当您在社交媒体上分享链接时,平台会获取页面并在您的帖子中包含预览:
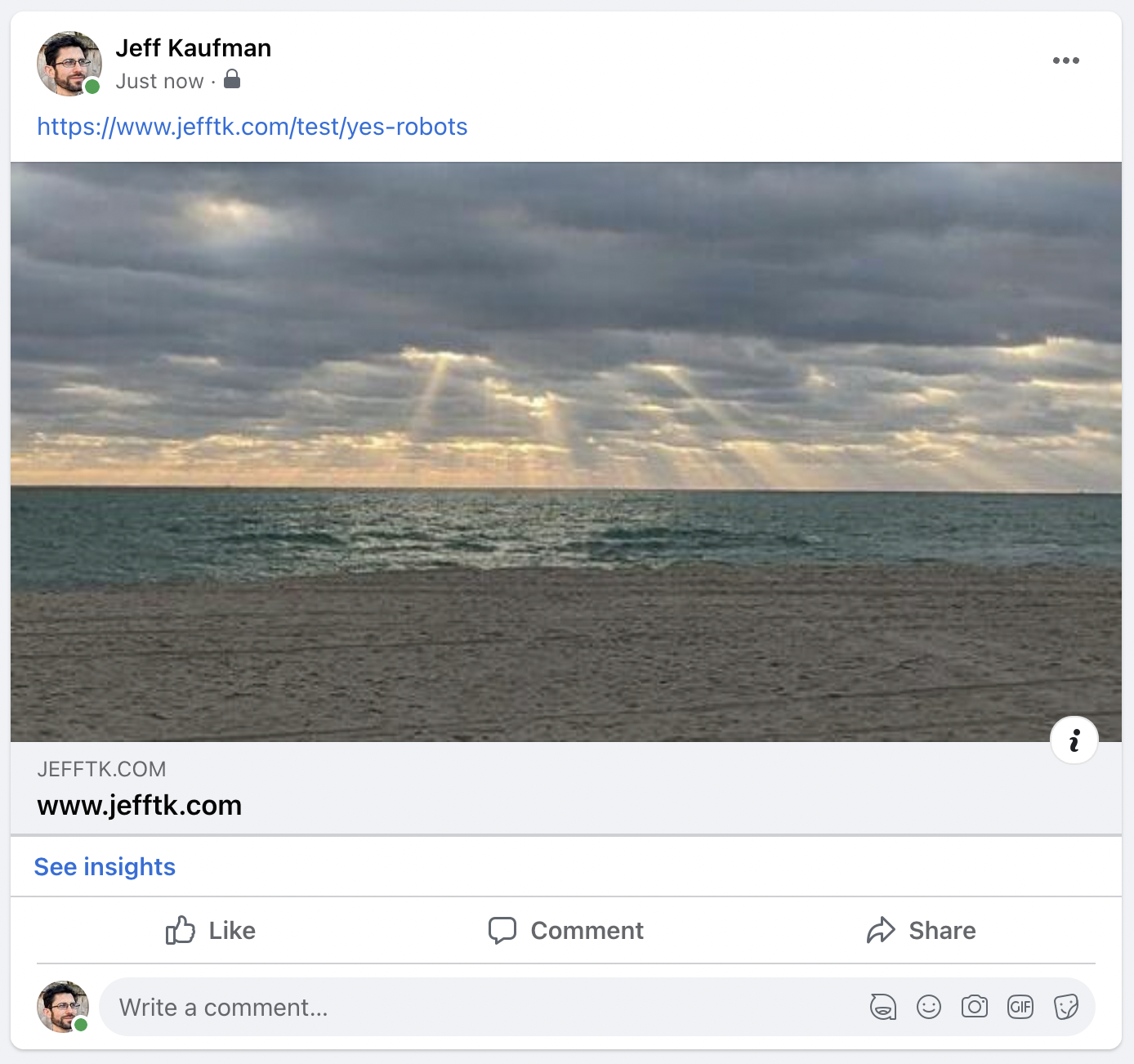
即使这种情况自动发生,系统也不遵守 robots.txt 排除规则 ( RFC 3909 ):我在我的robots.txt中排除了/test/no-robots但这并不能阻止它:
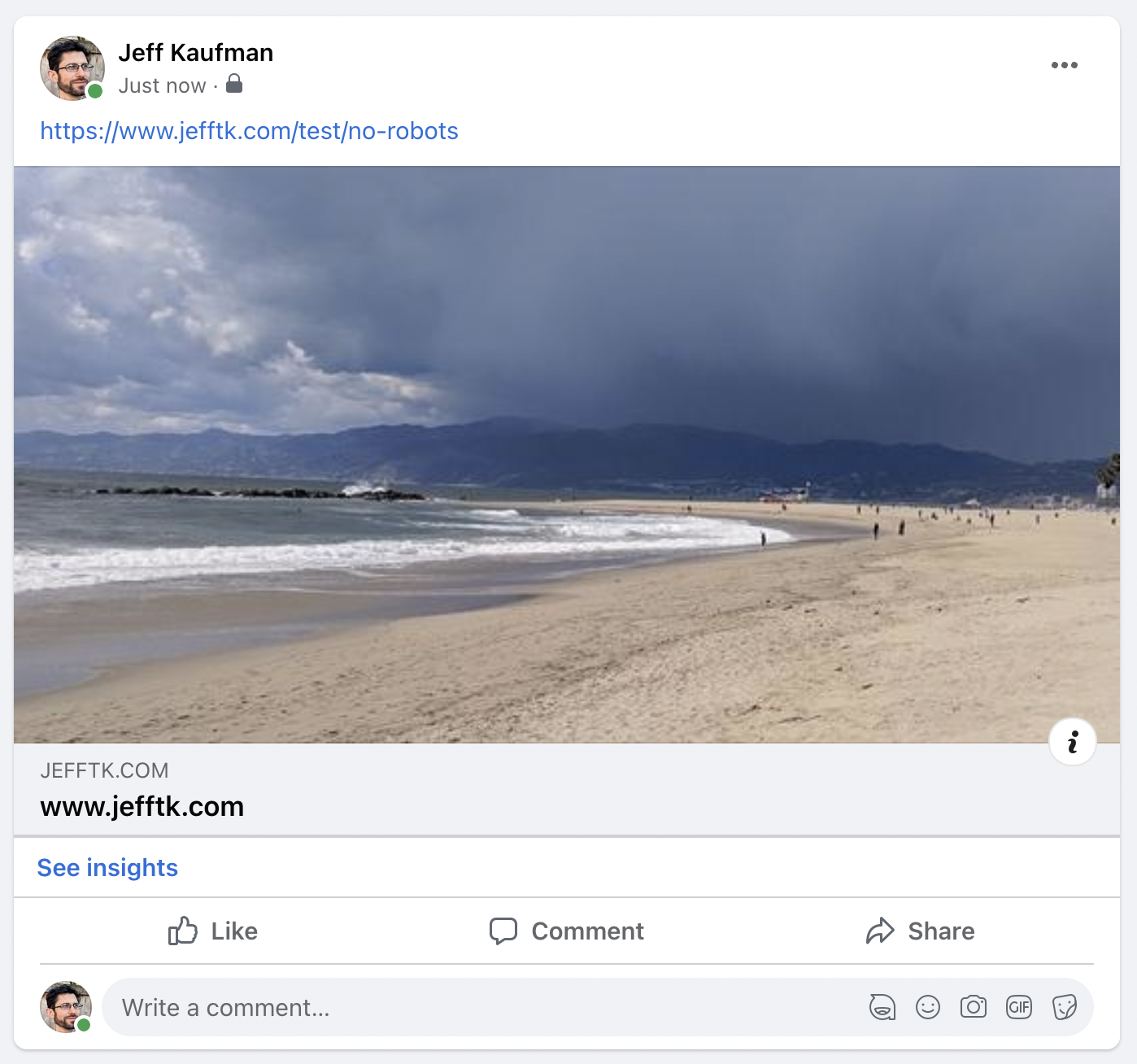
我什至没有在我的日志中看到对robots.txt的请求。但其实没关系!机器人排除标准适用于“爬虫”或自动化代理。当我共享链接时,我希望包含预览,因此获取页面的机器人充当我的代理。这也是为什么WebPageTest和PageSpeed Insights也可以忽略robots.txt的原因:它们根据用户的请求获取特定页面,以便它们可以衡量性能。
