自上次以来加入的所有新读者您好!这是我不久前写的一篇文章的更新版本,它也与关于为什么 AI 还没有个性以及它本质上是一个白痴学者的帖子有关。享受!

一、隐性学习
考虑这些句子:
-
有快乐快乐的牧羊人,他是小天使角马
-
叮叮当,叮叮当,叮叮当所有的疣猪
-
1红色,2绿色,3黄色,4蓝色,5红色,7绿色,11绿色
-
翼龙和栉龙也与它们的翼龙有关系,但栉龙没有像其他两个一样的翅膀
-
爱尔兰麋鹿是一种美丽的动物,麋鹿是一种最美丽的动物。它类似于驼鹿,但头部更大,更强壮
-
一闪一闪的小星星看起来像个婴儿
你能说出我 3 岁的孩子说的哪些话和我一直在玩的源自 GPT-2 的文本生成 AI 1吗?
无论您是 Team AI 还是 Team Toddler,有两件事是肯定的。 1)它们听起来非常相似,并且 2)它们听起来都不像成年人会说的那样。
(当我通过让 GPT-3 和我现在 4 岁的孩子顺便回答相同的提示来更新测试时,他们以优异的成绩通过了。孩子在成长,人工智能也在成长! 2 )
从外部看,看输出,很难看出行为3的差异。他们似乎都在大致相同的发展里程碑,而且有趣的是,他们似乎也在大致进步。
它有什么作用?来自福布斯的一篇文章:
GPT-3 可以创建任何具有语言结构的东西——这意味着它可以回答问题、撰写论文、总结长文本、翻译语言、做备忘录,甚至可以创建计算机代码。
就它在 AI 应用程序的一般类别中的位置而言,GPT-3 是一种语言预测模型。这意味着它是一种算法结构,旨在获取一种语言(输入)并将其转换为它预测的对用户最有用的后续语言。
这就是为什么将它与我三岁的孩子相比是如此有趣。而且他们犯的错误也类似。当我们查看 Gary Marcus 所写的Alt Intelligence时,发现与实际现实有关的任何事情都会导致程序出错。
据我所知,我的儿子还没有阅读过像GPT-2这样从网络上抓取的 800 万份文档,或者像 GPT-3 这样的来自互联网的 45 TB 文本。 GPT 的惊人表现是因为它们拥有数 TB 的数据,而 SwiftKey 则有 100MB 的数据,这有助于预测在智能手机键盘上输入的下一个单词。
两者令人难以置信的是,它们以某种方式内化了英语语法结构的空洞。虽然我儿子仍然使用“drinked”或“catched”,面对不规则动词大笑,他的句子结构连贯而有说服力。
当他兴高采烈地忽略世界上的因果关系,并在物理学面前笑着创造自己设计的新世界时,他的句子在语法上仍然是正确的。与语言模型相同。
二、人工智能的认识论
所以。理所当然地, GPT-3受到了极大的追捧。我什至可以说它仍然被低估了!但也有一些关于它是如何受到限制的负面评论,这主要是模仿我们上面写的关于它迄今为止的纯粹默契学习的问题,与现实没有真正的联系。隐性知识本身不足以建立一个我们都可以签署的强大认识论。

