\ 很久以前,我尝试将我的两个兴趣结合起来:数据科学和视频游戏。对于一个小型个人项目,我从我最喜欢的两个 GameBoy 游戏( Super Mario Land 2: 6 Golden Coins和Wario Land: Super Mario Land 3 )中抓取图像,并构建了一个图像分类器来检测图像来自哪个游戏。这很有趣!
\ 但是这个项目几乎没有留下 Jupyter Notebook ? 虽然我个人喜欢 Notebooks 作为结构化叙事(和一些临时实验)的讲故事工具,但这样的设置有很多限制。对于初学者来说,构建任何 ML/DL 项目都是一个迭代过程,通常需要数十或数百个实验。它们中的每一个对数据的预处理都略有不同,添加了一些新功能,使用不同的模型及其超参数等。
\ 如何跟踪所有这些?我们可以创建一个电子表格并手动记下所有细节。但我敢肯定,经过几次迭代后,它会变得非常烦人和麻烦。虽然这可能适用于我提到的一些观点,但它不能解决数据问题。我们根本无法在电子表格中轻松跟踪数据及其转换。
\ 这就是为什么这次我想以不同的方式处理这个项目,也就是说,使用可用的工具来创建一个带有实验跟踪和一些数据完整性检查的正确版本(包括数据)项目。听起来比电子表格中的实验跟踪要好得多,对吧?
\ 在本文中,我将向您展示如何使用 DagsHub、DVC、MLFlow 和 GitHub Actions 等工具来创建一个成熟的 ML/DL 项目。我们将涵盖以下主题:
- 项目介绍,
- 使用 DagsHub 设置存储库,
- 使用 DVC 对数据进行版本控制,
- 使用 MLFlow 跟踪实验,
- 使用 GitHub Actions 和 Deepchecks 设置自动数据完整性检查。
\ 让我们直接进入吧!
项目介绍
正如我在介绍中已经提到的,我们将尝试解决二值图像分类问题。当我之前从事这个项目时,我将逻辑回归模型的性能与卷积神经网络的性能进行了比较。在这个项目中,我们将使用keras实现后者。
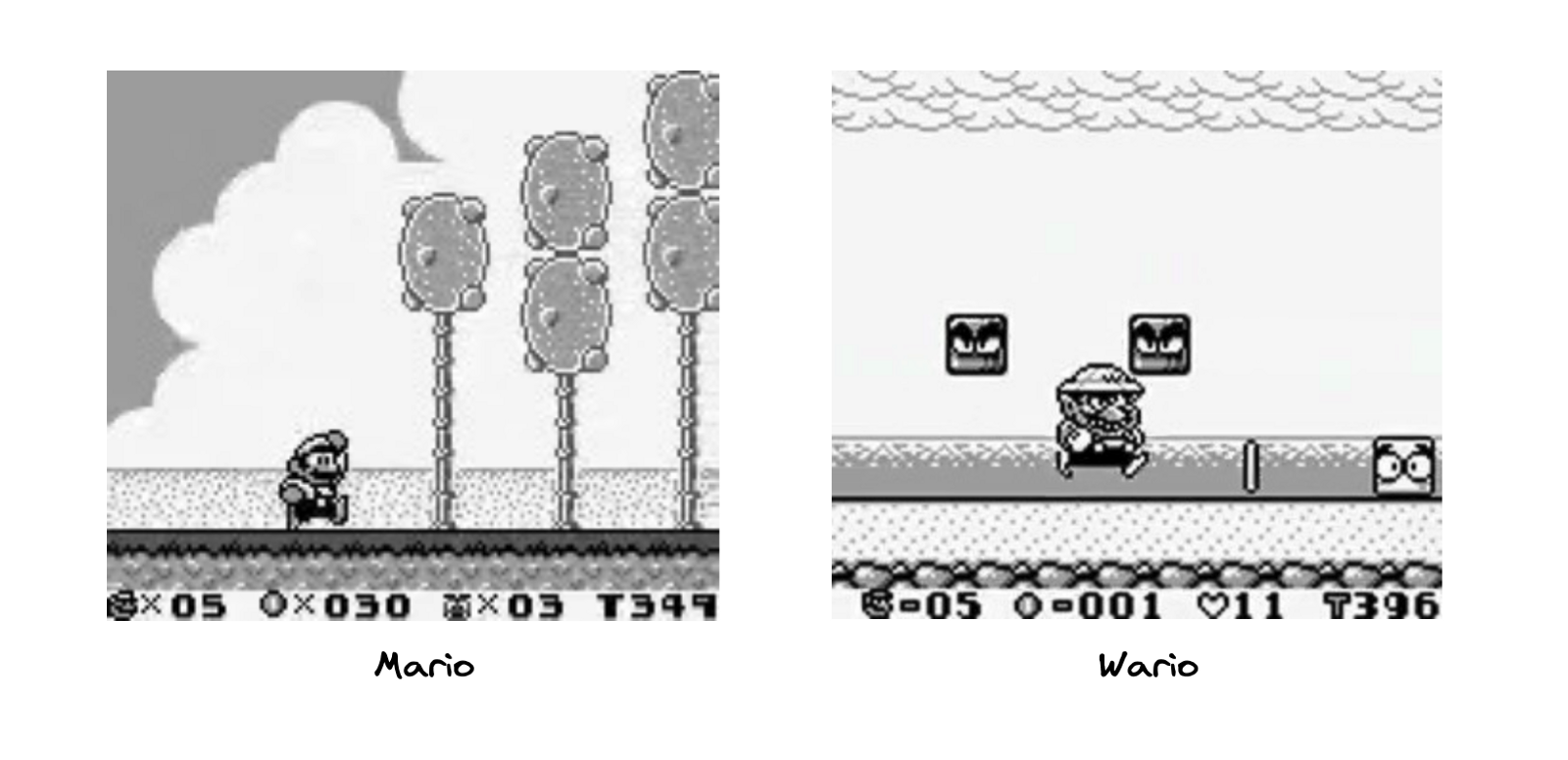
\ 您可以在下面找到我们将使用的图像示例。
\
\ 在获取数据、处理数据、构建 CNN 甚至评估模型方面,我不会详细介绍,因为我过去已经非常广泛地介绍了这些内容。如果您对这些部分感兴趣,请参考我之前的文章:
\ 对于此图像分类任务的 v2 方法,我们使用以下项目结构:
\ https://gist.github.com/erykml/fb7580867c9e859120c36c5508e0239f
\ 我们将涵盖整篇文章的所有元素,但现在我们可以简要提及以下内容:
- 所有数据都存储在
data目录中,每个子目录存储来自不同阶段的数据。 -
.github隐藏目录负责 GitHub Actions 工作流程。 -
notebooks目录包含用于探索的笔记本,这些与项目的功能无关。 -
src目录包含项目的整个代码库。每个脚本涵盖管道的不同部分。 -