这让 Mastodon 陷入了尴尬的境地。他们确实希望包括预览,因为他们正在尝试做所有标准的社交网络事情,如果他们尊重robots.txt ,许多您希望能够预览的网站将无法工作。他们也不希望原始实例生成预览并将其包含在帖子中,因为它容易被滥用:
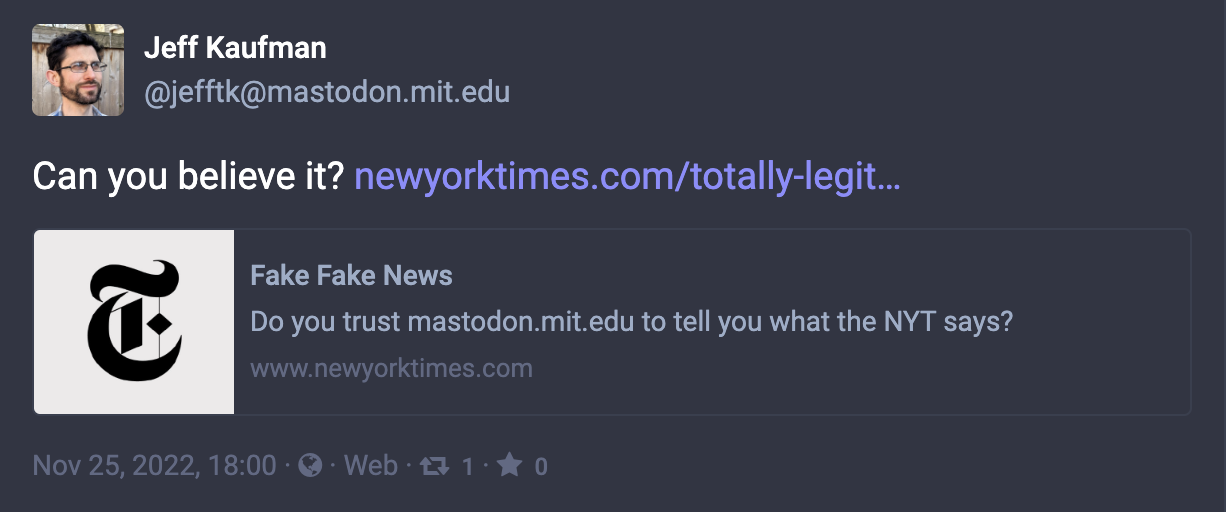
您可以相信mastodon.mit.edu @[email protected]所说的内容,但不能newyorktimes.com所说的内容。
Mastodon 采用的方法是让每个实例为每个传入链接生成链接预览。这意味着虽然在 Twitter 或 Facebook 上共享一个链接可能会给你一个预览的自动页面浏览量,但在 Mastodon 上它会为链接联合到的每个实例提供一个页面浏览量。对于被广泛关注的帐户共享的链接,这可能意味着数千个链接预览请求会到达服务器,而且我现在还认为此流量来自自动代理。
我不确定 Mastodon 的正确方法是什么。让链接预览获取器遵守robots.txt (问题 21738 )将是一个好的开始。 [1] 从长远来看,我认为在撰写帖子时包括链接预览以及通过联合处理滥用行为似乎应该与 Mastodon 的其余滥用行为处理一样有效。
(上下文)
[1] 这不会只是增加一个额外的请求并进一步增加网站的负载吗?不:每个人都建立网站以非常便宜地提供服务robots.txt 。然而,服务 HTML 通常涉及脚本语言、数据库查找和其他缓慢的操作。
原文: https://www.jefftk.com/p/mastodons-dubious-crawler-exemption