\ 本文介绍Alluxio Master中元数据存储的设计和实现,无论是堆上还是堆外(基于RocksDB)。
背景
Alluxio 是世界上第一个用于云分析和人工智能的开源数据编排平台。 Alluxio 弥合了数据驱动应用程序和存储系统之间的差距。它使存储层中的数据更接近数据驱动的应用程序,并使其易于访问,使应用程序能够通过通用接口连接到众多存储系统。 Alluxio 的架构能够以比现有解决方案快几个数量级的速度访问数据。
\ 作为分布式系统,Alluxio 采用 Master-Worker 架构。一个 Alluxio 集群由一个或多个 Master 节点和多个 Worker 节点组成。 Alluxio Master 服务于所有用户请求和日志文件系统元数据更改。 Alluxio worker 负责管理分配给 Alluxio 的用户可配置的本地资源(例如内存、SSD、HDD)。 Alluxio 工作人员将数据存储为块,并通过在其本地资源中读取或创建新块来服务读取或写入数据的客户端请求。
\
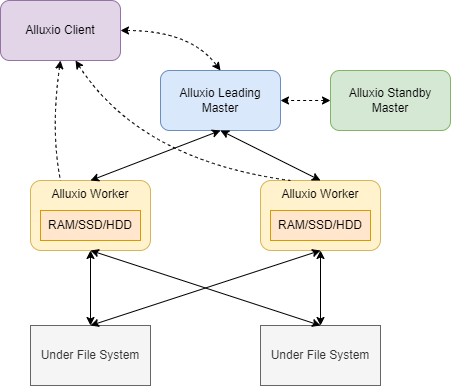
本文介绍Alluxio如何在Alluxio Master中实现元数据存储。
Alluxio中存储元数据的两种方式
在 Alluxio master 内部,每个文件或目录都由一个称为 inode 的数据结构表示,该结构包含文件权限等属性,以及块位置等其他元数据。 Alluxio master 将整个文件系统的元数据存储为一个 inode 树,类似于 HDFS 和其他基于 UNIX 的文件系统。
\ Alluxio 提供了两种存储元数据的方式:
\
- ROCKS:基于 RocksDB 的磁盘元存储
- HEAP:堆上元存储
\ 默认为 ROCKS。
\ Alluxio源码在/core/server/master/src/main/java/alluxio/master/metastore目录下提供了两个接口,InodeStore和BlockStore。 InodeStore 管理的元数据包括各个inode 和不同inode 之间的父子关系。 BlockStore 负责管理文件数据块的块大小和块位置。 cacheInodeStore 在 RocksDB 前面实现了一个 on java heap 可配置缓存以提高性能。在 HEAP 中,这些接口是通过 HeapInodeStore 和 HeapBlockStore 实现的。整体依赖关系如下。
\
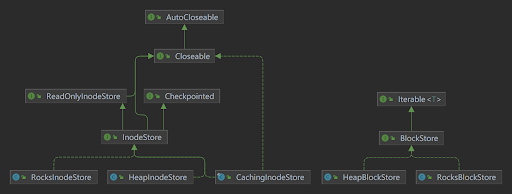
在AlluxioMasterProcess过程中,会生成两个Factor到对应的store,根据配置在Factor中生成不同的InodeStore和BlockStore。
ROCKS 元存储
RocksDB 是一个嵌入式 Key-Value 数据库。用户可以通过调用API接口实现高效的KV数据存储和访问。
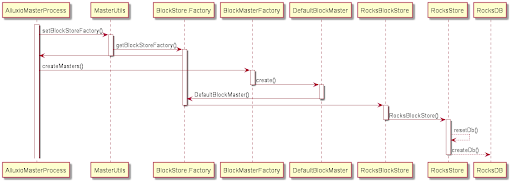
\ BlockStore接口由RocksBlockStore实现,流程如下。
\
- Factory 被添加到 AlluxioMasterProcess 中的 mContext 中。
- MasterUtils.createMasters() 将按顺序创建所有主线程。在创建 DefaultBlockMaster 时,会调用 BlockStore.Factory 创建一个 RocksBlockStore 实例。
- RocksDB.loadLibrary() 会在启动 RocksBlockStore 时调用,加载依赖库,然后根据配置文件创建 RocksStore 类的实例。 RocksStore 用于操作 RocksDB 数据库,包括初始化数据库、备份和恢复数据库等。
- 在创建 RocksStore 时,通过在 create() 方法中调用 RocksDB.open() 方法来创建 RocksDB 类的实例。
- DefaultBlockMaster 使用此 RocksDB 类读取和写入 RocksDB 数据库。
\ RocksBlockStore 主要使用以下方法:
\
- getBlock(长ID)
- putBlock(long id, BlockMeta 元)
- removeBlock(长 id)
- 获取位置(长 ID)
- addLocation(long id, BlockLocation 位置)
- removeLocation(long blockId, long workerId)
\ 我们以 getBlock() 为例。 getBlock() 用于通过blockId获取对应块的元数据,如下所示。
\
@Override public Optional<BlockMeta> getBlock(long id) { byte[] meta; try { meta = db().get(mBlockMetaColumn.get(), Longs.toByteArray(id)); } catch (RocksDBException e) { throw new RuntimeException(e); } if (meta == null) { return Optional.empty(); } try { return Optional.of(BlockMeta.parseFrom(meta)); } catch (Exception e) { throw new RuntimeException(e); } }\ 下面是与 RocksDB 交互:
\
meta = db().get(mBlockMetaColumn.get(), Longs.toByteArray(id));
\ 上面代码中的db()方法会返回之前创建的RocksDB类,然后调用RocksDB.get()方法。 get() 方法需要两个参数,第一个是 ColumnFamilyHandle,第二个是 blockId。
\ RocksDB中的每一个KV对对应一个ColumnFamily,ColumnFamily相当于RocksDB中的逻辑分区。当我们需要查询一个ColumnFamily中的数据时,我们需要通过ColumnFamilyHandle来操作底层数据库,ColumnFamilyHandle是在创建RocksDB实例时创建的。
