Make-A-Video是 Meta AI 的一个新的“最先进的 AI 系统,可以从文本中生成视频”。它看起来令人难以置信 – 它确实是用于视频的 DALL-E / Stable Diffusion。它似乎已经在从 Shutterstock 抓取的 1000 万个视频预览剪辑上进行了训练。
我建立了一个新的搜索引擎来探索这千万个剪辑:
https://webvid.datasette.io/webvid/videos
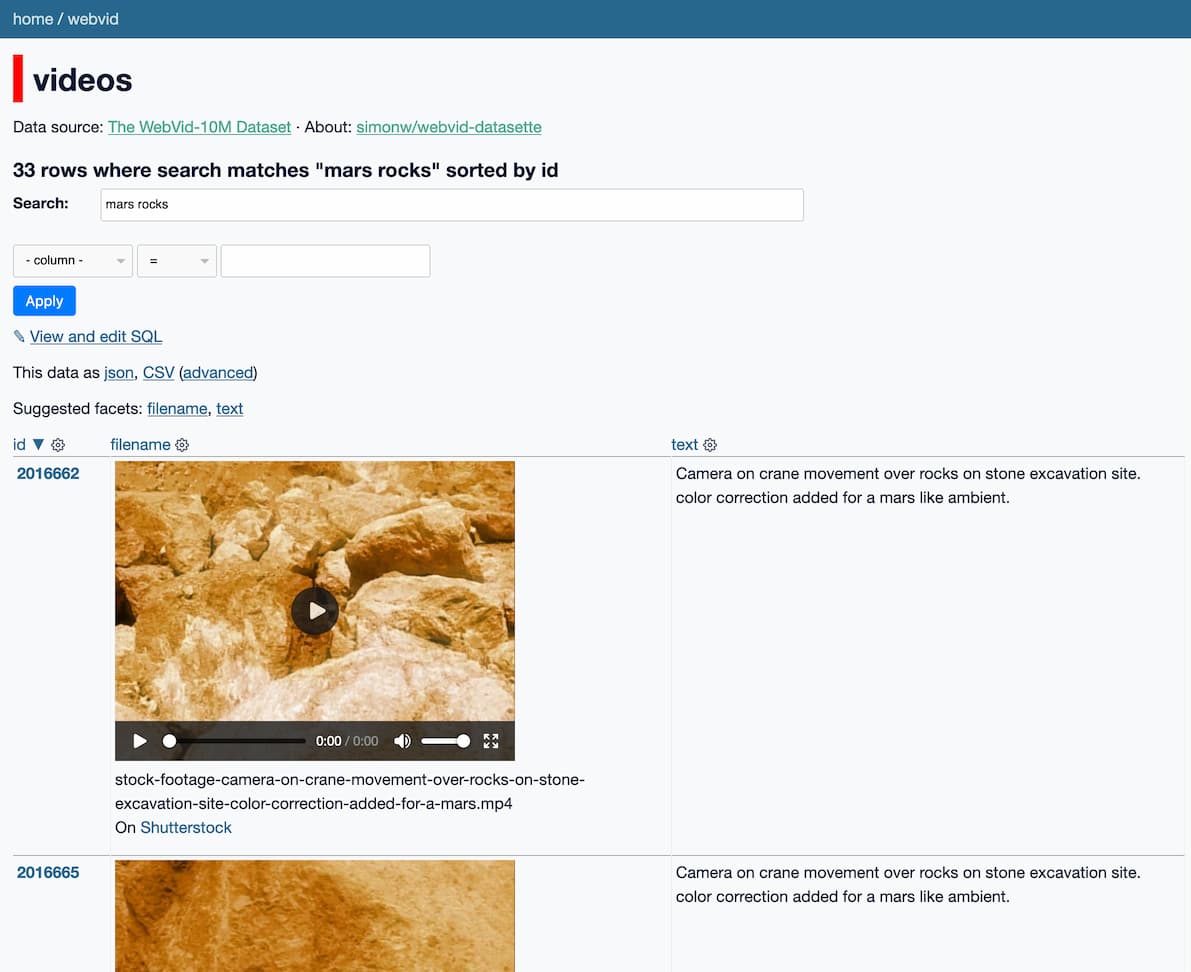
这类似于我几周前与 Andy Baio 构建的系统,用于探索用于训练稳定扩散的 LAION 数据。
Make-A-Video 训练数据
Meta AI描述该模型的论文包括关于训练数据的这一部分:
数据集。为了训练图像模型,我们使用来自 (Schuhmann et al.) 的数据集的 2.3B 子集,其中文本为英文。我们过滤掉带有 NSFW 图像 2、文本中的有毒词或水印概率大于 0.5 的图像的样本对。
我们使用 WebVid-10M (Bain et al., 2021) 和 HD-VILA-100M (Xue et al., 2022) 3 的 10M 子集来训练我们的视频生成模型。请注意,仅使用视频(没有对齐的文本)。
解码器 Dt 和插值模型在 WebVid-10M 上进行训练。 SRt l 在 WebVid-10M 和 HD-VILA-10M 上进行了训练。虽然之前的工作(Hong 等人,2022 年;Ho 等人,2022 年)收集了用于 T2V 生成的私有文本视频对,但我们仅使用公共数据集(并且没有用于视频的配对文本)。我们在零样本设置中对 UCF-101 (Soomro et al., 2012) 和 MSR-VTT (Xu et al., 2016) 进行自动评估。
该 2.3B 图像子集与我之前探索的 LAION 数据相同。
HD-VILA-100M由 Microsoft Research Asia 收集 – Andy Baio 指出这些是从 YouTube 上抓取的。
我决定看一下WebVid-10M数据。
WebVid-10M
WebVid-10M 网站这样描述数据:
WebVid-10M 是一个大规模的短视频数据集,其文本描述来源于网络。视频内容丰富多样。
随附的论文提供了更多细节:
我们在网上搜索一个带有文本描述注释的新视频数据集,称为 WebVid-2M。我们的数据集由 250 万个视频-文本对组成,比现有的视频字幕数据集大一个数量级(见表 1)。
这些数据是按照与 Google 概念字幕 [55] (CC3M) 类似的程序从网络上抓取的。我们注意到超过 10% 的 CC3M 图像实际上是来自视频的缩略图,这促使我们使用这些视频源来抓取总共 250 万对文本-视频。本研究收集的数据的使用已通过知识产权局的非商业研究和私人研究的版权例外授权。
我假设 Web-10M 是论文中描述的 WebVid-2M 数据集的更大版本。
最重要的是,该网站包含一个指向 2.7GB CSV 文件的链接 – results_10M_train.csv – 包含完整的results_10M_train.csv -10M 数据集。 CSV 文件如下所示:
videoid,contentUrl,duration,page_dir,name 21179416,https://ak.picdn.net/shutterstock/videos/21179416/preview/stock-footage-aerial-shot-winter-forest.mp4,PT00H00M11S,006001_006050,Aerial shot winter forest 