requiremets.txt包含运行项目所需的库列表。poetry也可以。
\ 设置清晰的项目结构绝对有助于保持一切井井有条,并有助于运行仅修改整个管道部分的实验。我们仍然可以在结构中添加很多东西,但让我们保持简单,关注项目设置的其他元素。我们将在文章末尾提到一些潜在的扩展。
使用 DagsHub 设置存储库
作为我们项目的第一个构建块,我们将使用DagsHub 。简而言之,它类似于 GitHub,但它是为数据科学家和 ML 工程师(而不是软件工程师)量身定制的。在 DagsHub 上,我们不仅可以轻松地托管和版本化我们的代码,还可以托管我们的数据、模型、实验等。
\ 您现在可能会想“听起来不错,但我们需要再注册一项服务,最重要的是,我们的整个代码库已经在 GitHub 上”。幸运的是,这不是问题。我们可以完全迁移存储库,或者——更方便——镜像现有的存储库。这样,我们可以继续使用现有的 GitHub 存储库,并将其实时镜像到 DagsHub。对于这个项目,我们将使用 repo 镜像选项——主 GitHub 存储库将镜像到DagsHub 上的这个。
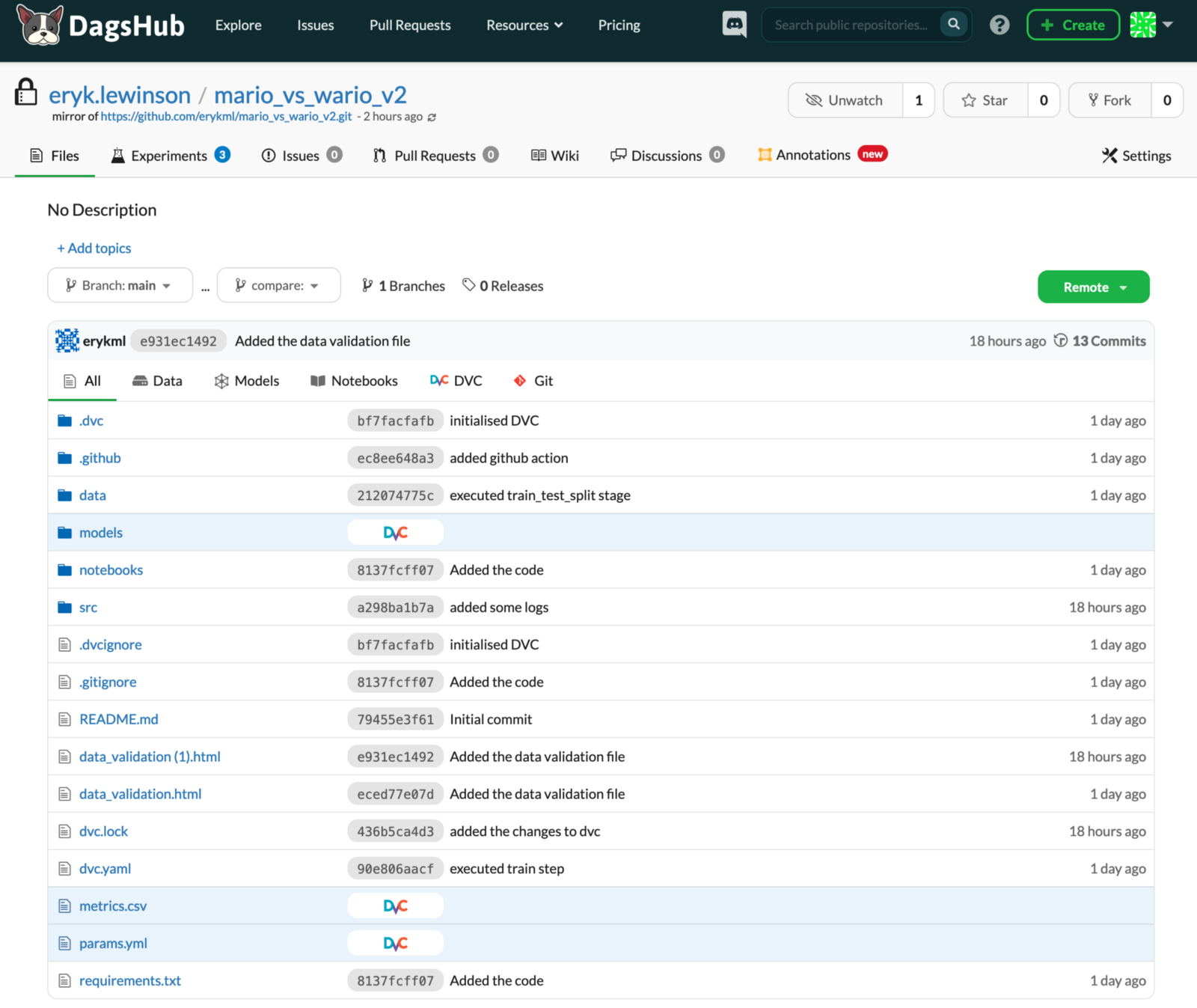
\ 如下图所示,DagsHub 的 UI 与 GitHub 的 UI 非常相似。这样,我们就不必从头开始学习另一种工具,因为一切从一开始就非常熟悉。在下图中,您已经可以看到有一些可用的新选项卡(实验、注释),我们稍后会介绍它们。在图像中,我们显示了存储库中的所有文件,但我们可以轻松过滤它们,例如,仅显示笔记本或使用 DVC 跟踪的文件。
\
\ 我们不会涵盖 DagsHub 的所有功能,但值得一提的是,它提供了以下功能:
- 使用完全集成的Label Studio注释数据,这是一种用于标记结构化和非结构化数据的开源工具。
- 在所有类型的文件下评论和开始讨论。
- 数据科学家可能想要使用的任何文件的全面比较(包括差异)。只要将数据存储在 DagsHub 上,我们就可以轻松比较 Notebook、表格、CSV 文件、注释、各种元数据,甚至图像。
使用 DVC 对数据进行版本控制
您肯定已经熟悉使用 Git 对代码进行版本控制的概念。不幸的是,GitHub 不能很好地处理数据,因为它的文件限制为 100MB。这意味着上传二进制文件(或者在我们的例子中是视频文件)已经可以超过这个限制。最重要的是,比较任何类型的不同版本的数据集也不是最愉快的体验。这就是为什么我们需要另一个工具来完成这项工作。
\ DVC(数据版本控制)是一个开源 Python 库,本质上与 Git 的用途相同(即使使用相同的语法),但用于数据而不是代码。 DVC 的想法是,我们将关于不同版本数据的信息保存在 Git 中,而原始数据存储在其他地方(云存储,如 AWS、GCS、Google Drive 等)。
\ 这样的设置需要一些 DevOps 专业知识。值得庆幸的是,DagsHub 可以为我们省去很多麻烦,因为每个 DagsHub 帐户都附带 10GB 的 DVC 免费存储空间。
