光线追踪效果在 AAA 游戏中得到了越来越多的采用,在传统的“超级”设置之外添加了额外的图形质量层。作为回应,AMD 不断推进其光线追踪实施。通常,这涉及使 GPU 的通用架构适应光线追踪工作负载的特征。在 RDNA 4 上,示例包括“乱序”内存访问和动态寄存器分配。两者都针对光线追踪,但其他应用程序也可以受益,尽管程度可能不同。

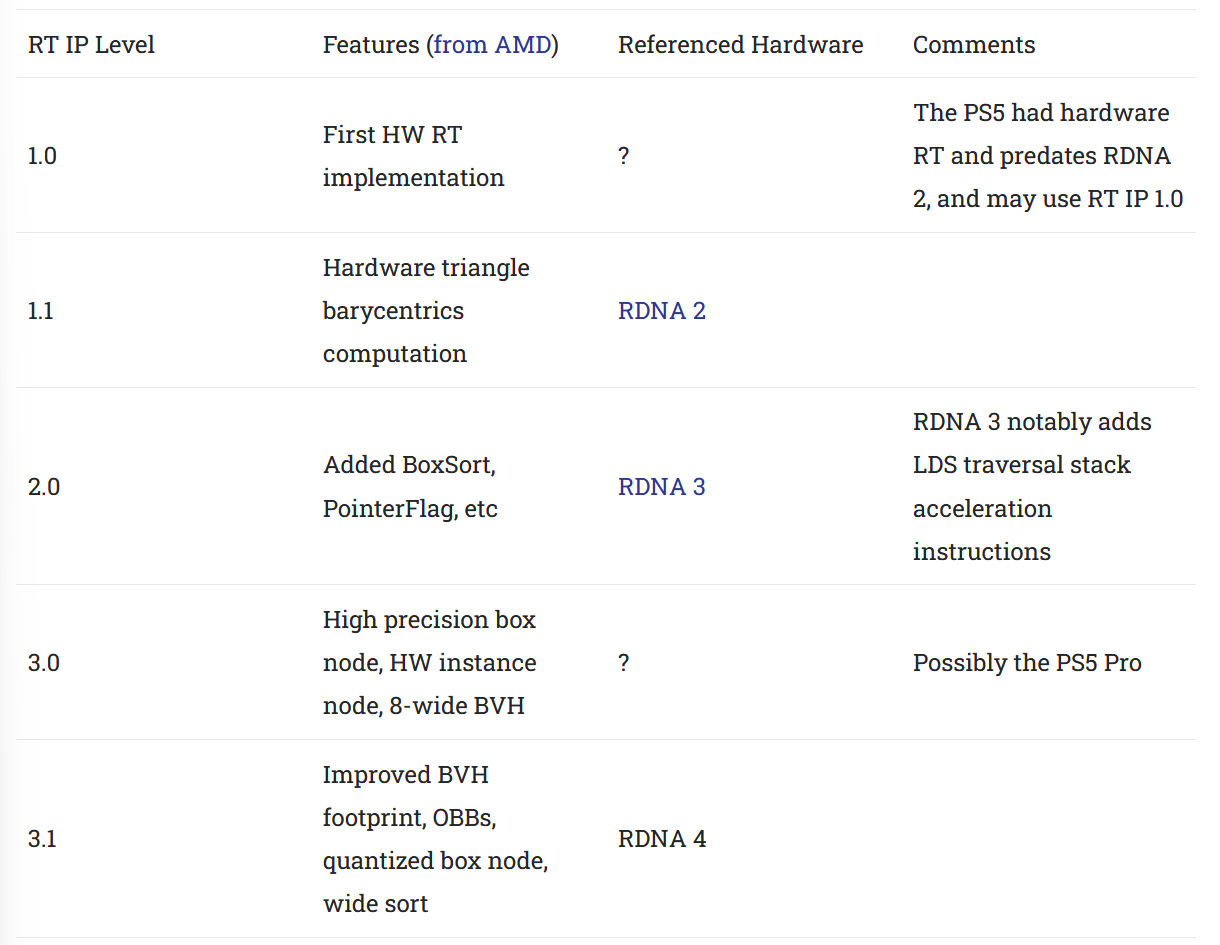
与 RDNA 3 相比,RDNA 4 的 RT IP 3.1 获得了双倍交叉测试、定向边界框、原始压缩和其他优点。固定功能硬件与预定义的数据结构紧密相关,AMD 毫不奇怪地更新了这些数据结构以利用这些更新的功能。
双交叉口发动机,更宽的 BVH
RDNA 4 的双倍交叉测试吞吐量内部来自于在每个射线加速器中放置两个交叉引擎。 RDNA 2 和 RDNA 3 射线加速器大概有一个交叉引擎,每个周期能够进行四个盒子测试或一个三角形测试。 RDNA 4 的两个交叉引擎一起可以在每个周期进行八个盒子测试或两个三角形测试。更宽的 BVH 对于利用额外的吞吐量至关重要。
光线追踪使用边界体积层次结构 (BVH) 递归地细分场景几何体。每个节点代表一个 3D 盒形空间,并链接到子盒。相交测试确定要遵循哪个链接(子),直到遍历到达树的底部,其中节点包含三角形数据而不是到子框的链接。因此,每个遍历步骤都会将交叉搜索范围缩小到较小的框。更多的交叉测试吞吐量可以加快此遍历过程。
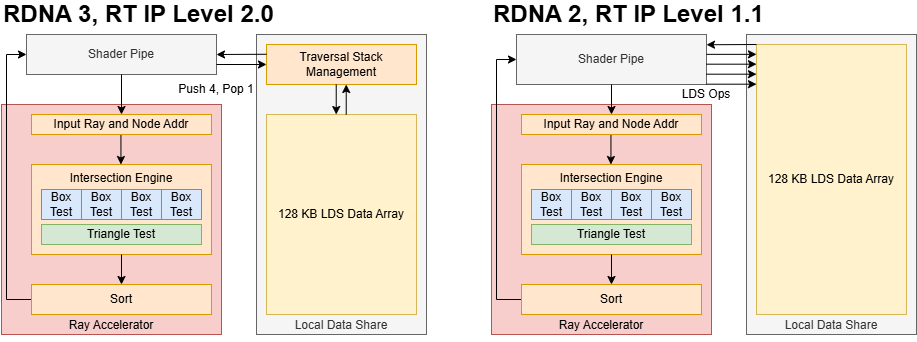
但加快遍历并不像将交叉口测试吞吐量加倍那么简单。每个遍历步骤都是一个指针追逐操作,这会产生内存延迟。与 CPU 相比,GPU 具有较高的缓存和 DRAM 延迟,但在并行计算方面表现出色。 RDNA 4 从 RDNA 2 和 3 中的 4 宽框节点增加到 8 宽框节点。更宽的框节点在每个步骤中提供更多并行工作。更重要的是,它允许“更胖”的树需要更少的遍历步骤来到达底部。因此,8 宽 BVH 将重点从延迟转移到吞吐量,避免了 GPU 的关键弱点。
