尽管人工智能让我分心,但我本周在一系列不同的项目上取得了进展,包括s3-credentials和shot-scraper的新版本、新的datasette-edit-templates插件以及对Datasette Lite的小而精巧的改进。
为 Datasette Lite 提供更好的 GitHub 支持
Datasette Lite是在 WebAssembly 中运行的 Datasette 。最初打算作为一个很酷的技术演示,它正在迅速成为更广泛的 Datasette 生态系统的关键组成部分——就在本周,我看到 mySociety 正在使用它来帮助人们探索他们的WhatDoTheyKnow Authorities 数据集。
Datasette Lite 的优点之一是您可以将 URL 提供给 CSV 文件、SQLite 数据库文件甚至 SQL 初始化脚本,它会将它们提取到您的浏览器中并在 Datasette 中提供它们。我在使用 Datasette Lite 在浏览器中加入 CSV 文件中详细介绍了此功能。
只有一个问题:因为这些 URL 是由在您的浏览器中运行的 JavaScript 获取的,所以它们需要从设置Access-Control-Allow-Origin: *标头的主机提供(请参阅 MDN )。这不是一件容易向人们解释的事情!
这里的好消息是 GitHub 使托管在 GitHub 上的每个公共文件(和每个 Gist)都可用作具有该魔术头的静态托管。
坏消息是您必须知道如何构建该 URL! GitHub 的“原始”链接重定向到该 URL,但如果 JavaScript fetch()调用没有该标头,则它们不能跟随重定向 – 而 GitHub 的重定向则没有。
所以你需要知道,如果你想从 GitHub 上的这个页面加载 SQLite 数据库文件:
您首先需要将该 URL 重写为以下内容,并使用正确的 CORS 标头提供:
要求人类手动执行此操作是不合理的。所以我添加了一些代码!
const githubUrl = / ^ https: \/ \/ github.com \/ ( . * ) \/ ( . * ) \/ blob \/ ( . * ) ( \? raw=true ) ? $ / ; 功能修复网址(网址) { 常量匹配= githubUrl 。执行(网址) ; 如果(匹配) { 返回`https://raw.githubusercontent.com/$ {匹配[ 1 ] } / ${匹配[ 2 ] } / ${匹配[ 3 ] } ` ; } 返回网址; }