5629184,https://ak.picdn.net/shutterstock/videos/5629184/preview/stock-footage-senior-couple-looking-through-binoculars-on-sailboat-together-shot-on-red-epic-for-high-quality-k.mp4,PT00H00M29S,071501_071550,"Senior couple looking through binoculars on sailboat together. shot on red epic for high quality 4k, uhd, ultra hd resolution."
我将它加载到 SQLite并开始挖掘。
全部来自Shutterstock!
当我开始探索数据时,让我大吃一惊的是:Datasette 中链接的 10,727,582 个视频中的每一个都以相同的 URL 前缀开头:
https://ak.picdn.net/shutterstock/videos/
他们都来自Shutterstock。该论文谈到了“抓取网络”,但事实证明只涉及一个被抓取的网站。
这是 Shutterstock 本身 CSV 文件的第一行:
https://www.shutterstock.com/video/clip-21179416-aerial-shot-winter-forest
据我所知,这里使用的训练集甚至不是完整的 Shutterstock 视频:它是 Shutterstock 提供的免费、带水印的预览剪辑。
我猜 Shutterstock 为他们的视频提供了非常高质量的字幕,非常适合训练模型。
实施说明
我的simonw/webvid-datasette存储库包含我用来构建 Datasette 实例的代码。
我使用sqlite-utils构建了一个启用全文搜索的 SQLite 数据库。我通过构建一个捆绑了 2.5G SQLite 数据库的 Docker 映像,利用Baked Data 架构模式将其直接部署到 Fly。
最有趣的自定义实现部分是我为每个结果添加视频播放器而编写的插件。这是该插件的实现:
从数据集导入hookimpl 从标记安全导入标记 模板= """ <video controls width="400" preload="none" poster="{poster}"> <source src="{url}" type="video/mp4"> </视频> <p>{filename}<br>在 <a href="https://www.shutterstock.com/video/clip-{id}">Shutterstock</a></p> """ .strip () VIDEO_URL = "https://ak.picdn.net/shutterstock/videos/{id}/preview/{filename}" POSTER_URL = "https://ak.picdn.net/shutterstock/videos/{id}/thumb/1.jpg?ip=x480" @hookimpl def render_cell (行,列,值): 如果列!= “文件名” : 返回 id =行[ “id” ] 网址=视频网址。格式( id = id ,文件名=值) 海报=海报网址。格式( id = id ) 返回标记(模板。格式( url = url ,海报=海报,文件名=值, id = id ))
我正在使用Datasette 0.62 中添加的新render_cell(row)参数。
该插件输出带有preload="none"的<video>元素,以避免浏览器在用户单击播放之前下载视频。我将poster属性设置为来自 Shutterstock 的缩略图。
原文: http://simonwillison.net/2022/Sep/29/webvid/#atom-everything