\ 首先,我们需要安装库:
pip install dvc
\ 然后,我们需要实例化一个 DVC repo:
dvc init
\ 运行此命令会创建 3 个文件: .dvc/.gitignore 、 .dvc/config和.dvcignore 。您可以在此处找到有关它们包含的内容的更多信息。然后,我们需要将新创建的 DVC 存储库连接到 DagsHub。正如我们之前提到的,通过使用 DagsHub,我们不必手动设置与云存储的连接。我们唯一需要做的就是在终端中运行以下命令:
\ https://gist.github.com/erykml/b879e7f34f0c053b0be5c161240cad39
\ 为了更容易,DagsHub 为我们提供了远程选项卡下的所有内容。我们只需要将它们复制粘贴到终端中。
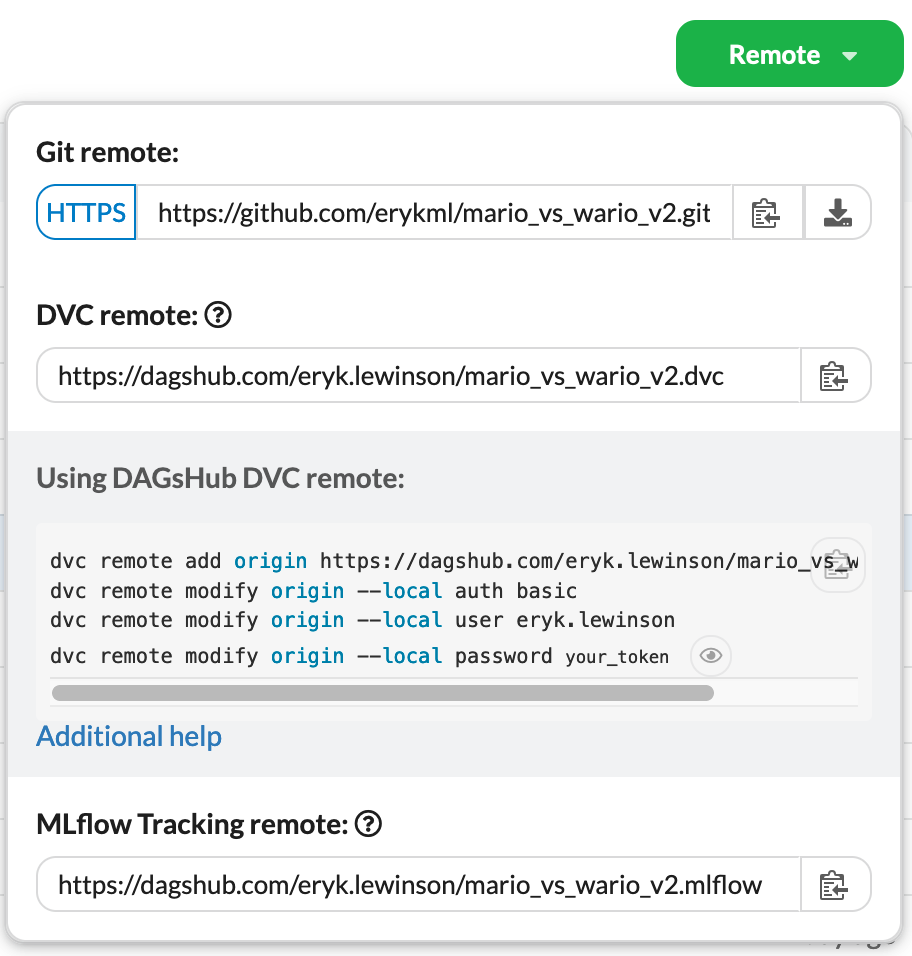
\ 连接到 DVC 远程后,我们将前面提到的文件提交到 Git:
git add. git commit -m "Initialized DVC" git push
\ 由于镜像功能,我们只需要将文件推送到 GitHub,因为 DagsHub 会自动从那里同步所有更改。
\ 现在是时候构建一个完整的管道,其中中间数据输出由 DVC 跟踪。为了简化流程,我们为管道的每个步骤创建了一个单独的.py文件。在我们的例子中,步骤如下:
-
get_videos.py— 从 YouTube 下载两个游戏的视频(完整的游戏玩法,从头到尾)。下载的视频存储在data/videos目录中。 -
extract_frames.py— 从 mp4 视频文件中提取图像。输出存储在data/raw目录中。 -
create_train_test_split.py— 将提取的图像拆分为训练集和测试集。此阶段的输出存储在data/processed目录中。 -
train.py— 训练 CNN 对图像进行分类。将训练好的模型输出到models目录,并将一些其他文件(metrics.csv和params.yml)输出到根目录。
\ 基于这些步骤,我们可以使用dvc run命令创建管道。为了便于阅读,这些步骤分为 4 个块,每个块对应于管道的一个单独阶段。在实践中,您不必在每一步之后都提交和推送。我们这样做是为了完全透明和易于处理。
\ https://gist.github.com/erykml/22603287af4c546705c9b4afdc6b8918
\ 正如您在提交的文件中看到的,DVC 将管道阶段保存到两个文件中: dvc.yaml (以人类可读的格式存储)和dvc.lock (几乎不可读)。在创建管道时,我们使用了以下 DVC 命令:
-
-n– 阶段的名称, -
-d– 阶段的依赖, -
-o– 阶段的输出。
下面,您可以看到管道在 YAML 文件中的样子。
\ https://gist.github.com/erykml/1dee99105604343dad4d1b9801f1a874