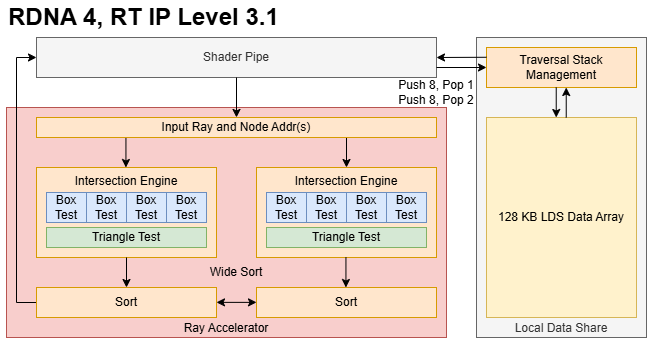
自 RDNA 2 起,AMD 使用了保守的光线追踪策略,其中着色器程序控制从光线生成到结果着色的光线追踪过程。在 BVH 遍历期间,光线跟踪着色器使用新的IMAGE_BVH8_INTERSECT_RAY指令访问 RDNA 4 的光线加速器。该指令采用一条射线和一个指向 8 宽 BVH 节点的指针,并同时使用两个交叉引擎。两个交叉点引擎的输出都发送到排序单元,该单元可以分别对两个 4 宽半部分进行排序,也可以使用“宽排序”选项对所有八个结果进行排序。为了加快遍历速度,自 RDNA 3 起,AMD 在 LDS 中提供了硬件遍历堆栈管理。LDS 堆栈管理在 RDNA 4 中使用新的DS_BVH_STACK_PUSH8_POP1_RTN_B32指令进行了更新1 。
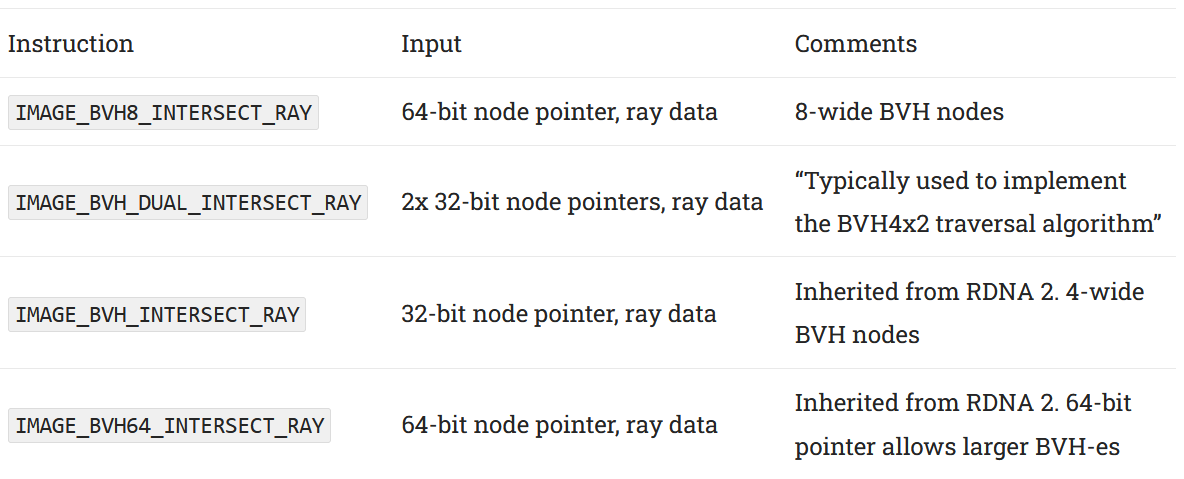
8 宽 BVH 并不是使用 RDNA 4 双倍交叉测试吞吐量的唯一方法。 RDNA 4 添加了IMAGE_BVH_DUAL_INTERSECT_RAY指令,该指令采用一对 4 宽节点,并且还使用两个交叉引擎。与 BVH8 指令类似, IMAGE_BVH_DUAL_INTERSECT_RAY生成两对 4 相交测试结果,并可以通过“宽排序”选项混合八个结果。遍历端同样获得DS_BVH_STACK_PUSH8_POP2_RTN_B64指令。 AMD没有描述“BVH4x2”遍历算法,但不难想象上面两条指令的作用是什么。一条射线可以与多个边界框相交,从而创建多个遍历路径。 BVH4x2 几乎肯定会并行采用其中两条路径,其中两条路径从 LDS 中弹出,并在每个遍历步骤中在射线加速器中进行测试。