\ RocksDB 中存储的 KV 数据是以字节串的形式存储的,因此我们需要将 blockId 转换为 byte[],并使用 Google Protocol 缓冲区将 RocksDB 返回的值转换回 BlockMeta Java 对象。
\ ROCKS方法中的InodeStore接口由CachingInodeStore和RocksInodeStore实现。 CachingInodeStore 使用内存来存储元数据缓存,而 RocksInodeStore 是 RocksDB 实现的元存储,作为 CachingInodeStore 的后备存储。
\ 当Alluxio集群的元数据可以完全存储在CachingInodeStore中时,Alluxio不与RocksInodeStore交互,而是使用CachingInodeStore来获得更好的性能。当 CachingInodeStore 的存储容量达到阈值时,Alluxio 会自动将元数据从 CachingInodeStore 迁移到 RocksInodeStore。此时元数据访问的性能取决于CachingInodeStore的缓存命中率和RocksDB的性能。
\ RocksInodeStore的创建和使用过程与RocksBlockStore类似。如果 MASTER METASTORE INODE CACHE MAX_SIZE 设置为 0,则它使用 RocksInodeStore。如果不为 0,则需要同时创建 CachingInodeStore 和 RocksInodeStore。
\
case ROCKS: InstancedConfiguration conf = ServerConfiguration.global(); if (conf.getInt(PropertyKey.MASTER_METASTORE_INODE_CACHE_MAX_SIZE) == 0) { return lockManager -> new RocksInodeStore(baseDir); } else { return lockManager -> new CachingInodeStore(new RocksInodeStore(baseDir), lockManager); }
堆元存储
Alluxio 在 Heap 方法中使用堆内存作为存储。在创建 AlluxioMasterProcess 时,会构建 HeapInodeStore 和 HeapBlockStore 来实现 InodeStore 和 BlockStore 接口。
\ 在创建 HeapInodeStore 时,会创建一个名为 mInodes 的 ConcurrentHashMap 来存储文件和文件夹的 Inode 信息。同时会创建一个名为 mEdges 的 TwoKeyConcurrentMap 来存储不同节点的父子关系。
\
private final Map<Long, MutableInode<?>> mInodes = new ConcurrentHashMap<>(); // Map from inode id to ids of children of that inode. The inner maps are ordered by child name. private final TwoKeyConcurrentMap<Long, String, Long, Map<String, Long>> mEdges = new TwoKeyConcurrentMap<>(() -> new ConcurrentHashMap<>(4));
\ TwoKeyConcurrentMap是Alluxio中定义的一个类,它实现了一个支持两个key的ConcurrentMap,逻辑结构如下:>.
\ mEdges 数据结构中的每个键都将一个 Inode ID 映射到其子节点的映射,然后将每个子节点的名称映射到其 Inode ID。
\ 在 HeapBlockStore 中,创建了一个名为 mBlocks 的 ConcurrentHashMap 来存储每个块的元数据,并创建一个名为 mBlockLocations 的 TwoKeyConcurrentMap 来存储该块在 worker 中的位置。
\
// Map from block id to block metadata. public final Map<Long, BlockMeta> mBlocks = new ConcurrentHashMap<>(); // Map from block id to block locations. public final TwoKeyConcurrentMap<Long, Long, BlockLocation, Map<Long, BlockLocation>> mBlockLocations = new TwoKeyConcurrentMap<>(() -> new HashMap<>(4));\ mBlockLocations中的两个key分别是blockId和workerId,value是worker上存储区块的具体位置。 blockId 可用于获取存储在 worker 中的块的位置。
概括
Alluxio 提供了两种存储元数据的方式,ROCKS 和 HEAP,默认存储是 ROCKS。对于 ROCKS,除了使用 RocksDB 之外,Alluxio 还提供了基于内存的缓存来提高元数据的读写性能。因此,当 Metastore 的大小有限时,我们可以获得高性能。使用 RocksDB,我们可以将元数据存储到硬盘以获得更多存储空间。
\ 一般来说,我们应该使用 RocksDB 来存储 Alluxio Master 中的元数据。如果只需要存储少量的元数据,对元数据读写性能要求很高,也可以考虑使用HEAP方式。
关于作者
中国移动大数据工程师顾长生。
\ 顾先生就职于中国移动云中心,专注于HDFS和Alluxio的云原生数据湖开发。
原文: https://hackernoon.com/deep-dive-into-the-implementation-of-metadata-storage?source=rss