在Uber 2014 年服务迁移战略中,我们探索了如何从 Python 整体架构转向面向服务的架构,同时随着每六个月翻一番的用户流量进行扩展。
这张Wardley 地图探讨了该时期编排框架的演变过程,可作为确定 Uber 基础设施工程团队最有效前进路径的输入。
这是一本关于工程策略的书的探索性草稿章节,我正在#eng-strategy-book中集思广益。因此,一些链接指向其他草稿章节,包括已发布的草稿和非常早期的未发布的草稿。
阅读这张地图
要快速理解这张沃德利地图,请从上到下阅读。如果您想回顾一下这张地图是如何编写的,那么您应该从下往上逐节阅读,从用户开始,然后是价值链,依此类推。
有关此结构的更多详细信息,请参阅使用 Wardley 映射优化策略。
今天的情况如何
三个主要的内部团队参与服务提供。服务供应团队从服务器运营团队管理的服务器中抽象出产品工程开发的应用程序。随着添加更多服务器来支持应用程序扩展,这对于应用程序本身来说是不可见的,从而使产品工程师能够专注于公司最看重的事情:开发更多应用程序功能。
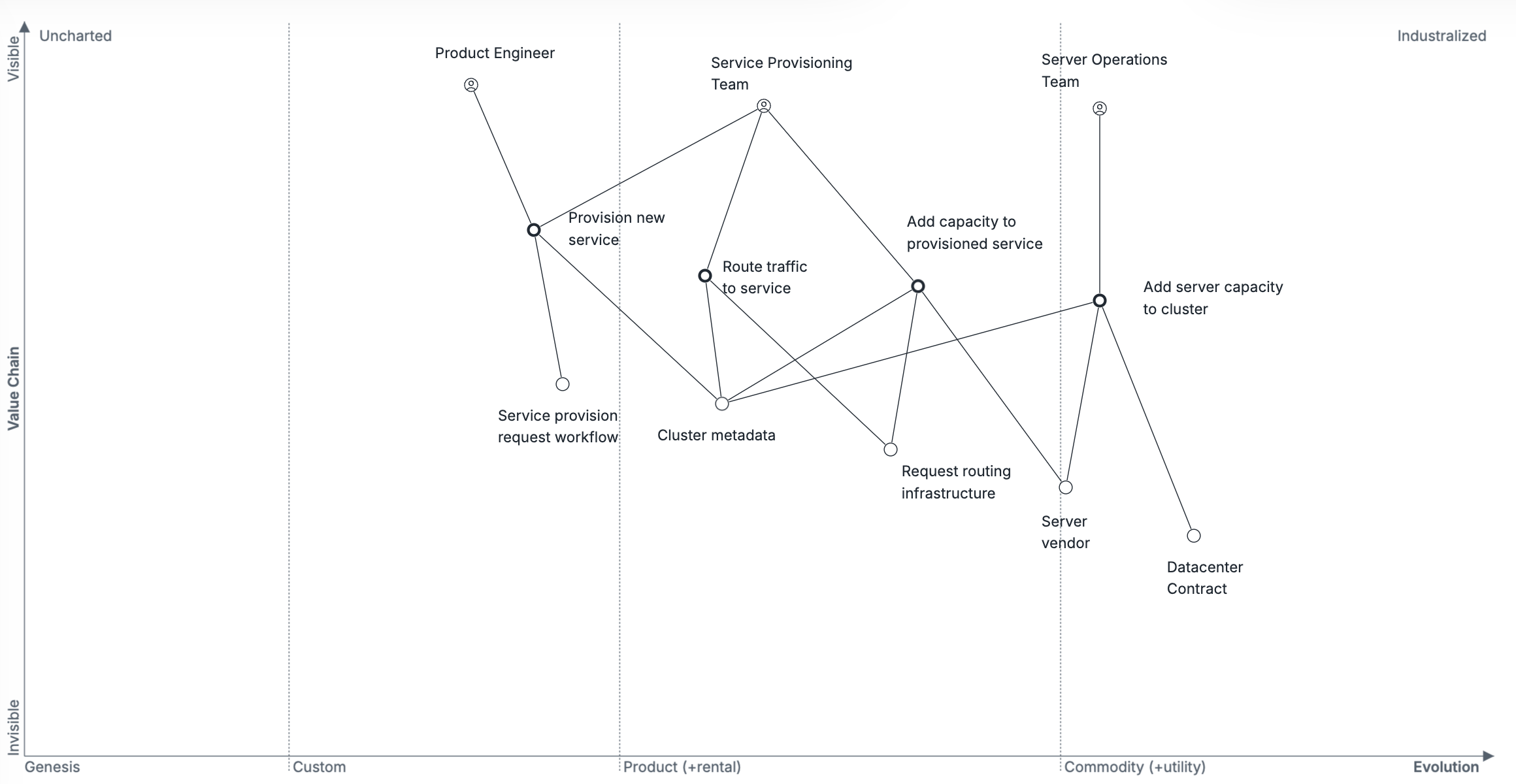
当前价值链中的挑战是经济高效的扩展、可靠的部署和快速部署。所有这三个问题都源于资源调度的同一根本问题。我们希望投入大量资金来改进我们的资源调度,并相信了解行业资源调度趋势有助于做出有效的选择。
过渡到未来状态
最有趣的集群编排问题都集中在集群元数据和资源调度上。路由请求,无论是通过 DNS 条目还是分配的端口,都取决于集群元数据。将服务映射到服务器群取决于管理集群元数据的资源调度。部署和自动缩放都依赖于集群元数据。
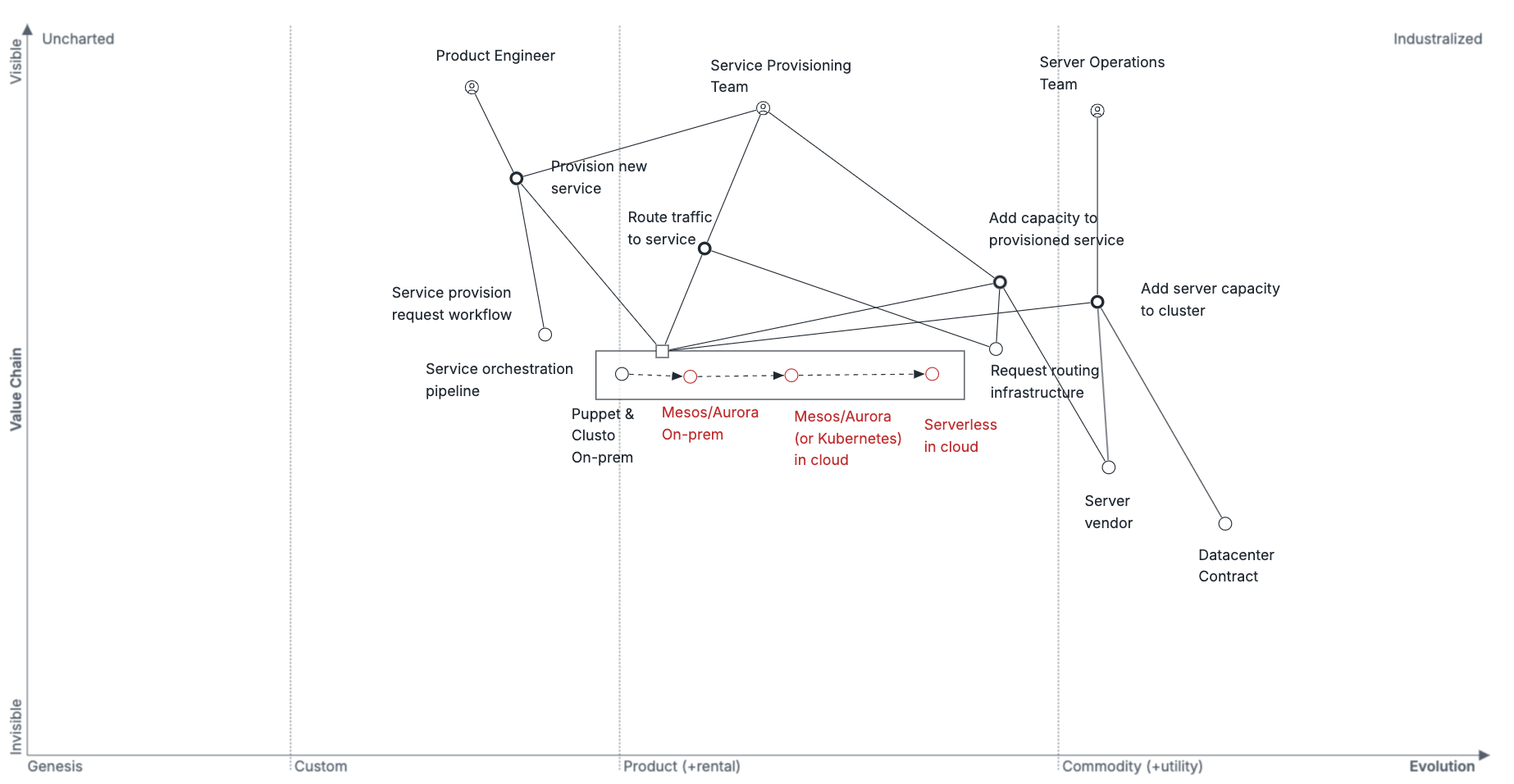
这也是我们在 2014 年看到发生重大变化的领域。