到目前为止,我只看到 AMD 为 RDNA 4 生成 8 宽 BVH-es。其中包括 DirectX 12 的程序几何示例、3DMark 测试、Cyberpunk 2077、Elden Ring、GTA V 增强版和 Quake 2 RTX。 BVH4x2 遍历的效率低于使用 8 宽 BVH,因为它需要更多内存访问并生成更多 LDS 流量。此外,BVH4x2 依赖于至少有两个有效的遍历路径来完全供给射线加速器,并且这种情况发生的频率可能会根据所讨论的射线而有很大差异。我不知道为什么 AMD 添加了一种方法来利用具有 4 宽 BVH 的交叉引擎。
定向边界框
BVH-es 传统上使用轴对齐边界框 (AABB),这意味着框的边界与 3D 世界的 x、y 和 z 轴对齐。轴对齐的框简化了相交测试。然而,游戏几何体通常不是轴对齐的。在这些情况下,轴对齐的框最终可能会比它试图包含的几何图形大得多,从而创建大量空白空间。在进一步的相交测试意识到该路径是无用的之前,与空白空间相交的光线最终会在盒子中采取无用的遍历步骤。
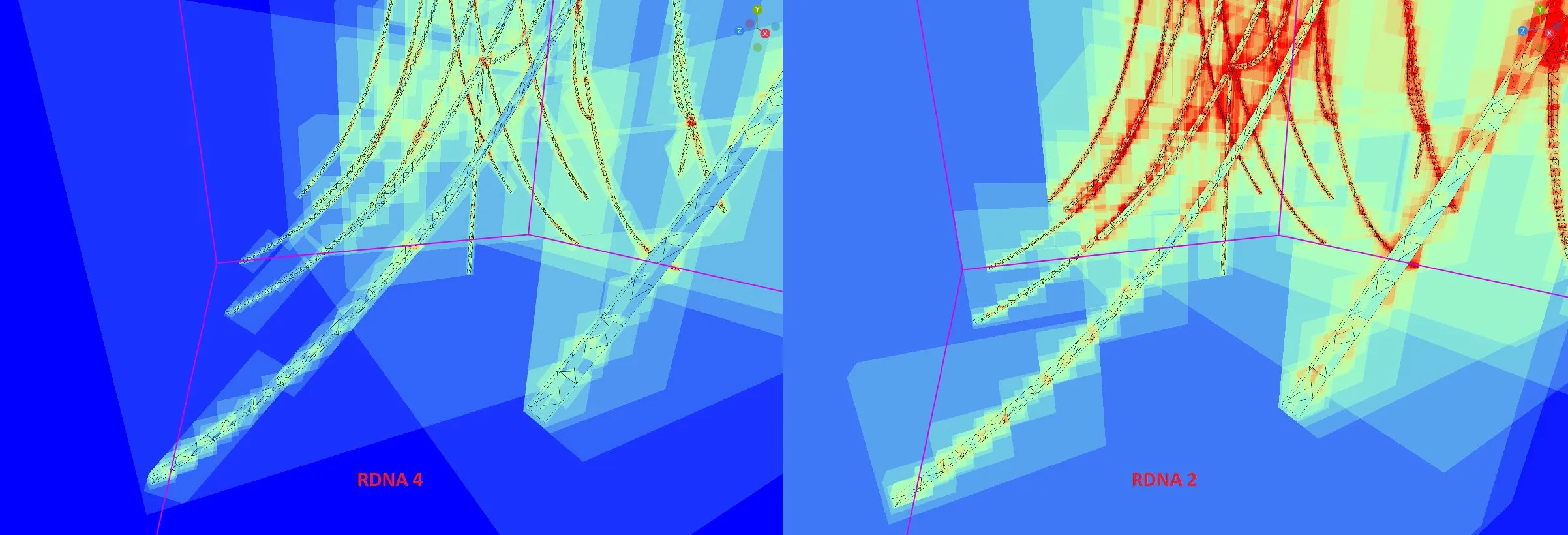
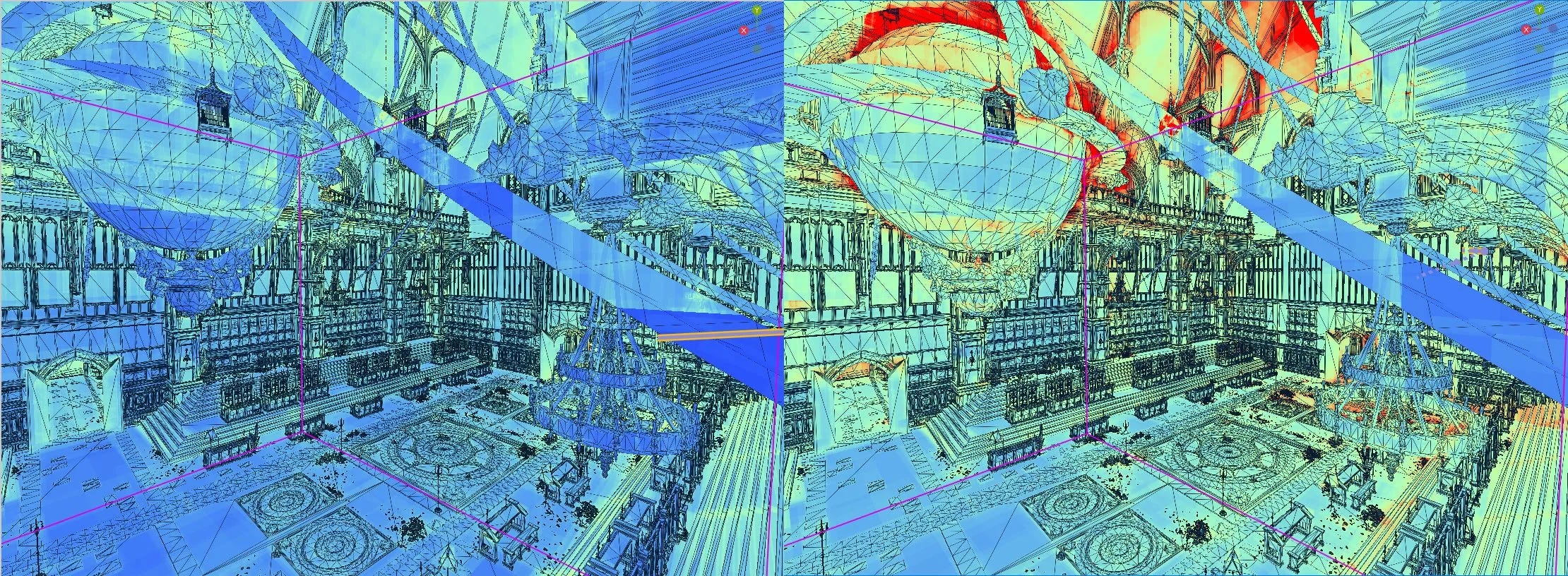
Elden Ring 辩论室天花板上悬挂着链条(左侧为 RDNA 4,右侧为 RDNA 2)。 RDNA 4 OBB 比 RDNA 2 上的轴对齐框更适合几何形状。屏幕截图来自 Radeon Raytracing Analyzer,具有匹配的遍历计数
RDNA 4 通过定向边界框 (OBB) 解决了这个问题,其中边界框被旋转以更好地近似其中的几何形状。为每个盒子存储 3×3 3D 旋转矩阵会显着增加内存使用量。因此,RDNA 4 做出了妥协。每个盒子节点仅为其所有子节点指定一次 OBB 旋转。为了进一步节省存储空间,OBB 矩阵根本不存储在节点中。相反,该节点存储 OBB 矩阵索引,可在包含 104 个预定义矩阵的表中查找该索引。在代码中,矩阵存储为 9 个打包的 6 位索引,它们引用具有 26 个唯一 FP32 值3 的二级查找表中的条目。