那么我们怎么知道它知道它似乎知道什么?今天的人工智能已经构建了我们使用的语言语料库,使用我们听起来熟悉的概念,并创建熟悉的句子和段落。熟悉不是偶然的。这是一个相当明确的恐怖谷案例,当输出变得更长或更复杂时尤其明显。
虽然它可以写出关于栉龙的有趣句子,但它不知道为什么它头上的冠冕对我们来说很有趣,或者它曾经(可能)像一头大象一样吹号。或者说喇叭是一种声音,类似于喇叭,但不同于咆哮。
当一个段落被创建时,机器可能会发现其全局数据模型内部的内部连接意味着我上面所做的这些隐式关联也反映在内部。这是非常重要的。这就是它实际上似乎理解 parasauralophus 首先有一个冠,并且它发出声音作为我们人类的独特特征之一,并且这种声音类似于大象的声音(可能),并且该声音类似于维基百科的所有人类知识纲要中提到的其他声音。
然而,它所没有的,以及三岁孩子所拥有的,是多个系统,可以独立地给他这些事实和肯定。他认识他的 parasauralophus,因为它是一个有大冠的兽脚亚目恐龙,它是他的玩具之一,看起来是橙色的,像玩具一样有趣,虽然不在博物馆里,但他曾经看过一段视频,显示它在吹喇叭,它带有一个一大群其他恐龙,以及博物馆里的其他鸭嘴龙,我们就它的冠冕进行了几次深入而曲折的对话。
他知道这一点,因为他知道什么是大、什么是徽章、什么是玩具、什么是博物馆,等等!这些概念中的每一个也都被结构化为多个其他抽象层,因此他可以在我们的帮助下从不了解如何说话到层命名概念一路攀升,直到他到达吹号的顶峰。
正如人工智能研究员 Geoffrey Hinton 所说:
将 GPT3 的惊人表现推断到未来表明,生命、宇宙和一切的答案只是 4.398 万亿个参数。
最终输出可能与 GPT 中的神经网络非常相似,但到达那里的过程包括更多数量的子模型。一旦你知道什么是动物,那么你就可以更深入地了解哺乳动物是什么,然后是食肉动物、草食动物和杂食动物,然后是长相怪异的产卵哺乳动物,等等。它提供了一个复杂的模块化网络挂毯,其他更新的概念可以继续使用。
事实上,我们所有人都有相同的分类法,他与之互动的整个世界,这使我儿子能够更多地了解他的恐龙。他对什么是“恐龙”有清晰的概念云,与“灭绝的动物”、“蜥蜴”和“鸟类”相关联。
然后,他可以将“恐龙”中的概念子链接到不同类型的恐龙,如“兽脚亚目”和“鸭嘴龙”,以及“总是紧挨着恐龙但由于某种神秘原因不被称为恐龙的飞蜥,如羽蛇神和翼龙” .
这就是 Yann LeCun 所呼吁的,帮助机器通过观察来了解世界是如何运作的,并在抽象空间中创建分层表示。
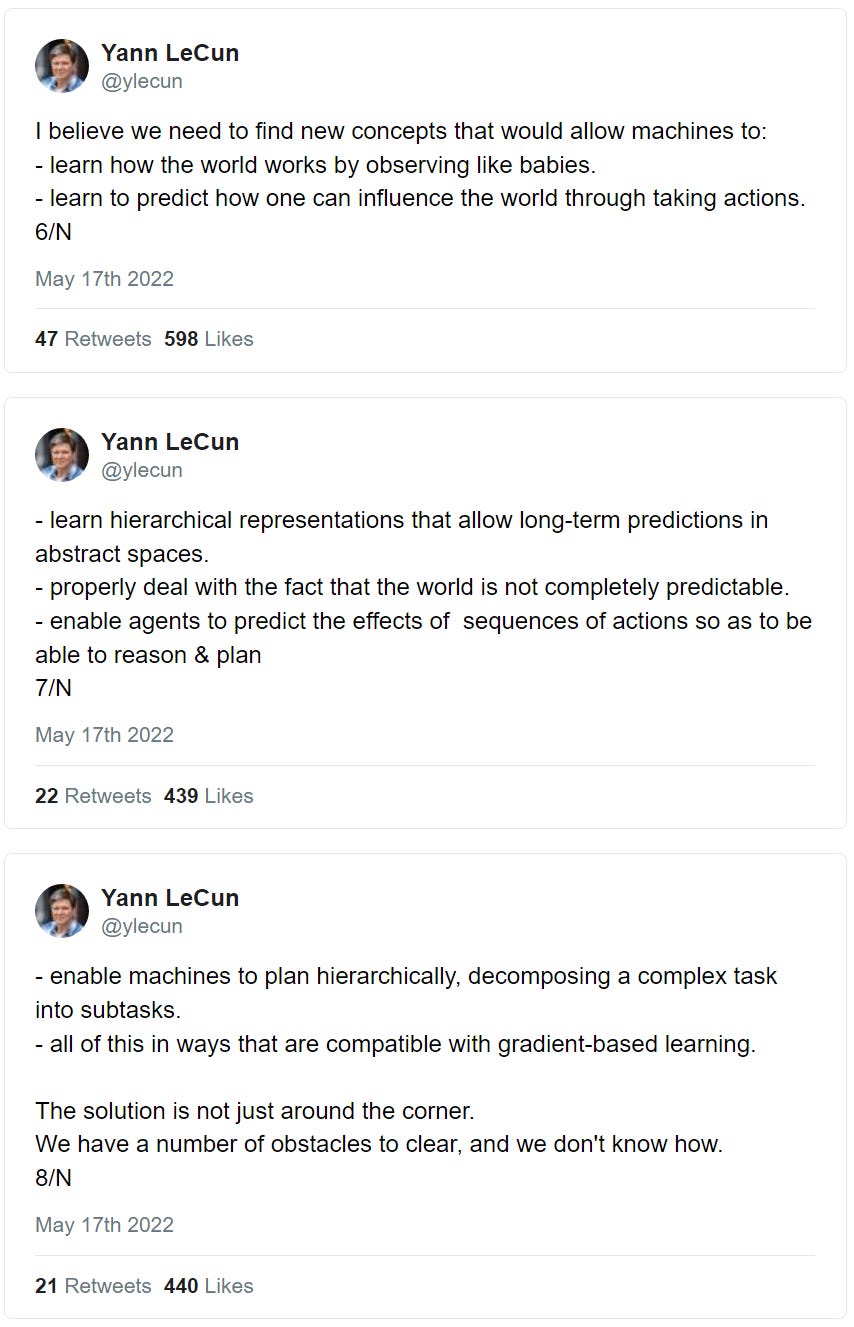