\DVC 会自动跟踪outs下的所有目录和文件。
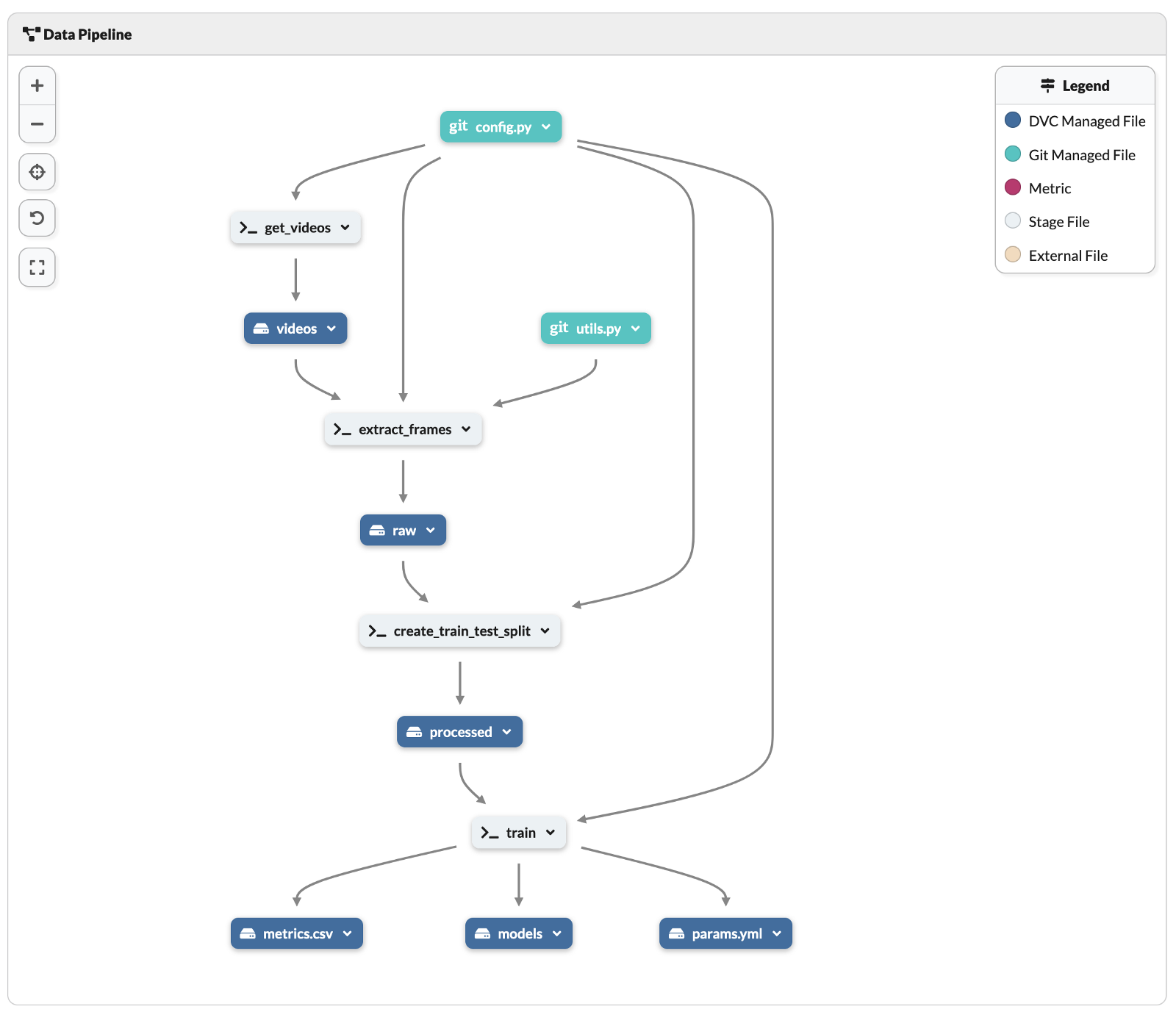
\ 最重要的是,DagsHub 提供了 DVC 管道的可视化预览。您可以在存储库中的文件列表下找到它。正如您在下面看到的,它比阅读dvc.yml文件更容易理解整个管道。
\
定义了整个 DVC 管道后,我们可以使用 dvc dvc repro命令通过执行dvc.yml中定义的阶段来重现完整或部分管道。
\ 最后,值得一提的是,我们可以访问和检查在 DagsHub 上使用 DVC 存储的所有数据,包括相当多的元数据。您可以在下面看到一个示例。
\
\
使用 MLFlow 进行实验跟踪
我们对这个项目的愿望清单上的下一点是实验跟踪。为此,我们将使用另一个开源库——MLFlow (准确地说是 MLFlow Tracking)。借助 MLFlow 的功能,我们将记录有关我们实验的大量细节,从名称开始到模型的超参数,并以相应的分数结束。
\ 与 DVC 类似,我们也需要一个服务器来托管 MFLow。和以前一样,DagsHub 也促进了这一点。我们可以在 DagsHub 存储库的Remote选项卡下找到身份验证所需的详细信息。在我们设置 MLFlow 远程之后,我们所有的实验都将记录在 DagsHub 存储库的Experiments选项卡下。
\ 在下面的脚本中,您可以看到如何使用 MLFlow 实现跟踪。它是完整训练脚本的缩写版本,它排除了一些不严格相关的元素(创建数据生成器、定义 NN 的架构等)。但是,我们将提到一些关于 MLFlow 实现的事情:
- 在第 7-9 行中,我们连接到 DagsHub 提供的 MLFlow 遥控器,
- 在第 13 行中,我们使用了 MLFlow 的 TensorFlow 自动记录器。这是一种方便的方法,可以节省我们手动指定模型的所有潜在超参数和其他规格的工作。几乎所有相关的 ML/DL 库都有这样的自动记录器。请在此处查看列表。
- 在第 19 行中,我们指出我们正在开始运行 MLFlow——该库将在运行的上下文中跟踪事物(手动指定或由自动记录器拾取)(使用
with语句指示)。 - 在第 45-54 行中,我们手动记录了一些参数(图像大小、学习率和 epoch 数)和指标(测试集的损失和准确性)。虽然这不是明确需要的(因为我们正在使用自动记录器),但我们想展示这两种方法。
\ https://gist.github.com/erykml/079b43c68ae3b1fb25fc3fe3fc5efc18
\ 作为一个小小的好处,值得一提的是,还有一种替代的、更轻量级的跟踪实验的方法——使用 Git 和 DagsHub。为此,我们必须使用dagshub库。在第 36-43 行中,我们展示了如何使用dagshub库记录一些指标和超参数。