因此,AMD 的 OBB 策略采取尽力而为的方法,以最小的存储成本减少无用的框交叉点。它并不是每次都尝试生成完美的最佳边界框旋转。得益于此策略,8 宽框节点的大小保持在 128 字节的合理大小,并继续匹配 RDNA 的缓存行长度。虽然代码中指定的查找表不一定显示确切的硬件实现,但简单计算表明查找表将使用大约 800 字节的存储空间。这将使其足够小,可以装入射线加速器内的小型 ROM 中。
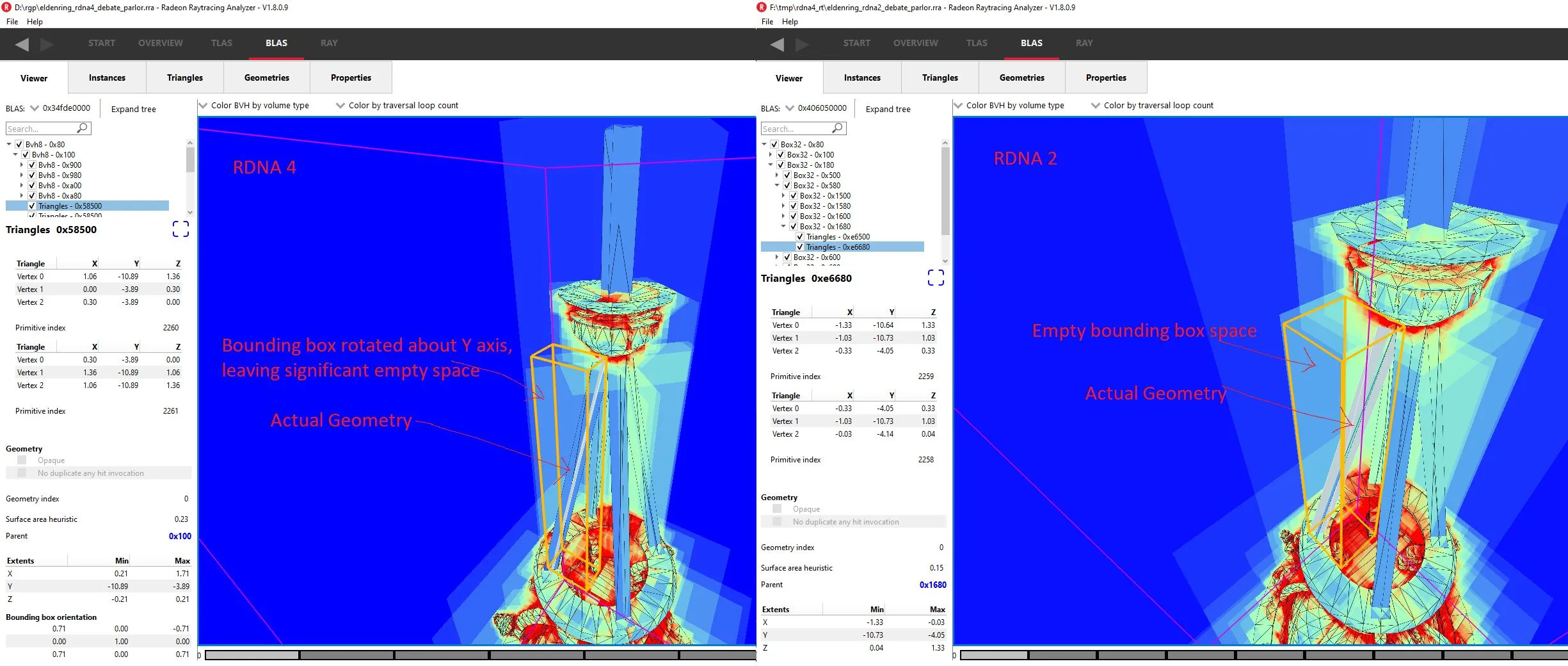
妥协当然会留下改进的空间。 Elden Ring 辩论室天花板上悬挂的链条为 RDNA 4 的 OBB 提供了最佳案例,因为一次旋转可以很好地适应每一侧的所有链条。枝形吊灯则是另一回事,有四个支撑链,每个支撑链都有不同的旋转。 AMD 选择与 Y(上)轴链条旋转匹配的 OBB,但与 X/Z 轴不匹配。因此,每条链的 OBB 都会留下大量空白空间,可能导致错误交叉。它仍然比 RDNA 2 的对齐边界框更好,但显然还有改进的空间。
在盒子上使用一次 OBB 旋转可能是一种必要的妥协。处理 OBB 相交测试的一种简单方法是旋转入射光线,使盒子和光线轴对齐(只是使用一组不同的轴)。 RDNA 4 在光线加速器中添加了光线变换块。 AMD 没有明确表示变换块有助于 OBB。相反,它用于顶层和底层加速结构 (TLAS/BLAS) 之间的转换。 DirectX 光线追踪将 BVH 分为两个级别,因为 BLAS 可以以不同的位置和旋转多次重复使用。这对于处理同一对象的多个副本非常方便,例如在房间内多次放置相同类型的椅子。
…添加专用的射线变换块,这用于卸载当您从射线加速结构的顶层过渡到底层时发生的变换…
AMD Radeon 新闻发布会视频
TLAS 到 BLAS 的转换涉及旋转射线以允许在 BLAS 内进行轴对齐相交测试,这与旋转射线进行 OBB 测试的操作类似。一个关键区别是涉及 OBB 的遍历步骤可能比 TLAS 到 BLAS 转换更频繁地发生。 AMD 的射线加速器旨在每个周期处理一个盒子节点。变换光线需要将原点向量和方向向量乘以 3×3 旋转矩阵,每次变换需要 36 次 FLOP(浮点运算)。在 2.5 GHz 下,RX 9070 射线加速器的射线变换速度为 5.04 TFLOP/s。为盒子节点中的所有八个盒子提供不同的光线旋转将使该数字乘以八。