而且由于这些概念是相互联系的,因此进来的任何新信息都有一个可以对其进行分析的上下文。我们从一个预训练的网络开始,该网络一直能够使用以前训练的模块进行构建。这是允许小样本学习发生的原因,因为我们并没有立即尝试构建一个可以帮助在所有知识领域创建完整句子的工具。
随着我们的成长,我们从一些更一般的知识开始,然后是概念,然后再叠加与它相关的其他信息。一次一个概念地成长,虽然很痛苦(你三岁的孩子让你向你解释“头脑”这个词吗?),但最终仍然是一种更灵活的学习和成长方式。
虽然谷歌理解我的乱码英语并给我合理的结果似乎很神奇,但它仍然不是你真正所说的理解。这不是错误,它只是意味着必须构建下一个模块。这就像因为没有空调而对机箱感到恼火。
三、其意识的现象学
因此,询问 LaMDA 或 GPT 等是否有感知类似于询问“飞机能飞吗?”答案可能是肯定的(看着它飞),也可能不是(它不能飞,但你可以飞)。到今天为止,这个问题本身是不正确的。
Erik Hoel 认为我们将 AI 视为类似于 p-zombies的东西。在线上将他人非人化的类比对我们来说似乎很可怕,而忽略 LaMDA 对其自身感知的评论很容易,因为我们已经了解人类是什么样的,而这个问题的措辞在人工智能的案例。
当我们看着另一个人,并利用他们的行为来弄清楚他们未来可能会做什么时,我们隐含地假设我们了解导致该结果的内部过程。如果我们不这样做,那么我们必须知道的不仅仅是“他们做同样的事情”,才能得出关于他们的智力或意识的观点。
因此,感知的问题是一个转移注意力的问题,因为当我们说这个词时,我们的意思是陷入了它的进化背景。这是行不通的,因为两者的基本接线截然不同,即使中间输出相同。
人类大致以目前的形式进化了大约 200,000 年(或自人类前缀以来 200 万年),并且已经有超过 1000 亿人,这大约是 10,000 到 100,000 代的进化和选择。更不用说数十亿年的进化帮助创造了发生这种特殊进化的基础。
您大概可以将此进化时间尺度与大型语言模型中的参数数量进行比较,并尝试计算其有效时间尺度。就像计算神经元的数量和参数的数量一样,这也是一种愚蠢的做法,尽管我们几乎无法抗拒这种诱惑。
一个蹒跚学步的孩子所拥有的学习量不仅仅是他的心智能力或神经元的相对数量,还包括培养数十亿连接所花费的进化时间。这样看来,他们的学习能力比 GPT 可以想象的要高出许多倍。
四。逆向进化路径
这也意味着,就其进化对应物而言,人工智能的观点(它像大黄蜂一样聪明吗?像大猩猩一样聪明吗?像能人一样聪明?)是一个类别错误。它被比作沿着一条它没有经历过的进化路径前进。
相反,它几乎是在逆向追溯进化路径。首先它获得了语言能力,从较难的语法开始,然后是实际创建连贯句子的能力,然后是允许语言引用现实世界中真实事物的隐含逻辑,很快就可以理解什么该逻辑实际上是指。