\ dagshub记录器在项目的根目录中创建两个文件(除非另有说明): metrics.csv和params.yml 。这是我们在 DVC 管道的最后一步中指定的两个文件作为train.py脚本的输出。当我们将这两个文件提交到 git 时,DagsHub 会自动识别它们并将它们的值放在Experiments选项卡下。在查看源栏中标有 Git 标签的实验时,我们可以清楚地找到它们。
\ 使用dagshub客户端的最大优势是那些实验是完全可重现的——只要我们使用 DVC 来跟踪数据,我们就可以通过单个git checkout切换到完成实验时的项目状态。 MLFlow 也可以实现这样的事情,但没有那么简单。
\ 您还可以编写自己的自定义记录器,它结合了两种跟踪实验的最佳方法。你可以在这里找到一个例子。
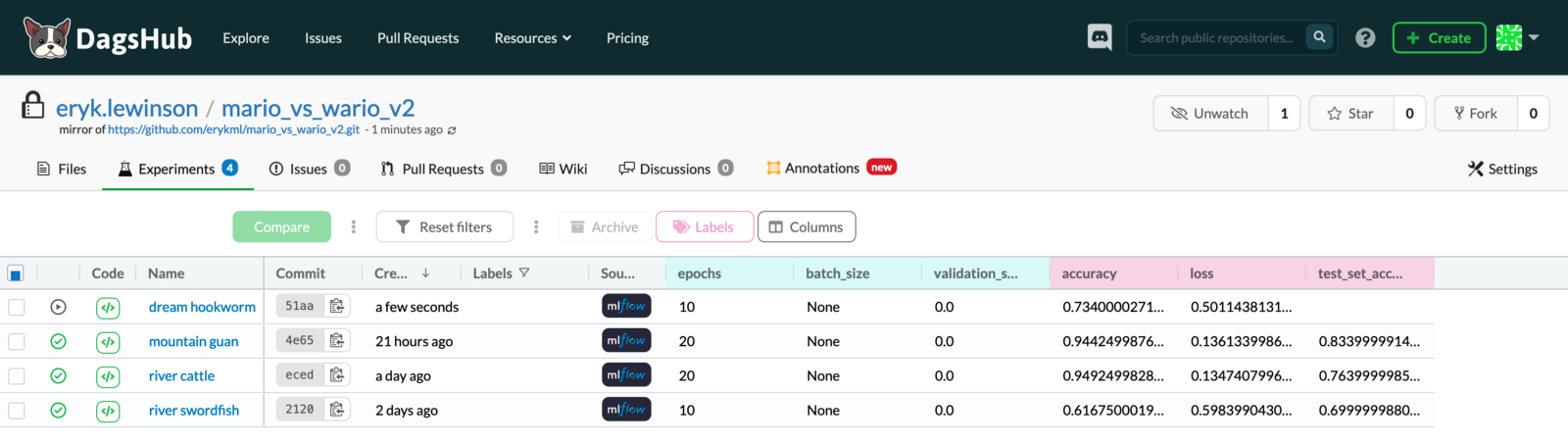
\ 这将是关于实验跟踪实施的所有细节。继续检查一些结果,下图展示了一个名为Dream hookworm的实验仍在运行的状态——我们看到随着模型的训练而更新了准确性和损失。
\
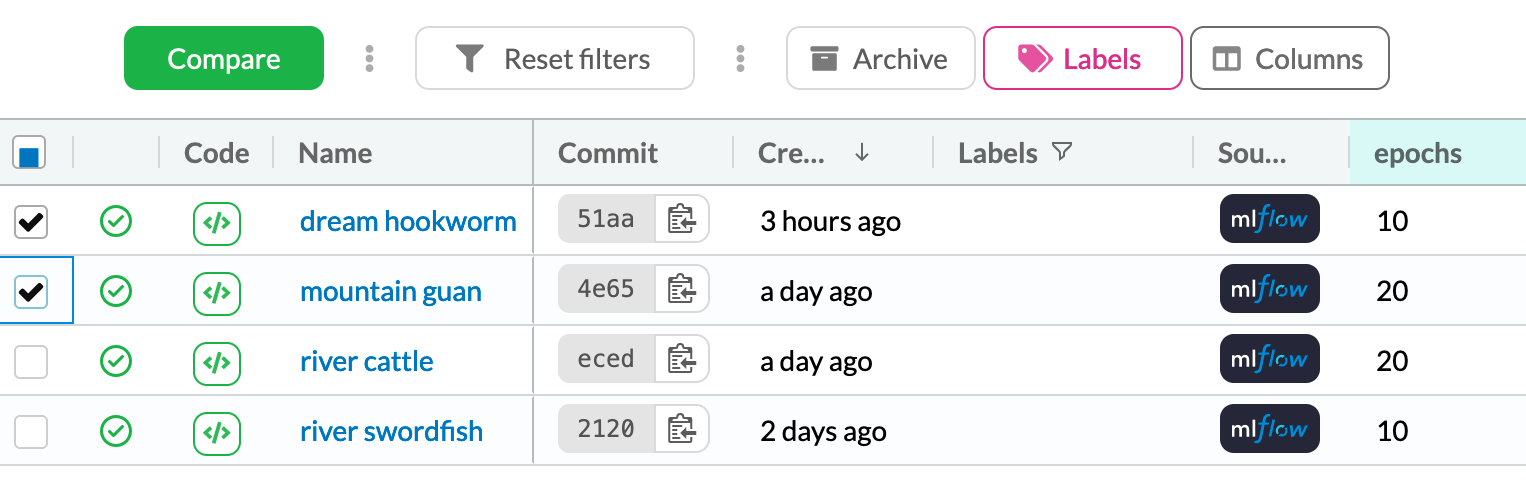
\ 在Experiments选项卡中,我们可以标记我们想要比较的变体并按下比较按钮。
\
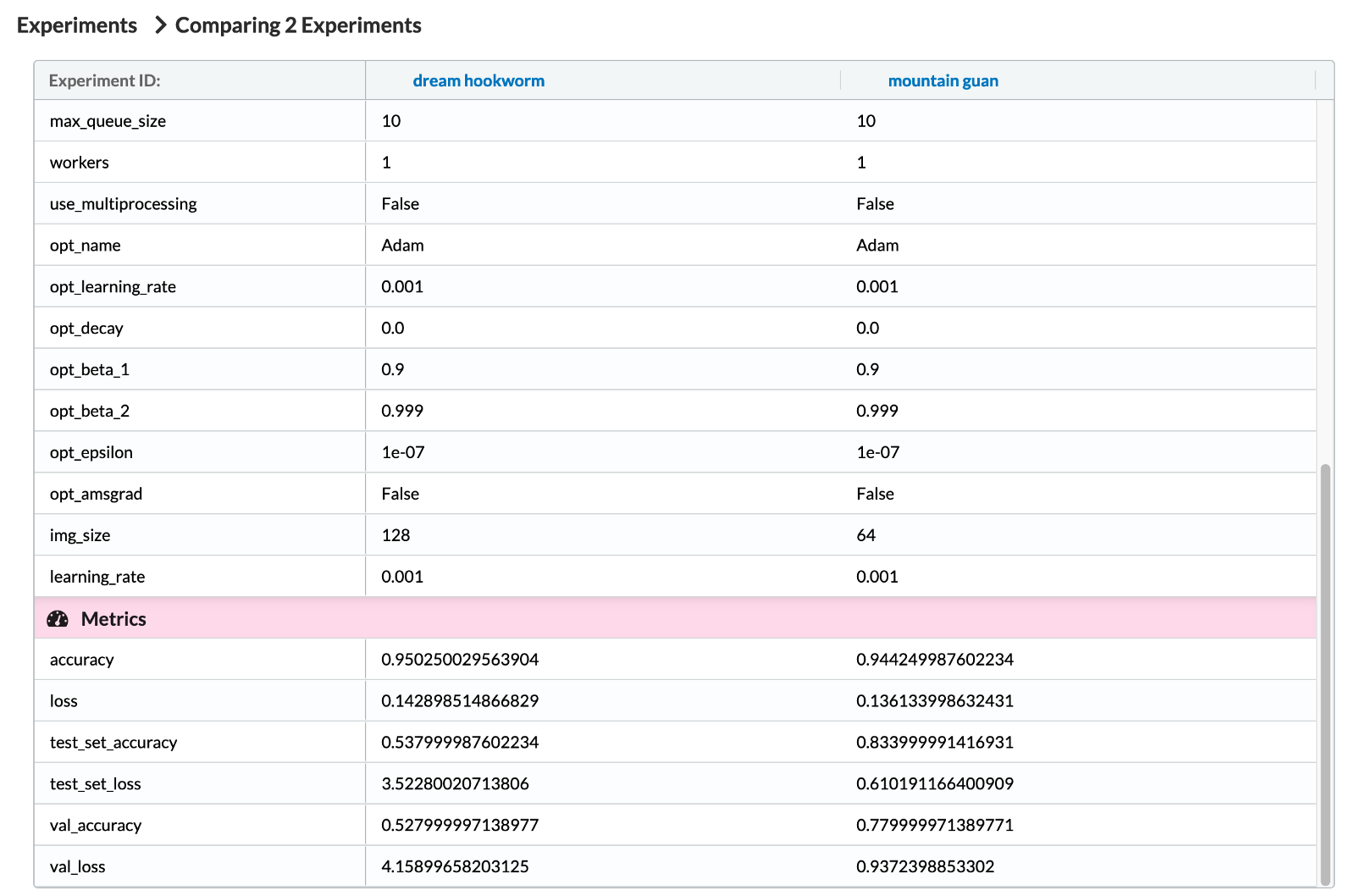
\ 在下图中,我们看到了 MLFlow 跟踪的一些超参数。正如您可能已经猜到的那样,我们看到了很多超参数,因为我们使用的是 MLFlow 的 TensorFlow 自动记录器。在列表的最后,你还可以看到我们手动添加的超参数img_size 。之后,我们可以看到相关的指标。
\
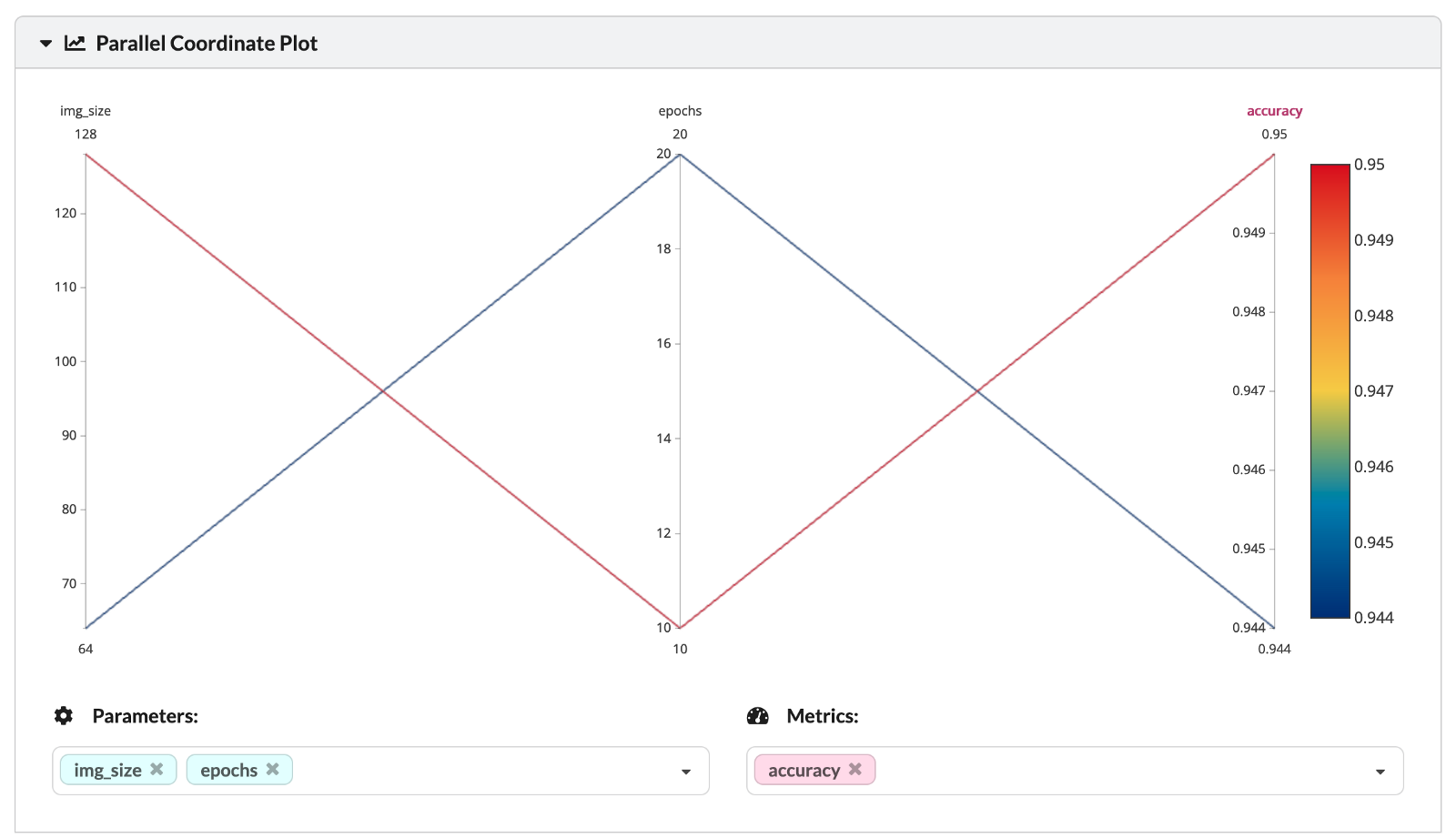
\ 这两个分析的实验在两个超参数上有所不同——时期数和考虑的图像大小(传递到 NN 第一层的方形图像的大小)。您还可以在下面的平行坐标图中看到超参数的值和相应的训练集精度。
\
最后,我们可以更深入地分析实验的各种性能指标。
\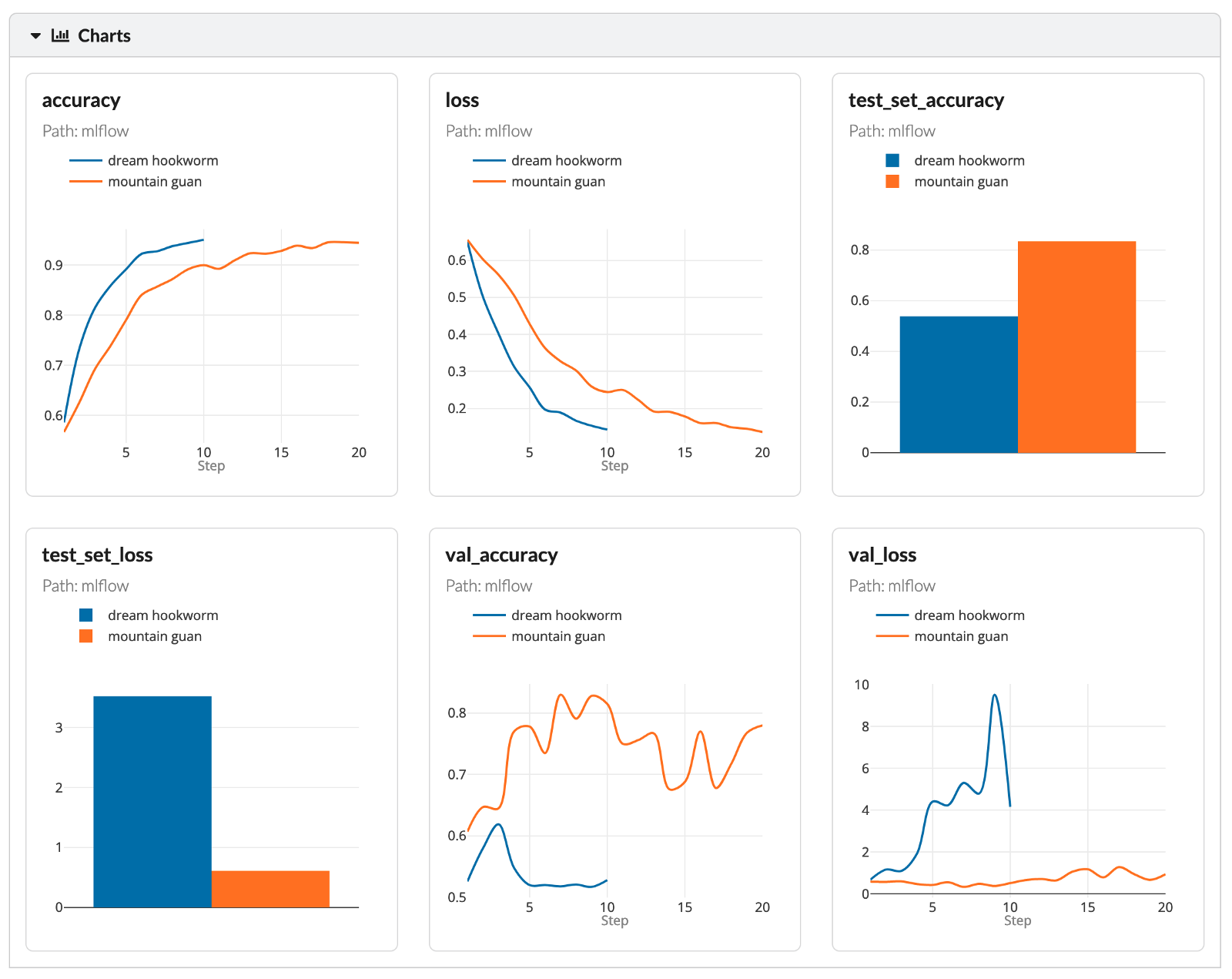
由于这部分的目的只是展示 MLFlow 跟踪的功能,我们不会花更多时间分析实验结果。
使用 GitHub Actions 和 Deepchecks 自动执行数据完整性检查
作为我们项目的最后一步,我们希望为我们的数据创建自动健全性检查。让我们用一个可以应用于我们项目的假设示例来说明这一点。在诸如所考虑的那些(横向滚动平台游戏类型)的视频游戏中,绝大多数时间都花在尝试完成某个级别或只是探索上。我们看到我们的主角跑来跑去做事(主要是跳跃)。
\ 但是,与所有游戏一样,还有一些其他屏幕(菜单、黑白转换或加载屏幕、片尾字幕等)。我们可以争辩说这些不应该包含在数据中。因此,让我们假设我们手动浏览图像并删除了我们认为不适合我们的数据样本的图像。这可能会引发一个问题:我们的行为是否显着改变了数据中的某些内容,例如类别的平衡?或者,也许我们引入了一些其他的偏见?