Uber 最初使用 Clusto 解决了这个问题,Clusto 是 Digg 发布的开源工具,其目标类似于 Hashicorp 的Consul ,但采用率有限。我们还使用Puppet以及自定义脚本来配置服务器。这已经奏效,但需要定制的、持续的调度支持。我们面临的关键问题是是否构建我们自己的调度算法(例如装箱)或采用不同的方法。显然,业界打算通过两条路径直接解决这个问题:依靠云提供商进行编排(Amazon Web Services、Google Cloud Platform 等)以及通过 Mesos 和 Kubernetes 等开源调度框架。
我们拥有超过五年技术基础设施的行业同行几乎一致采用开源调度框架来更好地支持他们的物理基础设施。这将为他们提供一个工具来执行从物理基础设施到云基础设施的桥接迁移。
现有基础设施较少的新公司正在直接迁移到云,并避免完全解决编排问题。唯一不采用这两种方法之一的公司是非常庞大和复杂的(比如谷歌或微软)或者对任何技术变革都过敏。
从这一分析来看,很明显,继续依赖 Clusto 和 Puppet 将是一项昂贵的投资,而且与行业的发展并不特别相符。
用户和价值链
该地图重点关注单个公司内的编排生态系统,重点关注从 2008 年到 2014 年左右,哪些内容保持不变,哪些内容没有变化。它特别关注三个用户:
- 产品工程师专注于配置新服务,然后在进行更改时部署该服务的新版本。他们完全专注于自己的服务,完全不知道编排层下面的任何内容(包括任何服务器)。
- 服务配置团队专注于配置新服务、为这些服务编排资源以及将流量路由到这些服务。该团队充当产品工程师和服务器运营团队之间的桥梁。
- 服务器运营团队专注于增加用于编排的服务器容量。他们与服务提供团队密切合作,与产品工程师没有联系。
值得承认的是,在实践中,这些是多个底层团队的人为聚合。例如,服务和服务器之间的路由流量通常由流量或服务网络团队处理。然而,这些遗漏是为了澄清与编排工具的演变相关的区别。