AMD 还可以在交叉引擎中实现 OBB 相关的光线变换。 RDNA 4 可以使用带有 RDNA 2/3 传统 4 宽框节点的 OBB,将 OBB 矩阵 ID 滑入 128B 结构末尾附近以前未使用的填充位中。 BVH4x2 遍历可能会遇到指定不同 OBB 旋转的两个节点。这需要应用两次光线变换来完全满足两个交叉引擎的需求。即使在这种情况下,两次光线变换的成本也远低于八次,因此 AMD 的妥协是有道理的。
原始节点压缩
最大限度地减少 BVH 足迹至关重要。较小的 BVH 可减少 VRAM 消耗、降低带宽要求并更经济地利用缓存容量。 RDNA 2 和 RDNA 3 采取了压缩三角形对的基本步骤,其中 64 字节三角形节点可以存储一对共享一条边的三角形。英特尔也这样做。 RDNA 4 更进一步,将多个三角形对打包到新的 128 字节压缩基元节点中。
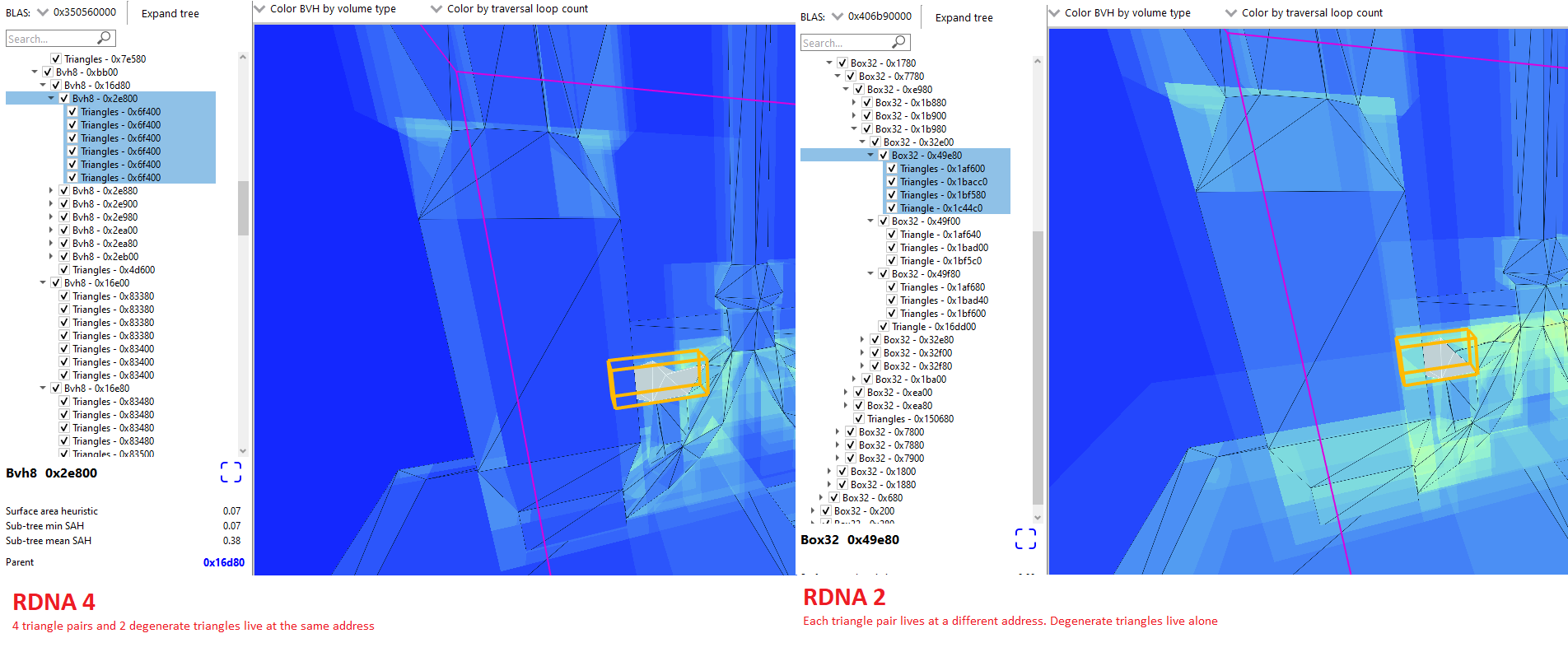
RDNA 4 的压缩基元节点仅存储其三角形对上的唯一顶点。进一步的收益来自于找到跨顶点坐标按位 FP32 表示的尾随零的最小数量,并从存储中删除这些尾随零5 。 代码表明RDNA 4 原语节点可以描述最多 8 个三角形对或最多 16 个唯一顶点。

实际上,压缩效率根据游戏几何的性质而有很大差异,但 RDNA 4 通常在 128 字节基元节点中表示两个以上的三角形对。虽然 AMD 的演示中没有提及,但 RDNA 4 使用量化的 12 位整数而不是 FP32 值6表示框范围。这使得 RDNA 4 将其 8 宽框节点保持在 128 字节,就像 RDNA 2/3 的 4 宽框节点一样。

不是在两者之间扩展,但 RDNA 2/3 的三角形节点将元素放置在明确定义的偏移处,这允许更便宜的硬件。 RDNA 4 当然也支持 RDNA 2/3 格式,因为硬件保留了对旧 IMAGE_BVH_INTERSECT_RAY 指令的支持
