在布莱恩·卡普兰(Bryan Caplan)的著作《反对教育的案例》 (我之前在这里写过)中,他认为教育带来的工资溢价主要是由于拥有教育资格表明某人可能是一名优秀的员工。这是反对人力资本论点的论点,该论点声称人们实际上是通过上学/大学学习有用的技能,这就是具有教育资格的人赚更多钱的原因。您可以在此处阅读对本书的有用评论,以更详细地总结卡普兰的论点。
在本书的开头,他承认了一个决定:当没有可用的实验证据时,他将信任带有控制变量的普通最小二乘法,而不是“高科技替代品”。这是什么意思? “普通最小二乘法”(OLS)是指一种测量两个变量之间关系的技术。例如,下图显示了体重和身高之间的关系:
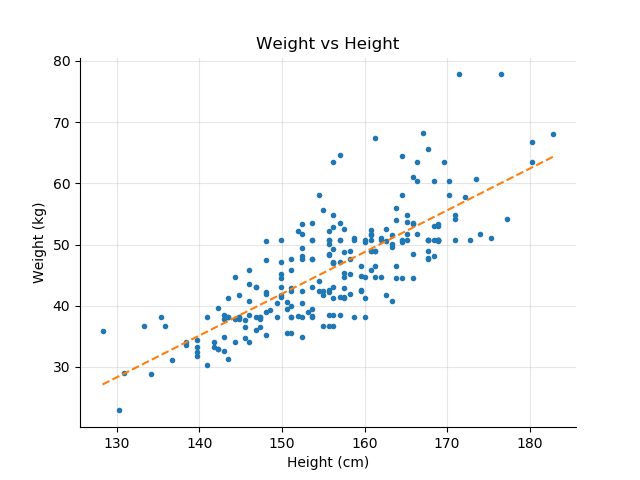
因此,OLS/线性回归可帮助您找到两个变量之间的关联。使用“控制”变量可以帮助您尝试确定关系是否是因果关系。假设我想弄清楚看歌剧是否会导致某人有高智商。我可能会进行线性回归并发现存在相关性 – 但事实上,当我控制收入时,我发现相关性消失了。有钱的人更喜欢看歌剧,他们的智商也更高。所以,看歌剧和智商之间的关系根本不是因果关系——这两个变量都与收入相关,当我把收入考虑在内时,这种关系就消失了。
卡普兰策略是寻找相关性,并尝试控制我们能想到的一切可能与受过高等教育和更富有/更成功相关的事物。例如,这是《反对教育案例》中相当典型的一段话:
“当研究人员纠正武装部队资格考试 (AFQT) 的分数时,这是一项特别高质量的智商测试,教育溢价通常会下降 20-30%。校正数学能力可能会使天平更加倾斜;最杰出的研究人员报告说,男性的教育溢价下降了 40-50%,女性下降了 30-40%。在国际上,校正认知技能会使受教育年限的回报减少 20%,在所有 23 个研究国家中,仅受教育年限就可以得到明显的回报。”
但是,如果没有可用的实验证据,那么在教育方面,带有控制的 OLS 真的是做出因果推断的最佳方式吗?可能不是。我们可以使用准实验,而不是查看相关性并尝试(并且可能失败)控制我们能想到的一切。这些是如何工作的?最常见的准实验设计之一是回归不连续设计(RDD)。基本思想是,在某些情况下,任意截断可以为您提供与随机对照试验中的治疗组和对照组相当的值。
例如,假设您想衡量成为国会议员对死亡时财富的因果影响。 One way to figure this out would be to compare people who won an election by a tiny number of votes to people who lost an election by a tiny number of votes.仅仅以5票而成为国会议员的人可能与仅失去5票后未能成为国会议员的人并没有特别不同,因此,如果您有足够的例子,那就是只有少数票赢/输的人,你可以分离出成为议员对一个人财富的因果影响。如果您有兴趣,Eggers 的一项著名研究正是这样做的——发现成为一名议员几乎使保守党议员的财富翻了一番(但对工党议员没有影响),如下图所示。
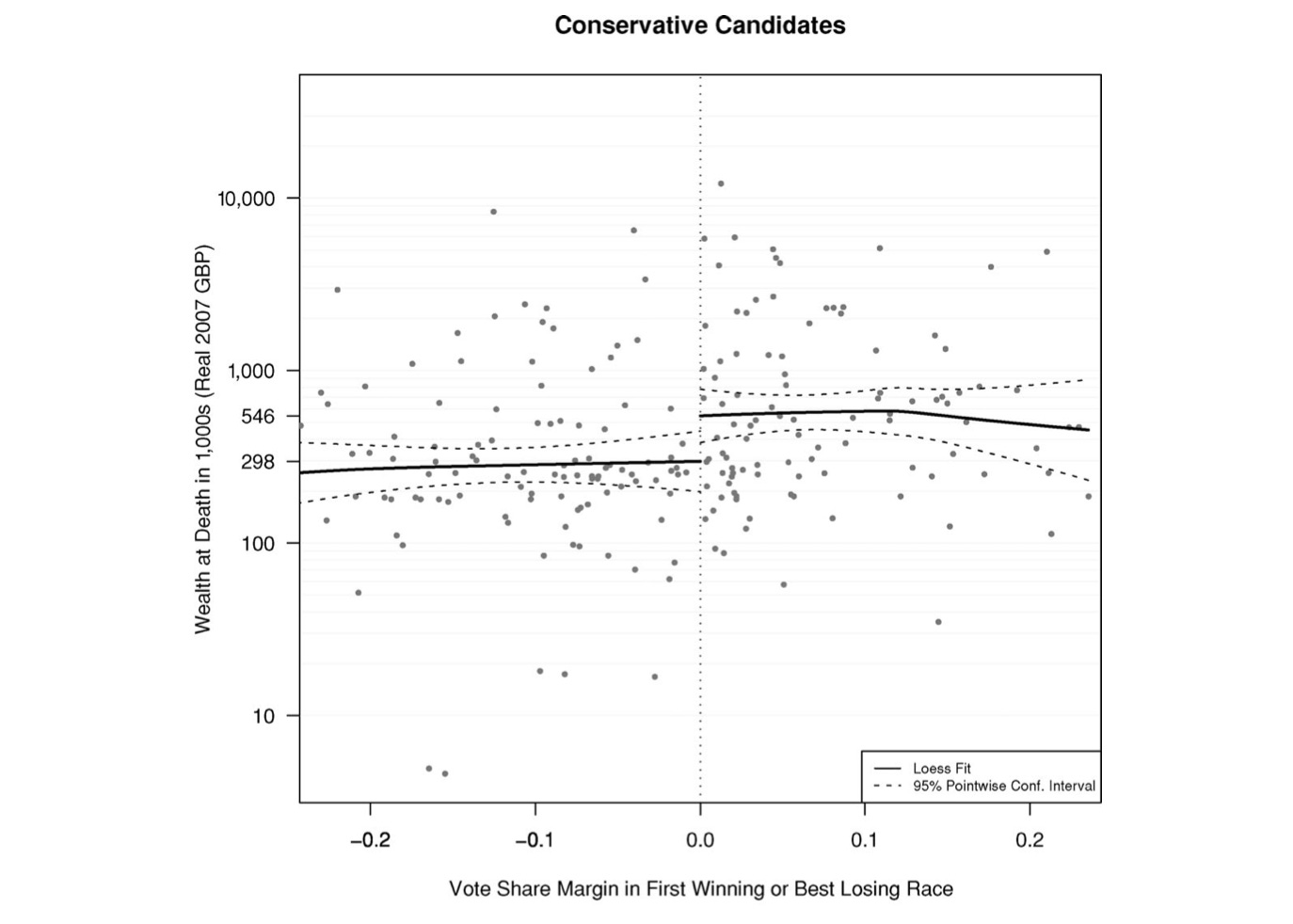