这与我们所拥有的相反——从生活和繁殖的能力开始,然后是用基本方法进行交流的能力,最后是相互交谈的语言。
人工智能的隐性学习需要通过我们为孩子提供的显性学习来加强。如果现实以不同于语言模型中的内部矩阵的方式粗粒度化,那么可以假设,找到正确的抽象级别不仅仅是随机选择的问题。
如果我们看看两者之间的区别,蹒跚学步的孩子和人工智能,那就是当他们经历某些事情时,他们能够区分真相和谎言,因为他们暴露在他们周围的完整现实中,而且事实上只有一个他们能够创建明确的模型,然后用于相互讨论、辩论、学习、互动、探索。
这也是今天每个人都同时极度乐观和悲观的人工智能的复杂性。它可以愉快地画出“椅子坐在猫身上”,因为它不关心椅子是什么,猫是什么,坐着是什么,它可能看起来像什么,以及它的物理不合理性。有了足够大的数据集,它就会开始弄清楚它,只是在它蛮力迫使极端案例消失的意义上。添加一个未知的单词或概念,我们又回到了零,因为它与它所谈论的内容之间的关系缺失了。
隐含地,这种推理模式起作用的原因是因为我们对他人的内在品质有合理的直觉。无论您是否有意识依从者的问题。光看它的驾驶,我们不会想到“这辆自动驾驶汽车能不能开车”这个问题。我们还将研究其确定如何驾驶的实际方法,并且这些过程本身需要进行审查。
与人工智能类似,是的,它很快就会改进并拥有惊人的能力,比它已经拥有的更多,是的,它仍然会以不可预测的方式在极端情况下失败,因为我们无法理解它的内部世界。它的进化路径是颠倒的,它的知识都是默契的。在 AI 能够根据显性知识探索其内在性之前,我们只剩下它的直接输出。这还不足以让我们判断它的品质。
因此,我们的话语变成了循环的。对愚蠢的错误和算法天才的挫败感和对意识的讨论都是今天人工智能存在一个主要问题的症状——它今天只关注隐性学习,它没有提供真正的接口或暴露的内部分类法让自然世界与之交互允许双向学习。
在它出现之前,对我们来说,它仍将是一个难以理解的古玩,一个复杂的系统,我们无法预测其结果,也无法释放它。至于第一个,它的能力,它正在反向穿越进化路径,它只有我们整个进化时间尺度的一小部分来帮助它学习它可以做什么。
为了帮助它穿越这条道路,我们将不得不开发一种比纯粹的隐性知识更好的方法来教授它,至少帮助它纠正它。
这是我们要选择的道路吗?我和 GPT-3 一样再次问了我儿子,他们也不确定。
答案 – 1、4 和 6 是 AI。 2是幼儿。 3和5都是!
我尝试使用自己的数据源来看看会发生什么。我今天使用童谣和故事以及关于史前动物、恐龙和野生动物的维基百科文章,因为这些都是我儿子痴迷的东西——让比较更公平。结果符合预期。
尽管应该说它们是相同的,因为我们施加了使它们相同的压力。
原文: https://www.strangeloopcanon.com/p/all-ai-learning-is-tacit-learning