与 OBB 一样,原始压缩会增加硬件复杂性。压缩的基元节点不需要射线加速器中的额外计算。然而,它们确实强制它处理非对齐的、可变长度的数据字段。交叉点引擎必须先解析 52 位标头,然后才能知道数据部分的格式。然后,前导零压缩将需要移位打包值以重建原始 FP32 值。减少内存占用通常会带来额外的硬件复杂性。在像光线追踪这样的延迟关键应用程序中,给硬件带来更高的负担可能是值得的。
BVH 优化实践
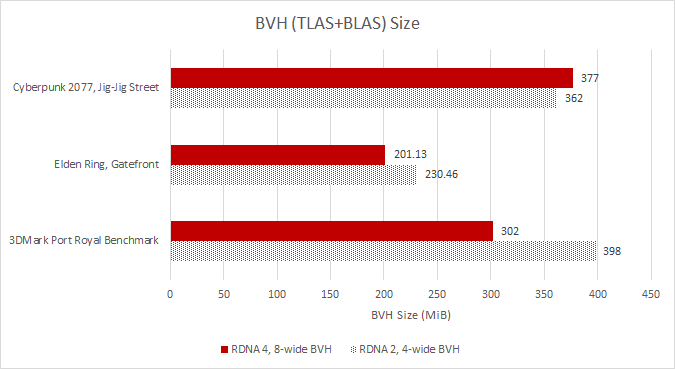
在 Elden Ring 和 3DMark 的 Port Royal 基准测试中,AMD 的 Radeon Raytracing Analyzer 表明 RDNA 4 实现了相当大的 BVH 尺寸减小。奇怪的是,同样的情况不适用于《赛博朋克 2077》。然而,《赛博朋克 2077》的环境更加动态,NPC 数量和移动路径不可预测,因此误差幅度肯定更高。
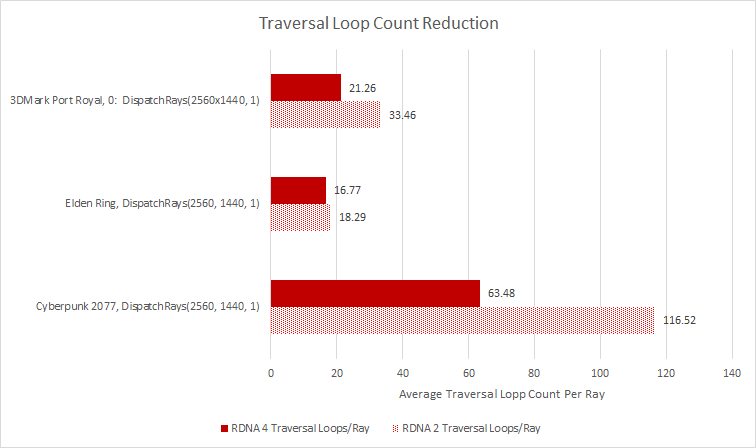
RDNA 4 最大的胜利来自于减少遍历步数。排列相应的 DispatchRays 调用表明 RDNA 4 每条光线经历的遍历步骤更少。 《赛博朋克2077》就是一个特别好的案例。总体而言,RDNA 4 仍在进行更多的交叉测试,因为每个遍历步骤需要 8 次交叉测试,而 RDNA 2 则需要 4 次,并且遍历步骤数并未减半或更少。不过,额外的工作是非常值得的。 GPU 并未针对延迟进行优化,因此用受延迟限制的指针追逐步骤来换取更多并行计算需求是一个不错的策略。相比之下,《Elden Ring》的收益较小,但考虑到 GPU 缓存延迟较高,任何减少都是值得欢迎的。
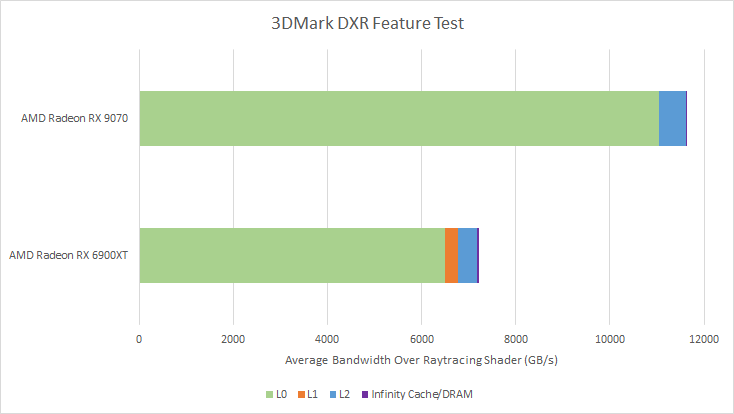
