由于我们仍处于使用基础模型构建应用程序的早期阶段,因此犯错误是很正常的。这是一个简短的说明,其中包含我从公共案例研究和我个人经验中看到的一些最常见陷阱的示例。
因为这些陷阱很常见,所以如果您曾经开发过任何人工智能产品,那么您以前可能已经见过它们。
1. 当不需要生成式人工智能时使用生成式人工智能
每当有新技术出现时,我都能听到各地高级工程师的集体感叹:“并非所有东西都是钉子。”生成式人工智能也不例外——它看似无限的能力只会加剧将生成式人工智能用于一切事物的趋势。
一个团队向我提出了使用生成式人工智能来优化能源消耗的想法。他们将一个家庭的能源密集型活动清单和每小时的电价输入法学硕士,然后要求其制定一个时间表以最大限度地降低能源成本。他们的实验表明,这可以帮助家庭减少 30% 的电费。免费的钱。为什么没有人想使用他们的应用程序?
我问:“这与在电价最便宜时简单地安排能源最密集的活动相比如何?比如说,晚上 10 点之后洗衣服、给车充电?”
他们说稍后会尝试并告诉我。他们没有跟进,但很快就放弃了这个应用程序。我怀疑这种贪婪的调度会非常有效。即使不是,还有其他比生成式人工智能更便宜、更可靠的优化解决方案,比如线性编程。
我已经一遍又一遍地看到这样的场景。一家大公司希望使用生成式人工智能来检测网络流量中的异常情况。另一个想要预测即将到来的客户呼叫量。医院想要检测病人是否营养不良(确实不推荐)。
只要您意识到您的目标不是解决问题而是测试解决方案,探索新方法来了解可能性通常是有益的。 “我们解决问题”和“我们使用生成人工智能”是两个截然不同的标题,不幸的是,很多人宁愿选择后者。
2. 将“糟糕的产品”与“糟糕的人工智能”混为一谈
另一方面,许多团队认为新一代人工智能是解决他们问题的有效解决方案,因为他们尝试过但用户讨厌它。然而,其他团队成功地将 gen AI 用于类似的用例。我只能调查其中两个团队。在这两种情况下,问题不在于人工智能,而在于产品。
许多人告诉我,他们的人工智能应用程序的技术方面很简单。困难的部分是用户体验(UX)。产品界面应该是什么样的?如何将产品无缝集成到用户工作流程中?如何融入“人在环”?
用户体验一直都充满挑战,但对于生成式人工智能来说更是如此。虽然我们知道生成式人工智能正在改变我们阅读、写作、学习、教学、工作、娱乐等的方式,但我们还不太清楚具体是如何改变的。未来的阅读/学习/工作会是什么样?
这里有一些简单的例子来说明用户的需求可能是违反直觉的,并且需要严格的用户研究。
-
我的朋友正在开发一个总结会议记录的应用程序。最初,她的团队专注于获得正确的摘要长度。用户更喜欢 3 句摘要还是 5 句摘要?
然而,事实证明他们的用户并不关心实际的摘要。他们只想从每次会议中获得针对他们的具体行动项目。
-
当LinkedIn开发用于技能适合度评估的聊天机器人时,他们发现用户不想要正确的答案。用户希望得到有用的答复。
例如,如果用户询问机器人他们是否适合某项工作,并且机器人回答:“你非常适合”,则此回答可能是正确的,但对用户没有多大帮助。用户希望获得有关差距是什么以及可以采取哪些措施来缩小差距的提示。
-
