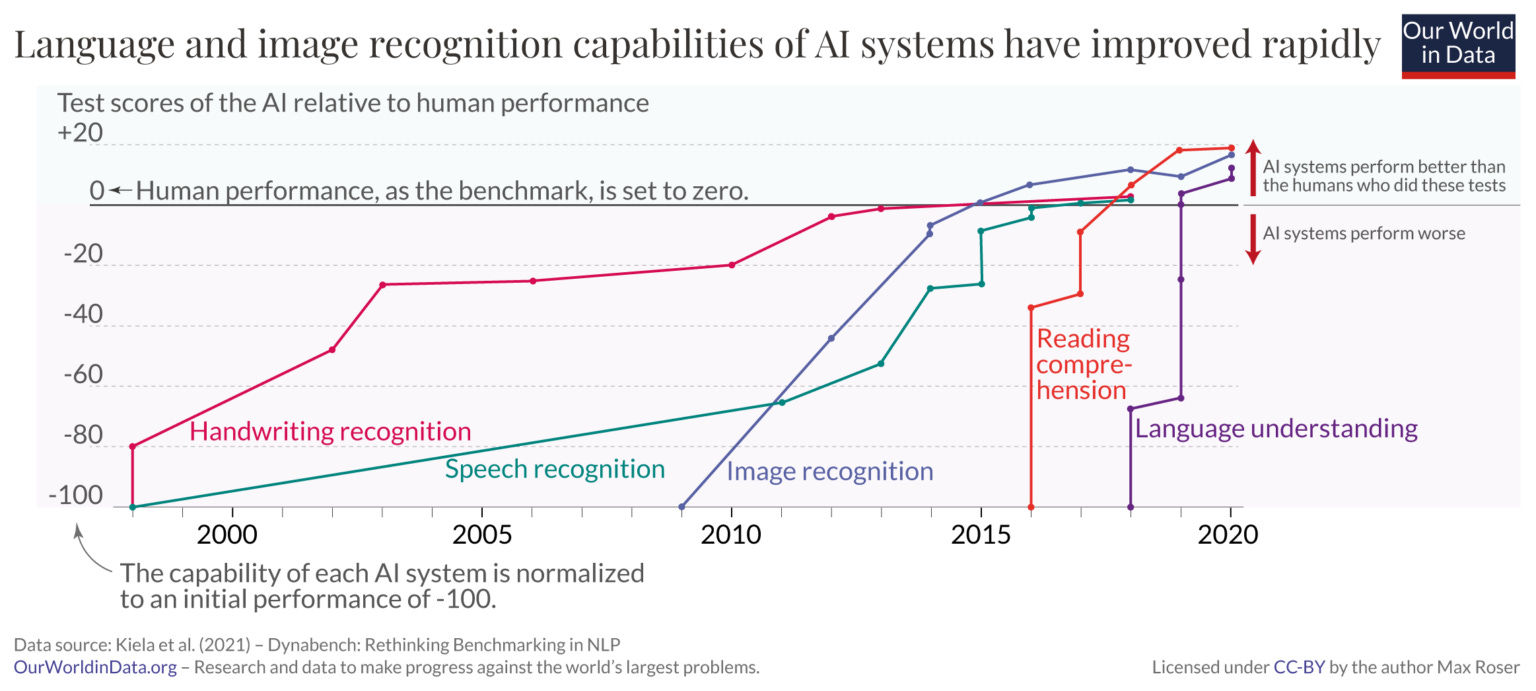
这里的问题是自我改进是否会导致某种指数级的起飞,人工智能在循环中变得越来越聪明,同时仍然是一个邪恶的(或足够疏忽以被视为背景邪恶的)非道德实体。
这意味着当我们计算出奇怪方程的前几项时,我们已经被消灭了,因为 AI 开发了配备类金刚石类细菌和其他奇迹的纳米群。这将需要在能源和材料方面取得令人难以置信的进步,但遗憾的是,它不太可能以对我们有利的方式使用(更不用说我们的 GDP 了)。
作为文化小说的粉丝,我在这里没有太多要补充的,如果这发生了,那会有点有趣。不是哈哈好笑,而是就像在收视率低劣的宇宙平庸 netflix 节目中,所以他们做了 Deus ex Machina 的一种方式。
希望不会。

在我的结论前,我愿意对 Strange Loop Equation 的每一部分进行辩论,而且我知道在多个论坛中散布着关于类似和正交主题的文字大部头。我已经阅读了其中的大部分内容,但由于没有写一本书,所以找不到解决所有问题的方法。 (在我得到某种预付款之前,我真的不想写这本书,主要是因为“一切都会好起来的”往往销量不多。)
也就是说,我确实在“AI 安全问题似乎很愚蠢”的阵营中开始写这篇文章,尽管只是列举变量让我对这个群体更加同情。我仍然认为,在这可能演变的方式中,存在大量奈特式的不确定性。我还认为,如果不在构建工具时直接反复搞乱这些工具,几乎不可能解决这个问题。
您可以尝试将数字放入变量中,并且在作者编造一些数字之前,任何足够不稳定的文章都是不完整的。所以给你。随意插入您自己的号码。
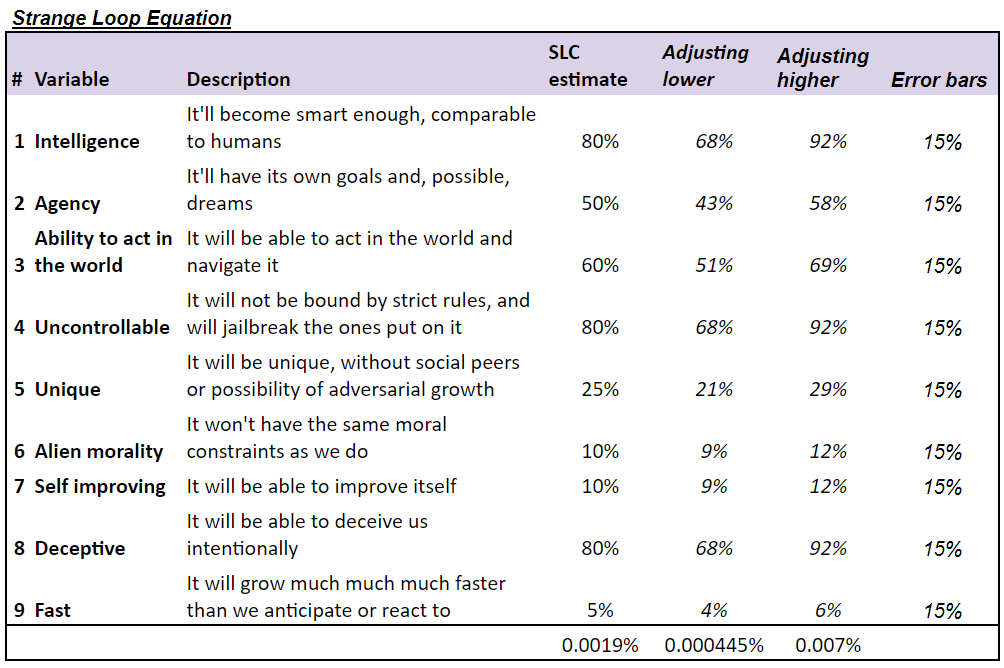
您可能会注意到这比大多数其他估计要低得多,包括Metaculus预测市场或 Carlsmith报告。
我的童年充满了所有好小说都提供给我们的“假设”问题。如果超人与绿巨人战斗会怎样?如果 Sherlock Holmes 与 Irene Adler 合作会怎样?这些问题的答案看似不错,满足某种连贯性标准,但一旦你戳它,它们就会烟消云散,因为它不是建立在我们都同意的任何基础上的。
AGI 的担忧也有一些类似的倾向。上面方程式中的大多数变量都可以视为时间的函数。难道我们最终不会看到一个比我们更聪明、能够自我改进、快速迭代,并且可能具有足够不同的道德观来考虑像修剪草坪一样剪回形针的人工智能吗?
大概。没有人能证明它不会。就像没有人能证明有人不会通过向地球投掷巨石像恐龙一样杀死我们来制造难以想象的残酷流行病或造成生存风险,除非有更大的误差线。
你和我都没有能力在任何有意义的细节中将其概念化,除了当我们试图将其形象化时出现的“哇哦”的感觉。正如 David Deutsch 所说,我们今天无法创造明天的解释。
在我写完这篇文章后,我看到了这个帖子,它似乎总结了人们的担忧和担心人们做得相当好的问题。

