我这个周末发布了一个新项目,在 Bellingcat Hackathon 期间构建(我获得了第二名!)它被称为Action Transcription ,它是一个从在线视频中捕捉字幕和文字记录的工具。
这是我介绍新工具的视频:
贝灵猫
Bellingcat将自己描述为“一个由研究人员、调查人员和公民记者组成的独立国际集体,使用开源和社交媒体调查来探索各种主题”。
他们专注于开源情报——令人困惑的是,这并不意味着“开源软件”——这是描述使用公开可用信息来收集情报的术语的一个更古老的用法。
他们在八年的生命中打破了许多令人印象深刻的故事。维基百科有一个很好的清单——重点包括确定Skripal 中毒案背后的嫌疑人。
黑客马拉松的主题是“通用数字调查工具”。目标是构建可供他们的调查人员社区使用的工具原型——其中大多数是在家工作的志愿者,预算很少甚至没有,而且通常技术技能有限(他们可以非常有效地使用工具,但他们可能不习惯编写代码或使用命令行)。
受最近发布的OpenAI 的 Whisper的启发,我决定构建一个工具,可以更轻松地从社交媒体网站上的视频中提取字幕和文字记录。
为什么选择 GitHub 操作和 GitHub 问题?
我对该项目的目标是:
- 帮助人们实现有用的东西
- 让它尽可能便宜地运行——最好是免费的
- 让人们轻松安装和运行自己的副本
我决定使用 GitHub Actions 和 GitHub Issues 构建整个东西。
GitHub Actions 是用于运行 CI 作业和其他自动化的强大服务,但它对于这个特定项目的最佳功能是它是免费的。
我自己花钱没问题,但如果我为其他人构建工具,让他们无需支付任何费用即可运行该工具是一个巨大的胜利。
我的工具需要一个 UI。为了让事情尽可能简单,我不想在 GitHub 本身之外托管任何东西。所以我求助于 GitHub Issues 来提供接口层。
创建新问题时触发的操作脚本很容易。然后这些脚本可以与该问题进行交互——附加评论,甚至在完成后关闭它。
我决定我的流程是:
- 用户打开问题并粘贴到在线视频的链接。
- GitHub Actions 由该问题触发,提取 URL 并使用youtube-dl获取视频(尽管名称如此,它实际上可以从1,200 多个站点下载视频,包括许多在俄罗斯流行的社交媒体服务)。
- 该脚本仅从视频中提取音频。
- 音频然后通过 OpenAI 的 Whisper 传递,它可以创建原始语言的高质量转录,并创建一个令人震惊的好英文翻译。
- 然后将标题写回 GitHub 存储库并作为评论附加到原始问题。
GitHub Actions(尚未)提供 GPU,而 Whisper 使用 GPU 访问速度要快得多。所以我决定在 Replicate 上使用模型的这个托管副本来运行 Whisper。
直接提取 YouTube 的字幕
我与 Bellingcat 的 Tristan 进行了签到会议,以确保我的 hack 不是重复的工作,并获得有关计划的反馈。
特里斯坦喜欢这个计划,但指出直接从 YouTube 提取字幕将是一个有用的附加功能。
除了支持手动字幕之外,事实证明 YouTube 已经创建了超过 100 种语言的机器生成字幕!它们的质量不如 OpenAI Whisper,但它们仍然有用。而且它们是免费的(运行 Whisper 目前要花钱)。
所以我调整了计划,为用户提供两种选择。默认选项将直接从视频提供商提取字幕 – 这肯定适用于 YouTube,也可能适用于其他网站。
第二种选择是使用 Whisper 来创建成绩单和翻译,虽然需要更长的时间,但即使对于不提供自己字幕的网站也能提供结果。
我决定使用问题标签来触发这两个工作流程:使用“captions”标签直接提取字幕,使用“whisper”标签使用 Whisper。
实施
该实现最终成为 GitHub Actions issue_created.yml工作流中的218 行JavaScript-embedded-in-YAML。
我为此使用了actions/github-script – 一个方便的可重用 Action,它提供了一组预配置的 JavaScript 对象,用于与 GitHub API 交互。
代码不是很优雅:我对 Node.js 生态系统不是很熟悉,所以我最终使用 Copilot 进行了相当多的修改以找出可行的模式。
事实证明,字幕可以以各种不同的格式返回。最常见的两种似乎是 TTML(使用 XML)和 WebVTT(一种基于文本的格式)。
我决定将原始字幕文件存档在 GitHub 存储库中,但我只想提取文本并将其作为问题评论发布。
所以我最终构建了两个微小的新工具: webvtt-to-json和ttml-to- json——它们将不同的格式转换为我自己发明的标准 JSON 格式,标准化字幕,以便我可以提取文本并包含它在评论中。
黑客马拉松倾向于鼓励一些相当杂乱无章的解决方案!