有趣的是:GitHub Copilot 为我自动完成了return语句,根据我之前定义的几行正则表达式正确猜测了我需要的 URL 字符串。
现在,每当您向 Datasette Lite 提供 URL 时,如果它是 GitHub 页面,它会自动将其重写为raw.githubusercontent.com域上启用 CORS 的等效项。
一些例子:
- https://lite.datasette.io/?url=https://github.com/lerocha/chinook-database/blob/master/ChinookDatabase/DataSources/Chinook_Sqlite.sqlite – Chinook SQLite 数据库示例(来自这里)
- https://lite.datasette.io/?csv=https://github.com/simonw/covid-19-datasette/blob/6294ade30843bfd76f2d82641a8df76d8885effa/us_census_state_populations_2019.csv – 美国人口普查,来自我的simonw/covid-19 -数据集回购
数据集编辑模板
几年前我开始研究这个插件,但没有让它工作。本周我终于关闭了最初的问题并发布了第一个 alpha 版本。
这很有趣。首次启动时,它会在您的数据库中创建一个_templates_表。然后它允许root用户(运行datasette data.db --root并单击链接以以 root 身份登录)编辑 Datasette 的默认 Jinja 模板集,将他们的更改写入该新表。
Datasette 立即使用这些模板。它将整个 Datasette 变成一个用于编辑自身的界面。
这是一个动画演示,展示了该插件的运行情况:
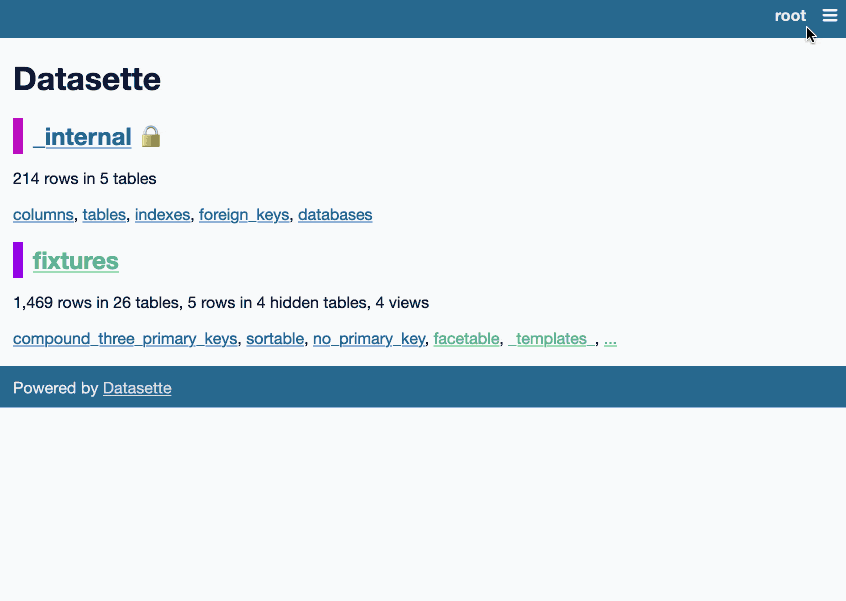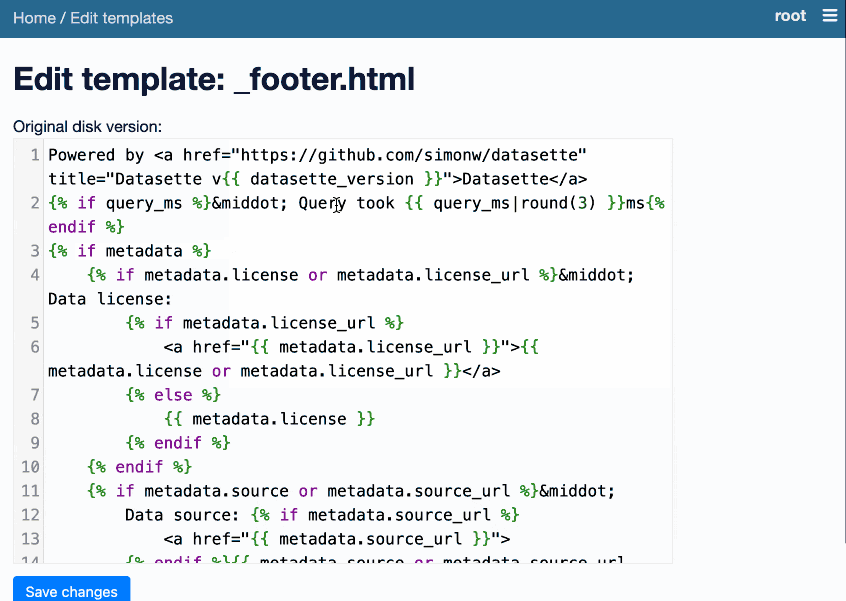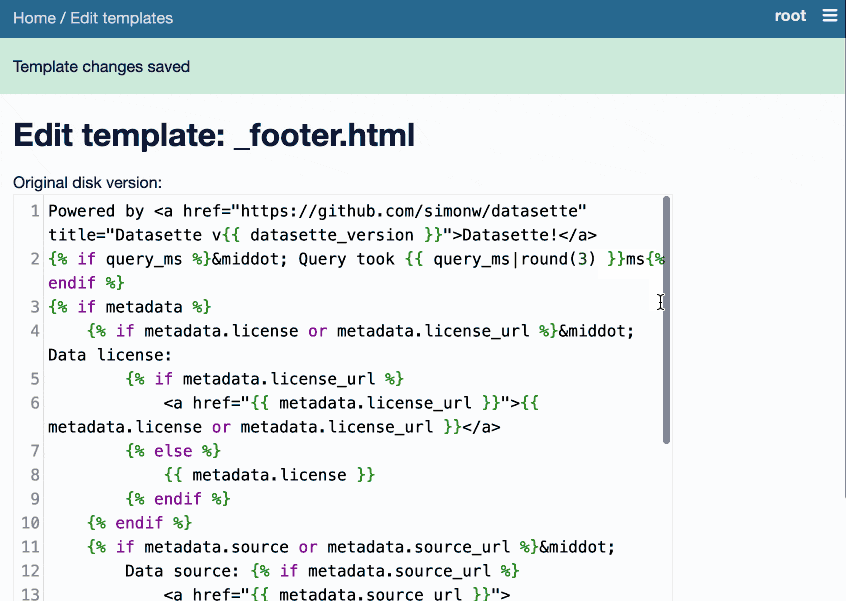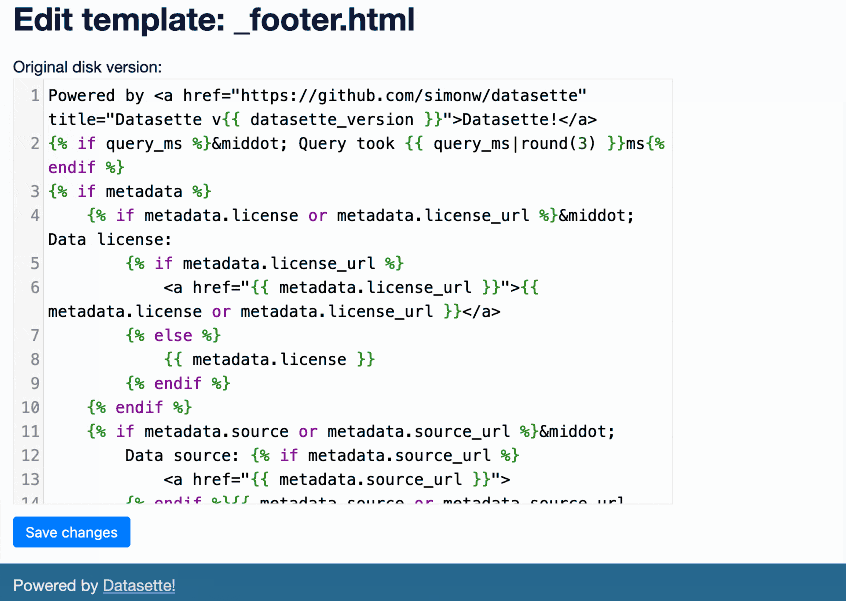
目前的实现有点粗糙,但我已经在 Datasette 核心中提出了一个问题,以帮助清除其中的一些问题。
s3-credentials 获取对象和放置对象
我构建了s3-credentials来解决我对 AWS S3 的第一个挫折:颁发只能访问特定 S3 存储桶的 IAM 凭证所涉及的令人惊讶的复杂程度。我在s3-credentials 中介绍了它:一个为 S3 存储桶创建凭证的工具。
创建凭据后,您需要能够使用它们进行操作。我发现默认的 AWS CLI 工具相对不直观,因此当我觉得需要时, s3-credentials会继续增加其他命令。
最新版本0.14增加了两个: get-objects和put-objects 。
这些使您可以执行以下操作:
s3-credentials get-objects my-bucket -p "*.txt" -p "static/*.css"
这将下载my-bucket中的每个键,其名称与这些模式中的任何一个匹配。
s3-credentials put-objects my-bucket one.txt ../other-directory
这将上传one.txt和整个other-directory文件夹及其所有内容。
与我的大多数项目一样,每个项目的 GitHub 问题线程都包括我如何完成他们的设计的详细说明 – #68用于put-objects和#78用于get-objects 。
shot-scraper –log-requests
shot-scraper是我的自动化截图工具,建立在 Playwright 之上。
其最新功能的灵感来自 Datasette Lite。
我一直有一个雄心壮志,让 Datasette Lite 使用 Service Worker完全离线工作。
第一步是让它在不加载外部资源的情况下工作——它当前每次加载应用程序时都会多次点击 PyPI 和一个单独的 CDN 来下载轮子。
为此,我需要一个可靠的列表,列出它正在获取的所有资产。
如果我可以运行命令并获取这些资源的列表,那不是很方便吗?