但卡普兰对准实验设计出人意料地持否定态度,声称它们通常很混乱,很容易被操纵。但我认为这很奇怪:许多准实验确实可以很好地复制,并且可能比带有对照的 OLS 复制得更多。在 Alvaro De Menard 的一篇文章中,详细介绍了他如何通过预测哪些社会科学论文将被复制而赢得 1 万美元,他指出,他会为使用回归不连续设计的论文以及使用类似设计的论文分配更高的复制机会称为差异中的差异(尽管他指出某些类型的准实验设计,例如工具变量,不太可能复制)。
回归不连续性设计似乎特别适合隔离教育的因果效应。在某些情况下,新的教育法意味着在某个任意日期之前或之后出生的人接受了不同程度的教育——这意味着您可以通过查看在削减之前出生的人之间的结果差异来执行 RDD -off 和那些在截止之后出生的人。它们还有助于隔离获得资格的影响 – 您可以将刚刚通过期末考试的人与刚刚通过期末考试的人进行比较。
以下是一小部分使用 RDD 的研究样本:
-
Banks 和 Mazzona(2012 年)利用 1947 年英国最低离校年龄的变化,发现一年的教育对老年男性记忆和执行功能有巨大而显着的影响。
-
Ozier (2018)利用这样一个事实,即如果孩子的分数接近全国平均水平,进入公立中学的概率会急剧增加,他发现完成中学后认知能力测试的分数会增加 0.6 个标准差。教育似乎也提高了就业率并降低了女性青少年怀孕的机会——尽管这与信号论点一致。
-
Clark 和 Marotell (2014)使用 RDD 来比较勉强通过和勉强通过高中毕业考试的学生的职业收入——未通过的学生没有获得文凭,但通过的学生获得了文凭(这些是在他们的教育,所以这里的一个很大的影响将使信号论点可信)。他们几乎没有发现存在信号效应的证据,您可以在下面看到 RDD 的可视化。

我并不是要声称我已经阅读了文献并阅读了大多数使用 RDD 的研究,这些只是我发现的前几个(不包括我发现的前几个都使用了 1947 年的立法)第一项与上述用途相关的研究,我没有包括在内,因为它会重复)。而且我很确定有一些使用 RDD 的研究确实发现了工资溢价的强烈信号成分。
但我确实声称这些研究是有用的,特别是它们对于隔离教育的因果效应很有用。特别是对于信号效应,你可以看看那些刚通过高中期末考试的学生和刚刚通过考试的学生。
所以我觉得很奇怪 Caplan 决定更加重视带有控件的 OLS,因为用他的话说,“它易于理解、易于比较且难以操作”。没有提到(在本书的这一部分)使用带有控件的 OLS 来尝试进行因果推断的问题:遗漏变量偏差、对撞机偏差、后处理条件等等。
这些似乎都在这里相关!例如,假设您发现当您控制认知能力时,受教育年限与工资之间的相关性显着降低 – 它 可能是教育提高了认知能力,而认知能力提高了工资,所以控制认知能力是个坏主意。
我对带有控件的 OLS 难以操纵持怀疑态度,我怀疑 p-hacking 在准实验设计中更难。我的愤世嫉俗的部分认为 OLS 论文表明信号比 RDD 论文更重要,因此更认真地对待 OLS 论文的决定并不是纯粹出于对 RDD 方法论的关注而做出的决定,而是我没有真正的证据证明这种愤世嫉俗。如果您认为确实有充分的理由更喜欢 OLS 而不是 RDD,请在评论中告诉我!
原文: https://www.samstack.io/p/quasi-experiments-and-education