在 3DMark 的 DXR 功能测试捕获的帧中,以最小的光栅化对整个场景进行光线追踪,Radeon RX 9070 每秒分别持续 111.76G 和 19.61G 的盒子和三角形测试。为了进行比较,基于 RDNA 2 的 Radeon RX 6900XT 每秒进行 38.8G 和 10.76G 盒子和三角形测试。由于两张卡上的时钟速度不同,因此很难利用射线加速器。但假设 2.5 GHz,RDNA 4 和 RDNA 2 射线加速器的利用率分别为 24% 和 10.23%。因此,RDNA 4 能够比 RDNA 2 更好地为其更大的射线加速器提供能量。自第一代光线追踪实施以来,AMD 已经做了很多工作,累积的进展令人印象深刻。
最后的话
RDNA 2带来了AMD在PC场景中的第一个硬件光线追踪实现。它采用了一种保守的光线追踪方法,即加速相交测试,但仅此而已。自那时起,AMD 取得了稳步进展,调整 GPU 硬件和光线追踪工作负载以使其相互匹配。 RDNA 4 继续使用 RDNA 2 的高级光线追踪策略,通过计算线程管理光线追踪过程,从光线生成到遍历再到结果处理。但经过几代的努力,AMD 工程师不断进行改进,使 RDNA 4 处于领先地位。

Radeon Raytracing Analyzer 和 Radeon GPU Profiler 等 AMD 工具提供了令人着迷的视角,让您了解这些改进如何在幕后协同工作。开源代码进一步描绘了 AMD 正在不间断地开发其光线追踪硬件的情况。未使用的(可能与 Playstation 相关)RT IP 1.0 和 3.0 级别提供了有关 AMD 硬件光线追踪演变的更多快照。
尽管如此,RDNA 4仍有改进的空间。 OBB 可以更加灵活,并且一级缓存可以更大。英特尔和英伟达也是明显的竞争对手。英特尔已经透露了很多有关其光线追踪实现的信息,如果不将它们放在上下文中,任何光线追踪讨论都是不完整的。英特尔的光线追踪加速器 (RTA) 拥有遍历过程的所有权,并对其进行了严格优化,在内部寄存器中保留了专用的 BVH 缓存和短堆栈。这是一项更大的硬件投资,对一般工作负载没有好处,但确实让英特尔能够更紧密地适应固定功能硬件以满足光线追踪需求。除了使用专用缓存/寄存器而不是 RDNA 4 的通用缓存和本地数据共享的明显优势之外,英特尔还可以保持 Xe Core 线程插槽的遍历,从而使它们可以自由用于光线生成或结果处理。