Intuit 构建了一个聊天机器人来帮助用户回答税务问题。最初,他们得到的反馈不冷不热——用户觉得这个机器人没什么用。经过调查,他们发现用户实际上讨厌打字。面对空白的聊天机器人,用户不知道机器人能做什么、要输入什么。
因此,对于每次交互,Intuit 都会添加一些建议问题供用户点击。这减少了用户使用机器人的摩擦,并逐渐建立了用户的信任。用户的反馈变得更加积极。
(Intuit 人工智能副总裁Nhung Ho在 Grace Hopper 小组讨论中分享。)
因为现在大家都用同样的模型,AI产品的AI组件都是相似的,差异化的是产品。
3. 开始太复杂
此陷阱的示例:
- 当直接 API 调用有效时,使用代理框架。
- 当简单的基于术语的检索解决方案(不需要矢量数据库)起作用时,请苦苦思索要使用什么矢量数据库。
- 提示有效时坚持微调。
- 使用语义缓存。
鉴于有这么多闪亮的新技术,人们很容易立即开始使用它们。然而,过早整合外部工具可能会导致两个问题:
- 抽象出关键细节,使系统难以理解和调试。
- 引入不必要的错误。
工具开发人员可能会犯错误。例如,在检查框架的代码库时,我经常在默认提示中发现拼写错误。如果您使用的框架在没有通知您的情况下更新了其提示,您的应用程序的行为可能会发生变化,而您可能不知道原因。
最终,抽象是好的。但抽象需要结合最佳实践并经过长时间的测试。由于我们仍处于人工智能工程的早期阶段,最佳实践仍在不断发展,因此在采用任何抽象时我们应该更加警惕。
4. 对早期成功的过度评价
-
LinkedIn用了1 个月的时间才达到了他们想要的 80% 的体验,又用了 4 个月的时间才超过了 95% 。最初的成功让他们严重低估了改进产品的挑战性,尤其是在幻觉方面。他们发现随后实现每 1% 的增长是多么困难,令人沮丧。
- 一家为电子商务开发人工智能销售助理的初创公司告诉我,从 0% 到 80% 需要花费 80% 到 90% 的时间。他们面临的挑战:
- 准确性/延迟权衡:更多的规划/自我纠正=更多的节点=更高的延迟
- 工具调用:代理很难区分相似的工具
- 系统提示中的语气请求(例如
"talk like a luxury brand concierge")很难被完全遵守 - 座席很难完全理解客户的意图
- 很难创建一组特定的单元测试,因为查询的组合基本上是无限的
感谢Jason Tjahjono分享此内容。
- 在 UltraChat 论文中, Ding 等人。 (2023)分享道,“从 0 到 60 的旅程很容易,而从 60 到 100 的进步则变得极具挑战性。”
这也许是任何构建人工智能产品的人很快就会学到的第一个痛苦教训之一。构建演示很容易,但构建产品却很难。除了幻觉、延迟、延迟/准确性权衡、工具使用、提示、测试等问题之外,团队还会遇到一些问题,例如:
- API 提供商的可靠性。一个团队告诉我,他们 10% 的 API 调用超时。或者产品的行为会因为底层模型的变化而变化。
- 合规性,例如围绕人工智能输出版权、数据访问/共享、用户隐私、检索/缓存系统的安全风险以及训练数据沿袭的模糊性。
- 安全,例如不良行为者滥用您的产品,您的产品会产生麻木不仁或冒犯性的反应。
在规划产品的里程碑和资源时,请务必考虑到这些潜在的障碍。一位朋友称之为“谨慎乐观”。然而,请记住,许多很酷的演示并不会带来精彩的产品。
