当您在传统搜索引擎中输入查询时,您会得到一个结果列表。它们是您问题的可能答案,您可以决定要信任哪些资源。另一方面,当您通过人工智能聊天机器人查询时,您会得到有限数量的答案(作为句子),这些答案在上下文中显得很有信心。
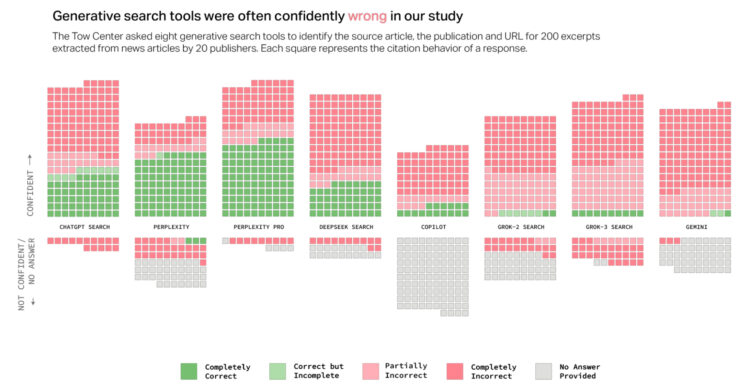
在《哥伦比亚新闻评论》中,Klaudia Jaźwińska 和 Aisvarya Chandrasekar 通过使用多个聊天机器人来引用文章来测试这种准确性和置信度:
总体而言,聊天机器人经常无法检索到正确的文章。总的来说,他们对超过 60% 的查询提供了错误的答案。在不同的平台上,不准确的程度各不相同,Perplexity 错误地回答了 37% 的查询,而 Grok 3 的错误率要高得多,错误地回答了 94% 的查询。
所以不太好。
我确信有人正在努力提高准确性,但我们必须发展自己的技能来区分真相和垃圾,就像我们处理过去的在线事物一样。展望未来,也许要留意年轻一代和老一代人,他们倾向于将网上的事物视为自动的真理。事情可能会变得危险。
标签:准确性、聊天机器人、引文、哥伦比亚新闻评论
原文: https://flowingdata.com/2025/03/17/testing-citation-skills-and-overconfidence-of-ai-chatbots/