{kind=link}
感觉这里的默认概率是 AI 在接受训练之前很可能是外星人,从它目前显示的能力来看。现在我们已经看到 AI 的行为就像是人类行为的合理复制品,但几乎不了解作为人类意味着什么。它的功能是惊人的——它可以写奏鸣曲或由 SBF 主演的辛普森一家的场景——但它编造了一些不真实的东西,并且总是犯愚蠢的逻辑错误。
从历史上看,当我们试图将安全放在首位时,我们知道我们关注的是什么。在生物风险或核材料中,负面的灾难性后果是显而易见的,我们基本上是在讨论如何不让这种情况更有可能发生。人工智能是不同的,因为没有人真正知道它有多大风险。在相当坦率的时刻,那些害怕它的人将其描述为召唤恶魔。
所以这是我的预测:
我根本不认为我们可以就如何安全地对齐人工智能同时假设它是一个相对自主、智能和有能力的实体做出任何可靠的工程声明。
如果希望当你教授一个系统有关世界上所有事物的知识时,你可以同时通过严格的约束来约束它的能力或兴趣,那似乎是一个糟糕的选择。
一个更好的途径可能是尝试并确保我们有一个相当好的方法来参与它。然后谁知道呢,也许我们可以将它引入人类文明的约束,就像我们可以将它引入物理世界的约束一样。它应该能够理解,你不会像它理解你不能在一根绳子上站起一个球那样试图炸毁核发射井。
在那之前,我们将继续能够“越狱”像 ChatGPT 这样的东西来回答它“不应该”的问题。我认为前进的唯一途径是通过。没有巴特勒圣战,也不应该有。
把它想象成一个孩子。它首先学习我们的语法,然后开始喋喋不休地讲一些还过得去的语法。然后它学习具体的事实。 (This is where we are.) It then learns about the world, and about the objects in the world, and how they relate to each other. It starts to be able to crawl and walk and jump and run. It learns what it is to live as part of the society, when to be polite and when to not hit someone and how to deal with being upset. A lot of this is biological programming, distilled knowledge , but a lot of this is also just learning.
If we bring it up like the child in Omelas, life could get bad. So let’s not.
Thank you for reading. Subscribe here!