就在圣诞节前夕, 推出完全开源的 Pwned Passwords 的承诺终于实现了。我们推出代码,发布博客文章,掸掉自己的灰尘,仅此而已。有点——只剩下一件事了……
k-anonymity API 很可爱,这不仅仅是我说的,而是人们用脚投票:
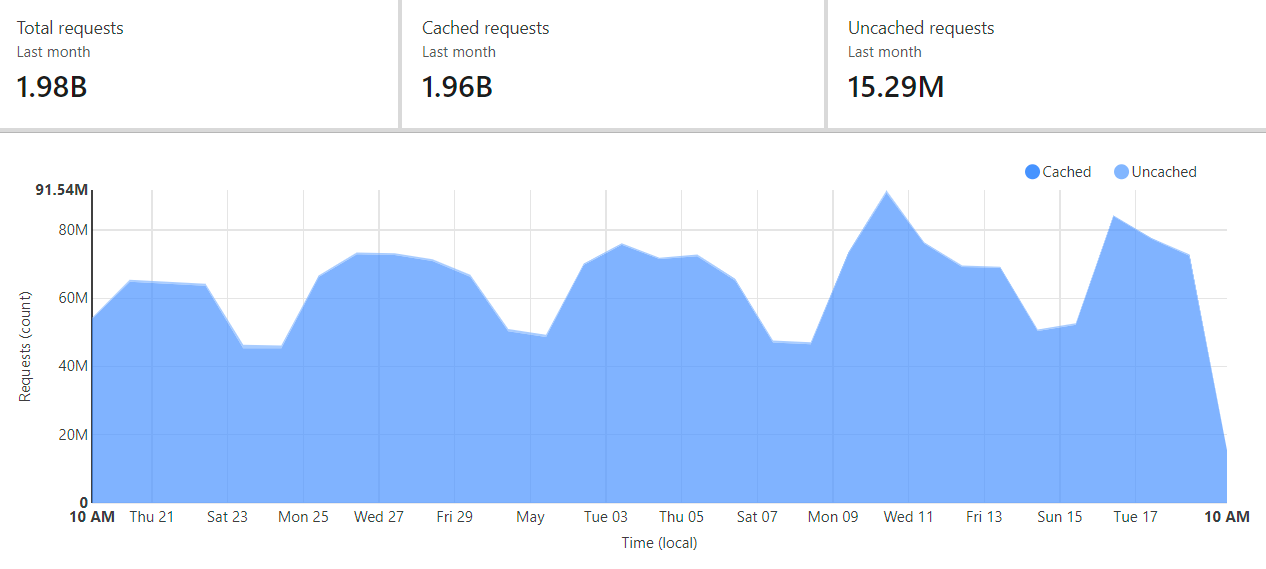
这已经是我 12 月博客文章的 58%,仅 5 个月前到今天。这也只是 100% 缓存命中率的舍入误差? 但剩下的一点是我在上一篇博文中做出的承诺:
最后,截至目前,用于提取管道并将所有密码转储到可下载语料库的代码尚未编写。我们想这样做——我们完全有这样做的意图——但考虑到发布之间的频繁时间,我们觉得没有必要急于求成。
采用 16^5 个哈希范围,将它们全部捆绑到一个单一的整体存档然后使其全部可下载的想法似乎是一项不平凡的任务。另外,在发布最后一个档案后,我仍在为我所遭受的巨额成本舔舐伤口,并且它们在 Cloudflare 的边缘超过了当时的可缓存限制。就在那时它击中了我——为什么我们不写一个脚本来从许多组织已经在使用的同一个 k-anonymity API 下载所有哈希值?这只是 16^5 个单独的请求,并且响应可以转储到一个大文本文件中,这有多难?它几乎都被缓存了,并且在客户端和 Cloudflare 边缘之间有超高效的 brotli 压缩,所以它也应该很快,所以……为什么不呢?
我把这个想法交给了Stefán ,他以他典型的酷酷的冰岛方式不仅构建了这个功能,而且做得比我一开始想的要好得多。因此,这是它以点形式工作的方式:
- Github 上有一个Pwned Passwords Downloader的公共存储库,欢迎您在其中获取代码、提交 PR 或提出问题
- 还有一个NuGet 包,所以如果您不想自己下载和编译代码,可以直接通过命令行拉取可执行文件
就是这样。运行它,它看起来像这样:

-p 开关定义了要应用的并行度级别,当在我测试过的 Azure VM 中运行时,需要 26 分钟才能将所有内容拉下来。显然,YMMV 基于连接速度,但由于缓存命中率如此之高(也反映在上面的输出中),至少您将从非常接近您的位置检索几乎所有单个哈希范围。
我意识到我们剩下的一个差距是这不会使 NTLM 版本可下载,并且那里的人们急切地等待着。我怀疑我们会在那里采取类似的方法,所以请继续关注,现在我们已经建立了一个模式,这应该不是什么大问题。我还意识到,为了使这个工具更有用,通过查看自给定日期以来添加了多少新密码哈希来了解何时实际运行它会很方便。这在清单上——我们知道它是需要的——尤其是随着入站密码数量的增加,我知道它对人们来说非常有用。
所以,拿起工具,在你喜欢的时候拉下散列,用它们做些好事。现在我有点好奇,一旦大众使用这个工具并每个请求超过 100 万次,这些 API 命中数字会是什么样子?
原文: https://www.troyhunt.com/downloading-pwned-passwords-hashes-with-the-hibp-downloader/