AMD 的方法有其自身的优势。避免在光线跟踪管道步骤之间启动线程可以减少延迟。在可编程着色器管道上运行的光线跟踪代码自然会利用其跟踪大规模线程级并行性的能力。正如 RDNA 4 和英特尔 Battlemage 所表明的那样,这两种策略都有很大的改进空间。我很高兴看到 AMD、Intel 和 Nvidia 不断发展其光线追踪实现,一切将如何发展。
如果您喜欢这些内容,那么如果您想花一些钱购买薯条和奶酪,请考虑前往Patreon或PayPal 。还可以考虑加入Discord 。
参考
-
AMD GPU 光线追踪库中的primitiveNode.hlsli
-
AMD GPU 光线追踪库中的OrientedBoundingBoxes.hlsl和ObbCommon.hlsl
-
AMD GPU 光线追踪库中的EncodeHwBVH3_1.hlsl
-
AMD GPU 光线追踪库中的PrimitiveStructureEncoder3_1.hlsl 。描述尾随零压缩,ComputeCompressedRanges 让每个通道在 BVH 构建期间在 LDS 中查找其顶点,在位掩码中设置相应的位,然后对设置的位进行计数以查找唯一的顶点计数
-
多个 RT IP 3.1 BVH 构建函数调用 numQuantBits=12 的 ComputeQuantizedBounds,然后调用 ComputeQuantizedMin/ComputeQuantizedMax,它似乎量化为 12 位整数,因为最大值为 (1 << numQuantBits -1) * 1.0f。它是适合指定量化位的最大整数值,乘以 FP 值 1,以提供浮点数形式的最大量化值。
-
BoxNode1_0.hlsli ,为 RT IP 1.0 定义 4 宽框节点
原文: https://chipsandcheese.com/p/rdna-4s-raytracing-improvements