\ 当我们的一些数据转换涉及裁剪图像时,这也可能非常相关——我们可以从一个类中删除一些 HUD(游戏术语、平视显示器或简单的状态栏*)*,同时将它们保留在另一个类中.这将导致创建一个分类器,该分类器仅检查该特定像素是否具有 X 值,然后自信地决定图像来自哪个游戏。
\ 对于这种情况,最好有一些自动化的数据完整性检查。我们将展示如何使用 GitHub Actions 和 Deepchecks 构建它们。但首先,我们需要回答一些辅助问题。
什么是 GitHub 操作?
GitHub Actions是用于自动化软件工作流程的工具。例如,软件工程师使用 GitHub Actions 来自动执行诸如合并分支、处理问题、运行单元或应用程序测试等操作。
\ 然而,这并不意味着它们对数据科学家毫无用处。我们可以将 GitHub Actions 用于许多事情,包括:
- 自动化 ETL 流程,
- 检查当前模型是否应该重新训练,
- 部署新模型,
- 运行自动数据完整性检查。
\ 关于 GitHub Actions 的一些注意事项:
- 支持用于数据科学的主要编程语言:Python、R、Julia 等。
- 公共存储库免费,私有存储库每月提供 2,000 分钟(对于免费的 GitHub 帐户),
- 与主要的云提供商合作得很好,
- 每当工作流程失败时自动发送电子邮件,
- GitHub Action 的机器不适合计算量很大的任务,例如训练深度学习模型。
什么是深度检查?
简而言之, deepchecks是一个用于测试 ML/DL 模型和数据的开源 Python 库。该库可以帮助我们解决整个项目中的各种测试和验证需求——我们可以验证数据的完整性、检查分布、确认有效的数据拆分(例如,训练/测试拆分),并评估我们模型的性能,和更多!
GitHub 操作 + 深度检查
此时,是时候结合这两个构建块,在我们每次向代码库推送一些更改时自动生成数据有效性报告。
\ 首先,我们创建一个脚本,使用deepchecks生成数据有效性报告。我们将使用库的默认套件(在deepchecks的术语中,这对应于检查集合)用于验证训练/测试拆分的正确性。目前, deepchecks为表格和计算机视觉任务提供套件,但是,该公司也在开发 NLP 变体。
\ https://gist.github.com/erykml/248a6599236fab145e0ab5da4c35d90c
\ 此外,我们可以在使用run方法时指定一个拟合模型的实例。但是,在撰写本文时, deepchecks支持拟合scikit-learn和 PyTorch 模型。不幸的是,这意味着我们的keras CNN 将无法工作。但这可能会在不久的将来改变,因为deepchecks仍然是一个相对较新且不断开发的库。运行脚本将导致在根目录中生成 HTML 报告。
\ 现在是时候安排运行健全性检查了。幸运的是,使用 GitHub Actions 非常简单。我们只需要将.yaml文件添加到.github/workflows目录。在这个.yaml文件中,我们指定了以下内容:
- 工作流的名称