结果
这两个问题展示了该工具的最终结果:
第一个特别显示了 Whisper 模型在处理俄语文本并将其翻译成英语方面的出色表现。
添加问题模板
在为上面嵌入的评委录制演示视频后,我为项目添加了最后一项增强功能。
问题模板是 GitHub 的一项新功能,可让您定义用户在创建新问题时必须填写的表单。
令人沮丧的是,这些仅适用于公共存储库。起初我在一个私人仓库中构建了我的 hack,所以我只有在将问题模板公开后才能使用它进行探索。
我创建了两个问题模板——一个用于字幕任务,一个用于耳语任务。
现在,当用户打开一个新问题时,他们可以选择两个模板之一并填写 URL 作为表单的一部分!这是一个 GIF 演示,展示了该流程的实际效果:
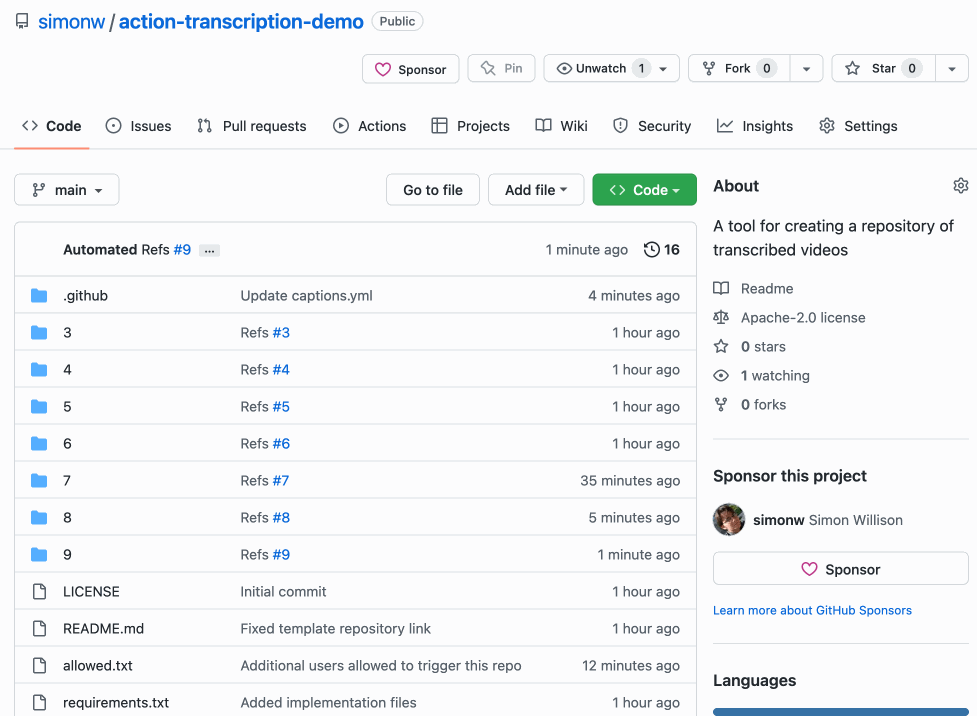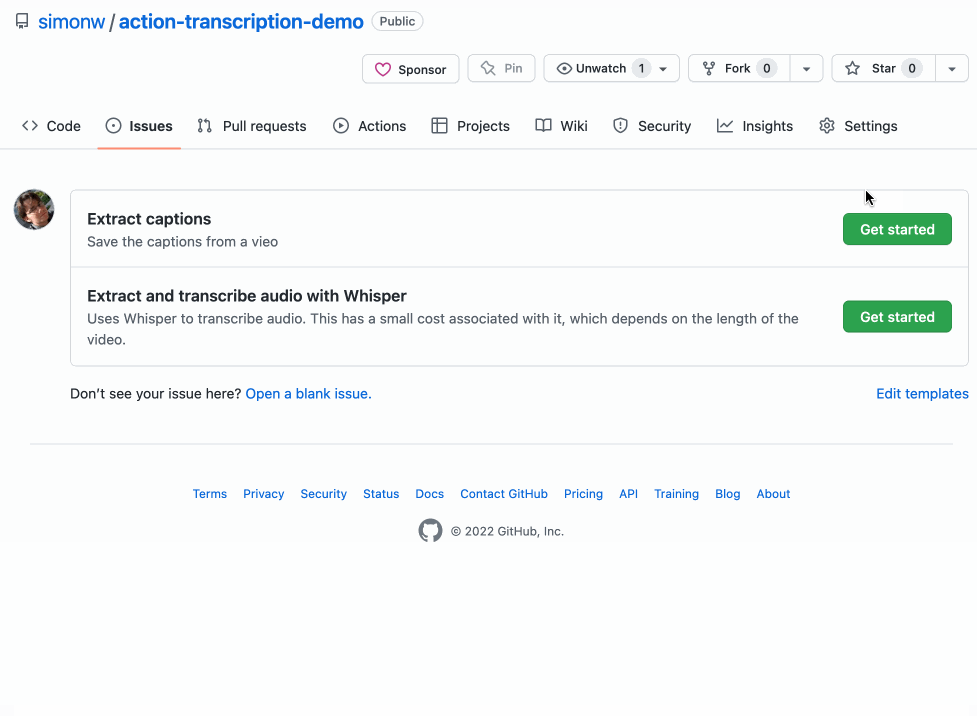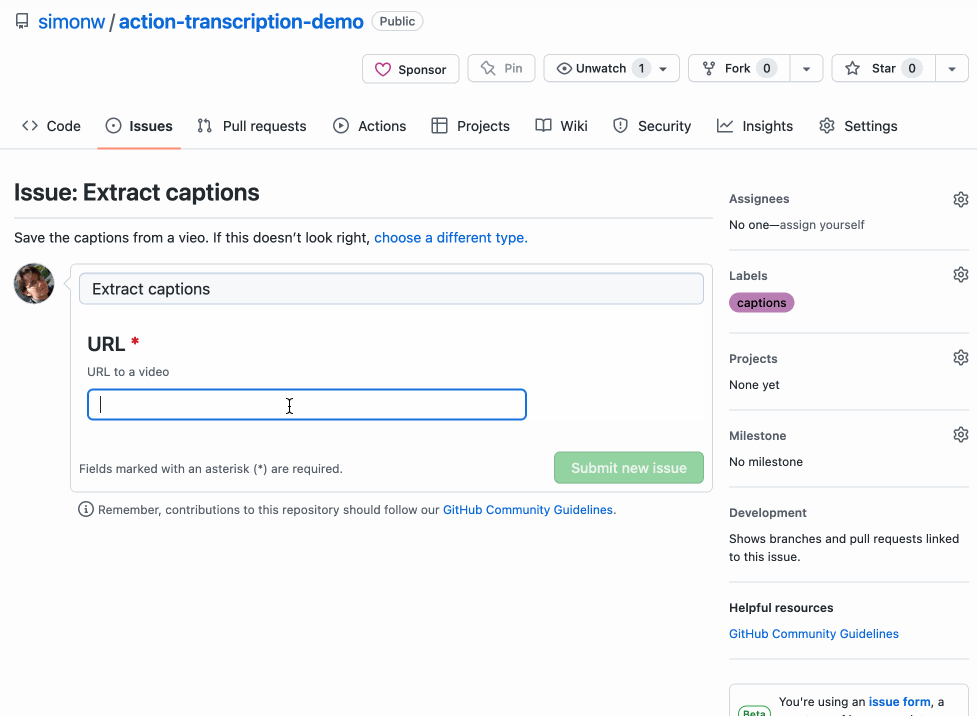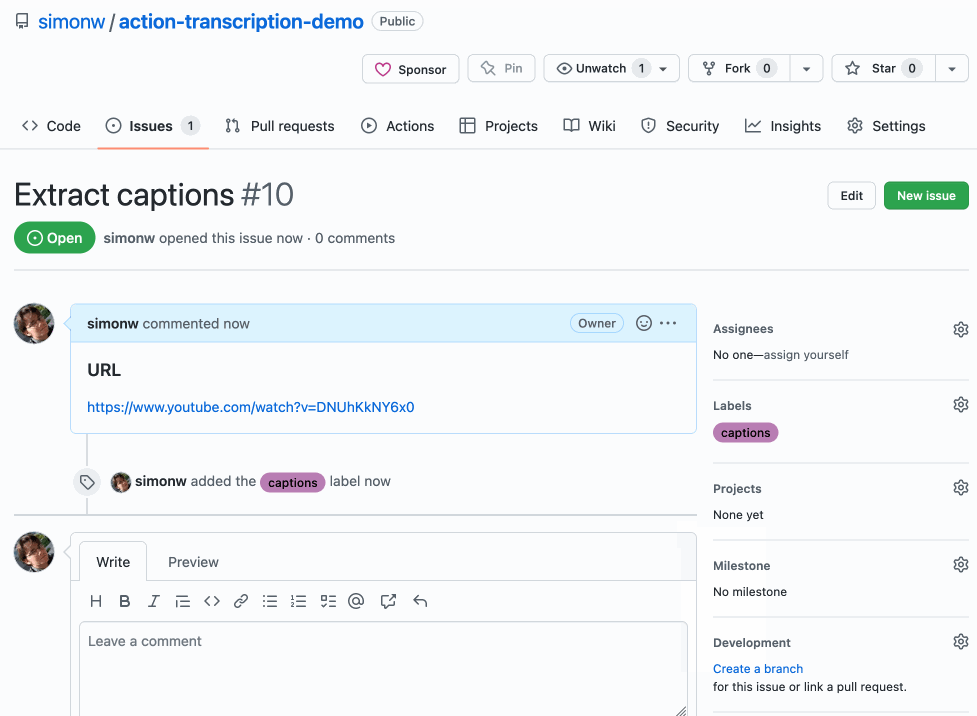
模板存储库
最后一招。我希望用户能够在自己的 GitHub 帐户上自己运行这个系统。
我将simonw/action-transcription 设为模板存储库。
这意味着任何用户都可以单击绿色按钮来获取他们自己的存储库副本 – 当他们这样做时,他们也将获得自己完全配置的 GitHub Actions 工作流副本。
如果他们想使用 Whisper,他们需要从Replicate.com获取 API 密钥并将其添加到他们的存储库的机密中 – 但如果没有这个,常规的字幕提取将正常工作。
我以前使用过这种技术 – 我在这里写过:
GitHub Actions 作为一个平台
我对这个项目的结果很满意。但我主要对底层模式感到兴奋。我认为使用 GitHub Actions 构建工具,人们可以将其克隆到自己的帐户,这是开发复杂的自动化软件的一种非常有前途的方式,人们可以完全通过 GitHub Web 界面独立运行这些软件。
我很高兴看到更多工具采用类似的模式。
原文: http://simonwillison.net/2022/Sep/30/action-transcription/#atom-everything