下面的命令现在正是这样做的:
shot-scraper https://lite.datasette.io/ \ --wait-for 'document.querySelector("h2")' \ --log-requests requests.log
这里需要--wait-for以确保在应用程序完全加载之前, shot-scraper不会终止 – 通过等待将<h2>元素添加到页面来检测。
--log-requests位是shot-scraper 0.15中的一个新功能:它会注销一个以换行符分隔的 JSON 文件,其中包含运行期间获取的所有资源的详细信息。该文件的开头是这样的:
{"method": "GET", "url": "https://lite.datasette.io/", "size": 10516, "timing": {...}} {"method": "GET", "url": "https://plausible.io/js/script.manual.js", "size": 1005, "timing": {...}} {"method": "GET", "url": "https://latest.datasette.io/-/static/app.css?cead5a", "size": 16230, "timing": {...}} {"method": "GET", "url": "https://lite.datasette.io/webworker.js", "size": 4875, "timing": {...}} {"method": "GET", "url": "https://cdn.jsdelivr.net/pyodide/v0.20.0/full/pyodide.js", "size": null, "timing": {...}}
这已经非常有用了……但如果我可以在 Datasette 中探索这些数据,它会不会更有用?
这就是这个食谱的作用:
shot-scraper https://lite.datasette.io/ \ --wait-for 'document.querySelector("h2")' \ --log-requests - | \ sqlite-utils insert /tmp/datasette-lite.db log - --flatten --nl
它将换行符分隔的 JSON 传送到sqlite-utils insert ,然后插入它,使用--flatten选项将该嵌套的timing对象转换为一组平面列。
我决定通过将其转换为 SQL 转储并将其发布到此 Gist来共享它。我使用sqlite-utils memory命令将其转换为 SQL 转储,如下所示:
shot-scraper https://lite.datasette.io/ \ --wait-for 'document.querySelector("h2")' \ --log-requests - | \ sqlite-utils memory stdin:nl --flatten --dump > dump.sql
stdin:nl表示“从标准输入读取并将其视为换行符分隔的 JSON”。然后我运行一个select *命令并使用--dump将其输出到dump.sql ,我将其粘贴到一个新的 Gist 中。
所以现在我可以在 Datasette Lite 中打开结果了!
沙尘暴数据集
Sandstorm是“一个用于自托管 Web 应用程序的开源平台”。您可以将其视为一个易于使用的 UI,在类似 Docker 的容器平台上 – 一旦您将其安装在服务器上,您就可以使用它来管理和安装为其捆绑的应用程序。
Jacob Weisz一直在为 Datasette 做这件事。结果是Sandstorm App Market 中的 Datasette 。
您可以在ocdtrekkie/datasette-sandstorm 存储库中查看它是如何工作的。我通过构建一个小的 datasette-sandstorm-support插件来帮助展示权限和身份验证如何针对 Sandstorm 的自定义 HTTP 标头工作。
本周发布
- s3-credentials : 0.14 – (总共 15 个版本) – 2022-09-15
用于创建用于访问 S3 存储桶的凭证的工具 - shot-scraper : 0.16 -(总共 21 个版本) – 2022-09-15
用于自动截取网站截图的命令行实用程序 - 数据集编辑模板: 0.1a0 – 2022-09-14
允许在 Datasette 中编辑 Datasette 模板的插件 - 数据集沙尘暴支持: 0.1 – 2022-09-14
Sandstorm 上 Datasette 的身份验证和权限 - datasette-upload-dbs : 0.1.2 -(总共 3 个版本)- 2022-09-09
将 SQLite 数据库文件上传到 Datasette - datasette-upload-csvs : 0.8.2 – (共 13 个版本) – 2022-09-08
用于上传 CSV 文件并将其转换为数据库表的 Datasette 插件
直到本周
- 使用 Docker 针对特定的 Python 版本运行 pytest
- 克隆、编辑和推送 Gist 中的文件
- 从 Mac 笔记本电脑驱动外接显示器
- 使用 ifuse 在 iPhone 上浏览文件(包括 SQLite 数据库)
- 使用 Homebrew 在 macOS 上运行 PyPy
原文: http://simonwillison.net/2022/Sep/16/weeknotes/#atom-everything