- 工作流的触发器——可以是一个 cron 计划,或者在我们的例子中,向主分支推送或拉取请求
- 工作流的权限
- 工作流将运行的操作系统(Ubuntu、Windows 或 macOS)——不同的系统在几分钟内定价不同!
- 我们想要访问的环境变量(用于存储秘密)。要使用它们,我们首先需要在我们的 GitHub 存储库中定义它们。为此,请在 repo 中转到 Settings > Security > Secrets > Actions。
- 工作流应该执行的步骤
\ https://gist.github.com/erykml/21c60f22655796b89859c2c02b1f9d73
\ 脚本执行以下步骤:
- 在 Ubuntu 上设置 Python 3.10 实例。
- 从
requirements.txt安装依赖项。 - 从 DVC 中提取数据——在这一步中,我们需要使用用户名和密码(存储为 GitHub Actions 机密)进行身份验证。我们只从生成训练/测试拆分的 DVC 管道阶段提取数据。
- 如果存在旧的验证文件,则删除它。
- 运行生成数据验证报告的脚本。
- 提交文件(使用模板操作:
stefanzweifel/git-auto-commit-action@v4)。 - 添加评论(使用模板操作:
peter-evans/commit-comment@v1)。
\ 将此文件提交到 GitHub 后,我们将在Actions选项卡中看到我们的新工作流程。
\
我们可以更深入地查看工作流程的所有步骤以及详细的日志。当出现问题并且我们需要调试管道时,这些肯定会派上用场。
\
工作流完成后,我们可以看到 GitHub 机器人对我们的提交发表了评论。
\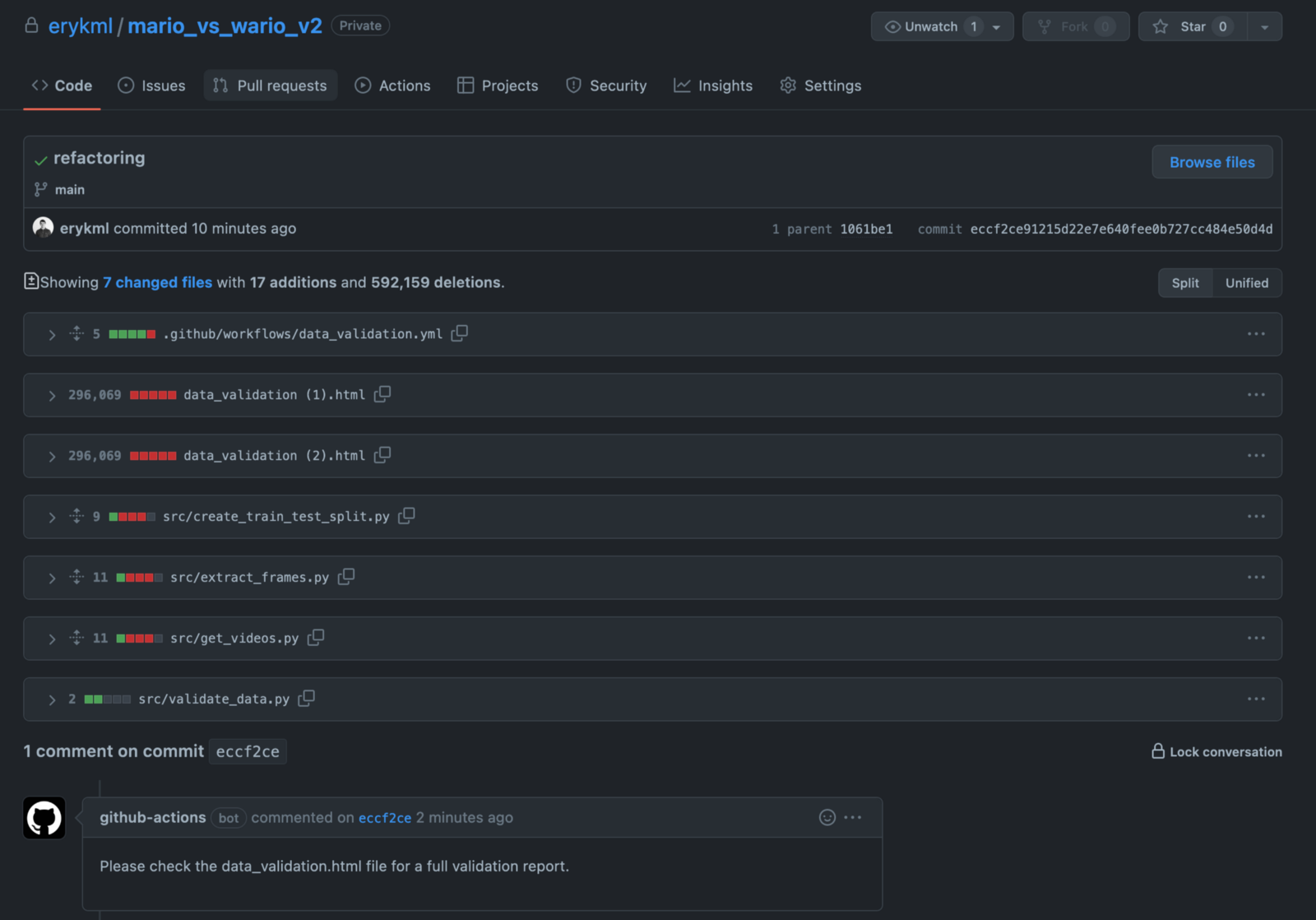
\ 现在最有趣的部分——我们可以在我们的存储库中找到data_validation.html报告。它是由 GitHub 机器人自动添加和提交的。要在本地也有它,我们只需要从 repo 中提取。
\ 为简洁起见,我们仅提供数据验证报告的部分内容。对我们来说幸运的是,该库还生成了有关检查的有用注释——它们是什么以及需要注意什么。
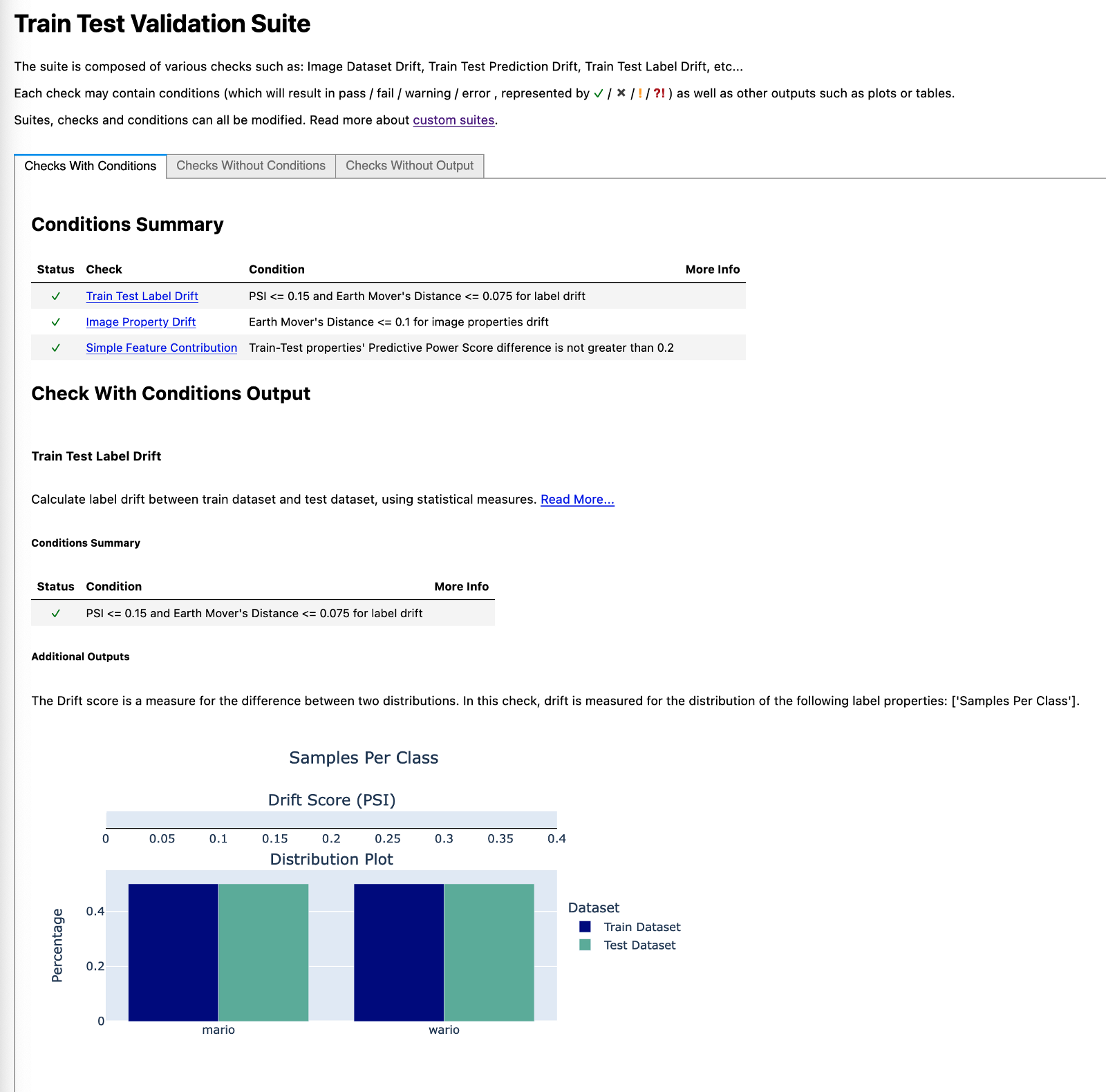
\ 在第一张图片中,我们可以看到类是完美平衡的。这应该不足为奇,因为这正是我们定义拆分的方式。
\
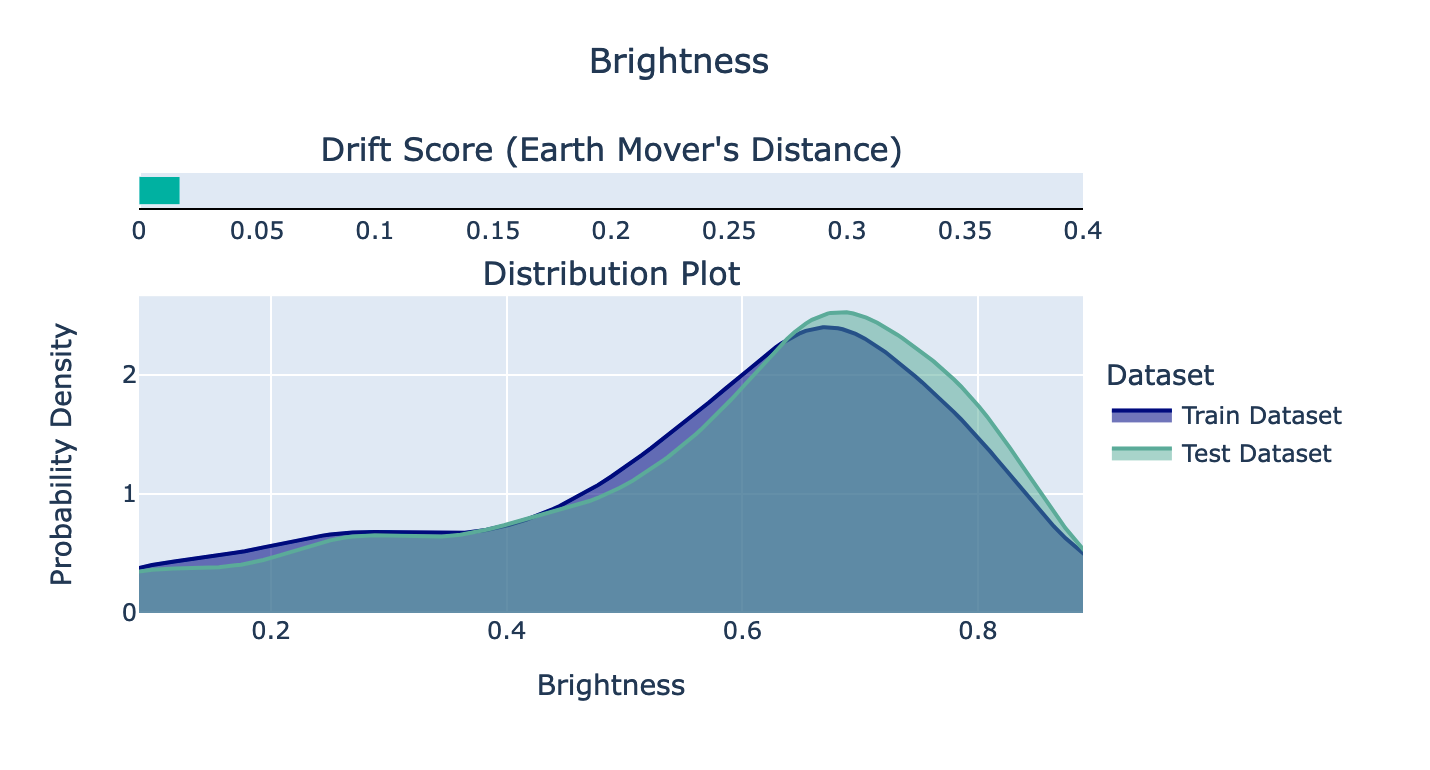
\ 在第二张图像中,我们可以看到图像在训练集和测试集上的亮度分布图。似乎拆分成功了,因为它们非常相似。根据文档,如果漂移分数(Earth Mover 的距离)高于 0.1,那将是令人震惊的。
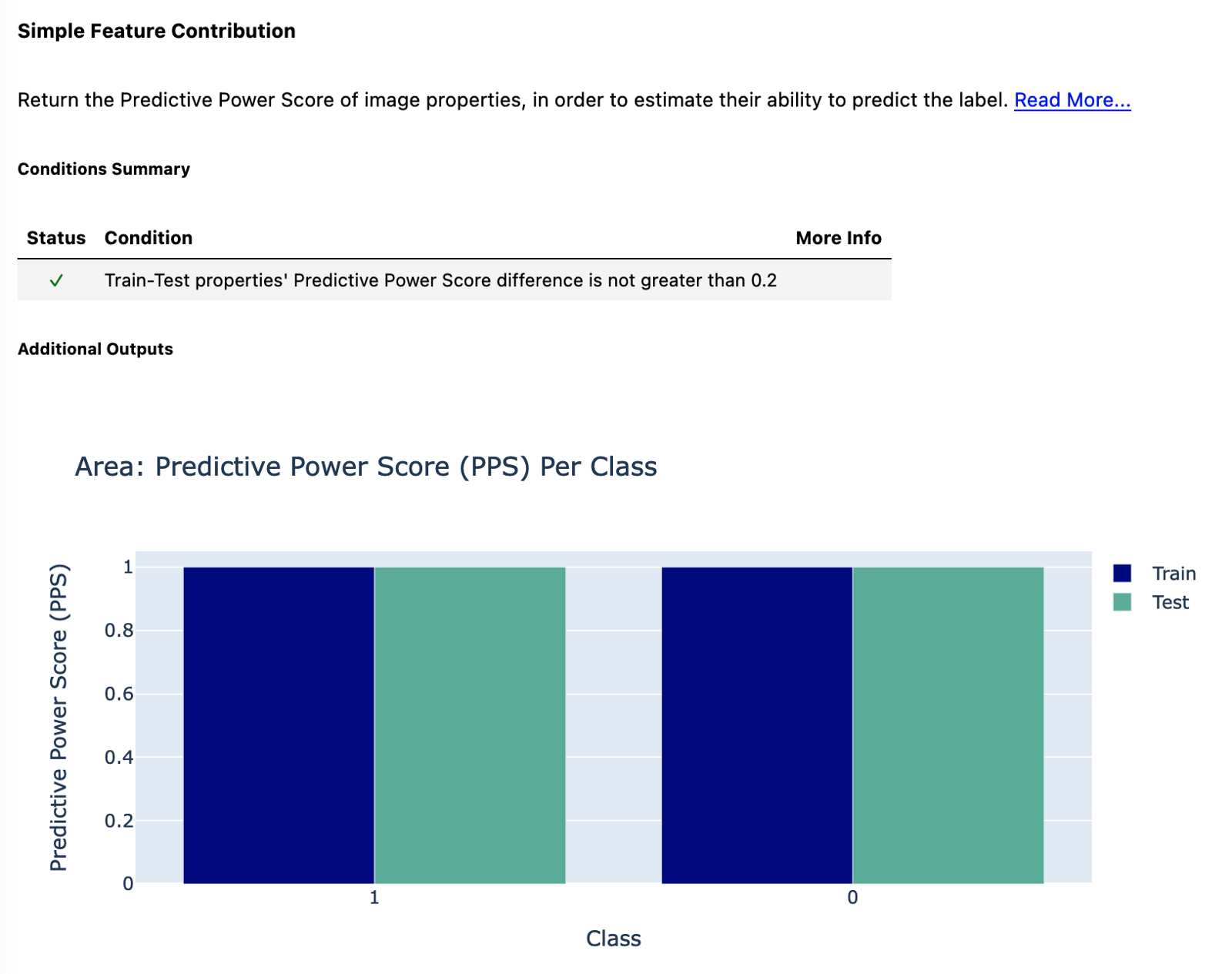