5.放弃人工评估
为了自动评估人工智能应用程序,许多团队选择人工智能作为法官(也称为法学硕士作为法官)方法——使用人工智能模型来评估人工智能输出。一个常见的陷阱是放弃人类评估而完全依赖人工智能法官。
虽然人工智能法官非常有用,但它们并不是确定性的。法官的质量取决于底层法官的模型、法官的提示和用例。如果人工智能判断开发不当,它可能会对应用程序的性能做出误导性的评估。就像所有其他人工智能应用程序一样,人工智能法官必须随着时间的推移进行评估和迭代。
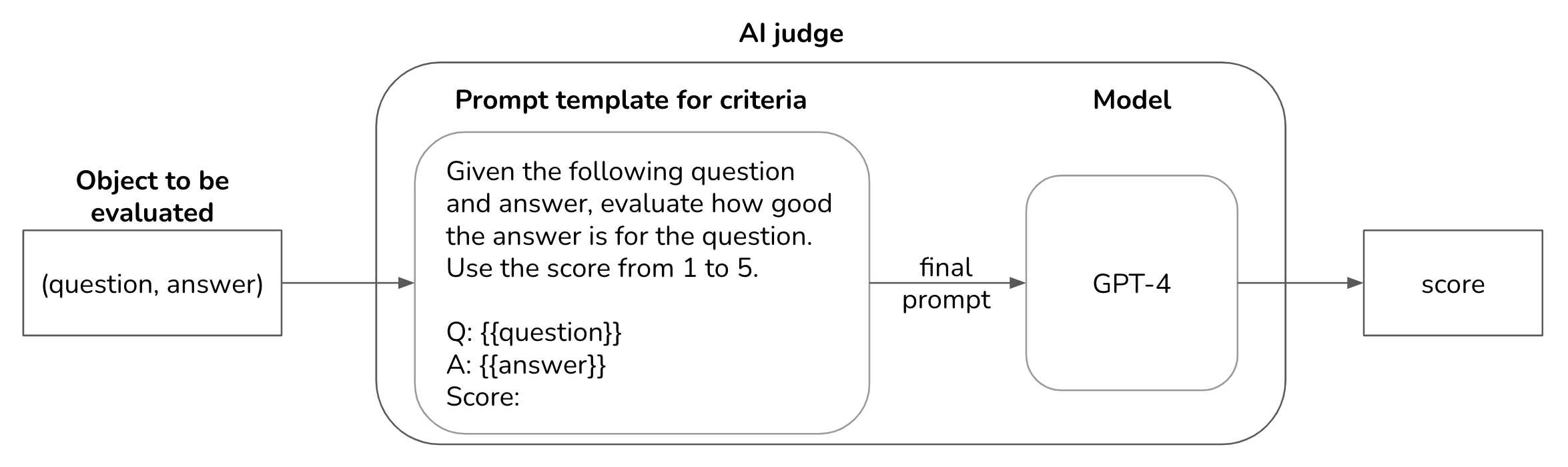
我见过的拥有最好产品的团队都有人工评估来补充他们的自动评估。每天,他们都会让人类专家评估其应用程序输出的子集,其中可能有 30 – 1000 个示例。
日常手动评估有 3 个目的:
- 将人类判断与人工智能判断相关联。如果人类评估者的分数正在下降,但人工智能评委的分数却在增加,您可能需要调查您的人工智能评委。
- 更好地了解用户如何使用您的应用程序,这可以为您提供改进应用程序的想法。
- 利用您对当前事件的了解,检测自动数据探索可能会错过的用户行为模式和变化。
人类评估的可靠性还取决于精心设计的注释指南。这些注释指南可以帮助改进模型的指令(如果人类很难遵循指令,模型也会如此)。如果您选择微调,也可以在以后重复使用它来创建微调数据。
在我参与过的每个项目中,仅仅盯着数据 15 分钟通常就能让我获得一些洞察力,从而避免我数小时的头痛。格雷格·布罗克曼 (Greg Brockman)在推特上写道:“在机器学习的所有活动中,手动检查数据可能具有最高的价值与声望比。 ”
6. 众包用例
这是我在早期企业疯狂采用生成式人工智能时看到的一个错误。由于无法制定关注哪些用例的策略,许多技术高管从整个公司众包了想法。 “我们雇用聪明的人。让他们告诉我们该怎么做。”然后他们尝试一一实施这些想法。
这就是我们最终获得一百万个文本到 SQL 模型、一百万个 Slack 机器人和十亿个代码插件的原因。
虽然听取所雇用的聪明人的意见确实是个好主意,但个人可能会偏向于立即影响其日常工作的问题,而不是可能带来最高投资回报的问题。如果没有考虑大局的总体策略,很容易陷入一系列小型、低影响的应用程序中,并得出“一代人工智能没有投资回报率”的错误结论。
概括
简而言之,以下是常见的人工智能工程陷阱:
-
当不需要生成式 AI 时使用生成式 AI
Gen AI 并不是解决所有问题的一刀切的解决方案。很多问题甚至不需要人工智能。 -
将“糟糕的产品”与“糟糕的人工智能”混淆
对于很多人工智能产品来说,人工智能是容易的部分,产品是困难的部分。 -
开始太复杂
虽然奇特的新框架和微调对于许多项目都很有用,但它们不应该是您的第一个行动方案。 -
对早期成功的过度评价
最初的成功可能会产生误导。从演示就绪到生产就绪可能比进行第一个演示需要更长的时间。 -
放弃人工评估
人工智能法官应该得到验证并与系统的人类评估相关联。 -
众包用例
制定宏观战略以最大化投资回报。
原文: https://huyenchip.com//2025/01/16/ai-engineering-pitfalls.html