\ 最后,我们查看图像区域的预测能力得分。正如您在评论中看到的,PPS 的差异应该不大于 0.2。该条件得到满足,因为我们对所有类和数据集都有一个完美的 PPS 1。这是为什么?只是来自两个视频游戏的图像大小不同。马里奥游戏的图像为 160×144,而 Wario 游戏的图像为 320×288(两倍大小)。这可能只是因为视频是使用不同的模拟器设置录制的(最初,游戏是针对同一个控制台的,因此它们具有相同的输出大小)。虽然这意味着我们可以使用图像的区域来完美地预测类别,但在实际模型中并非如此,因为我们在使用ImageDataGenerator加载图像时确实会重塑图像。
\
还有更多
我们已经在本文中介绍了很多内容。从单个 Jupyter Notebook 中的所有内容到具有数据版本控制和实验跟踪的完全可重现的项目。话虽如此,我们仍然可以在项目之上添加一些东西。想到的有:
- 诗歌——用于改进依赖管理。
- hydra — 一个用于管理配置文件的库,即从 Python 脚本内部访问存储在某个配置文件中的参数。它对于避免硬编码某些值很有用。
- pre-commit——我们可以设置一个过程,使用选择的格式化程序(例如black k)自动格式化 Python 代码,检查代码的样式和质量( flake8 ),对导入列表进行排序( isort )等。
- 为我们的自定义函数添加单元测试。
包起来
在本文中,我们展示了一种现代方法来创建具有代码和数据版本控制、实验跟踪和自动化部分活动(例如创建数据完整性检查报告)的 ML/DL 项目。它肯定比拥有一个 Jupyter Notebook 需要更多的工作,但额外的努力很快就会得到回报。
\ 在这一点上*,* 我要感谢 DAGsHub 支持帮助解决一些问题。
\ 你可以在我的GitHub或DagsHub上找到本文使用的代码。此外,欢迎任何建设性的反馈。您可以在Twitter 上与我联系。
资源
DVC
- https://dvc.org/
- https://realpython.com/python-data-version-control/
- https://towardsdatascience.com/introduction-to-dvc-data-version-control-tool-for-machine-learning-projects-7cb49c229fe0
- https://towardsdatascience.com/the-ultimate-guide-to-building-maintainable-machine-learning-pipelines-using-dvc-a976907b2a1b
MLFlow
Keras 中的数据增强
深度检查
- https://deepchecks.com/
- https://github.com/deepchecks/deepchecks
- https://docs.deepchecks.com/en/stable/auto_tutorials/index.html
GitHub 操作
- https://github.com/features/actions
- https://neptune.ai/blog/continuous-integration-for-machine-learning-with-github-actions-and-neptune
\ \ \