2023 年是大型语言模型 (LLM) 取得突破的一年。我认为可以将这些称为 AI – 它们是人工智能学术领域最新且(当前)最有趣的发展,其历史可以追溯到 20 世纪 50 年代。
这是我尝试将亮点集中在一处的尝试!
- 大型语言模型
- 它们实际上很容易构建
- 您可以在自己的设备上运行法学硕士
- 爱好者可以构建自己的微调模型
- 我们还不知道如何构建 GPT-4
- 基于共鸣的开发
- LLM 非常聪明,但也非常非常愚蠢
- 轻信是最大的未解决问题
- 代码可能是最好的应用
- 这个领域的伦理仍然极其复杂
- 2023 年我的博客
大型语言模型
在过去的 24-36 个月里,我们人类发现,你可以使用一个巨大的文本语料库,通过一堆 GPU 运行它,并用它来创建一种令人着迷的新型软件。
LLM 可以做很多事情。他们可以回答问题、总结文档、从一种语言翻译成另一种语言、提取信息,甚至编写出令人惊讶的合格代码。
它们还可以帮助您在作业中作弊,生成无限量的虚假内容流并用于各种邪恶目的。
到目前为止,我认为它们是净积极的。我在个人层面上使用它们以各种不同的方式提高我的工作效率(并娱乐自己)。我认为学习如何有效使用它们的人可以显着提高他们的生活质量。
我很多人还没有被出售其价值!有些人认为它们的负面影响超过了正面影响,有些人认为它们都是空话,有些人甚至认为它们代表了对人类的生存威胁。
它们实际上很容易构建
今年我们了解到的关于法学硕士的最令人惊讶的事情是,它们实际上很容易建立。
直觉上,人们会期望如此强大的系统需要数百万行复杂的代码。相反,事实证明几百行 Python确实足以训练一个基本版本!
最重要的是训练数据。您需要大量数据才能使这些事情发挥作用,而训练数据的数量和质量似乎是最终模型的好坏的最重要因素。
如果您能够收集正确的数据,并支付 GPU 对其进行训练的费用,您就可以构建法学硕士。
一年前,唯一发布了普遍有用的 LLM 的组织是 OpenAI。我们新看到了由 Anthropic、Mistral、Google、Meta、EleutherAI、Stability AI、TII in Abu Dhabi ( Falcon )、Microsoft Research、xAI、Replit、Baidu 和其他许多公司制作的优于 GPT-3 类的模型组织。
培训成本(硬件和电力)仍然很大——最初为数百万美元,但似乎已经下降到数万美元。微软的 Phi-2 声称“在 96 个 A100 GPU 上使用了14 天”,按照当前的 Lambda 定价计算,其价格约为 35,000 美元。
因此,培训法学硕士仍然不是业余爱好者负担得起的事情,但它不再是超级富豪的专属领域。我喜欢将培养法学硕士的难度与建造一座吊桥的难度进行比较——这并不是微不足道的,但世界各地数百个国家已经弄清楚了如何做到这一点。
您可以在自己的设备上运行法学硕士
今年一月,我以为要过几年才能在自己的电脑上运行有用的法学硕士。 GPT-3 和 3.5 几乎是城里唯一的游戏,我认为即使模型权重可用,也需要 10,000 美元以上的服务器来运行它们。
然后在二月份,Meta 发布了 Llama。几周后的 3 月份,Georgi Gerganov 发布了让它在 MacBook 上运行的代码。
我写了一篇关于大型语言模型如何拥有稳定扩散时刻的文章,事后看来,这是一个非常好的决定!
这引发了一股创新旋风,7 月份 Meta发布了 Llama 2 (一个改进版本,其中最重要的是包含了商业使用许可),进一步加速了创新旋风。
如今,实际上有数千个法学硕士可以在各种不同的设备上本地运行。
我在笔记本电脑上运行了一堆。我在 iPhone 上运行 Mistral 7B(一款非常出色的型号)。您可以安装多个不同的应用程序来获得您自己的、本地的、完全私人的法学硕士。
您甚至可以使用 WebAssembly 和最新的 Chrome完全在浏览器中运行它们!
爱好者可以构建自己的微调模型
我之前说过,建立法学硕士对于业余爱好者来说仍然遥不可及。对于从头开始的训练来说可能是这样,但微调其中一个模型完全是另一回事。
现在有一个令人着迷的生态系统,人们在这些基础上训练自己的模型,发布这些模型,构建微调数据集并共享这些模型。
Hugging Face Open LLM 排行榜是跟踪这些情况的地方之一。我什至无法尝试数它们,任何计数都会在几个小时内过时。
任何时候最好的整体公开许可的法学硕士很少是基础模型:相反,它是最近发现微调数据的最佳组合的微调社区模型。
与封闭模型相比,这是开放模型的巨大优势:封闭的托管模型没有世界各地数以千计的研究人员和爱好者合作和竞争来改进它们。
我们还不知道如何构建 GPT-4
令人沮丧的是,尽管今年我们取得了巨大的进步,但我们尚未看到比 GPT-4 更好的替代模型。
OpenAI 在 3 月份发布了 GPT-4,不过后来我们发现我们在 2 月份抢先看到了它,当时微软将其用作新 Bing 的一部分。
这种情况很可能在未来几周内发生变化:谷歌的 Gemini Ultra 有着很大的宣传,但尚未可供我们试用。
Mistral 背后的团队也在努力击败 GPT-4,考虑到他们的第一个公开模型在 9 月份才推出,他们的记录已经非常强劲,并且从那时起他们已经发布了两项重大改进。
尽管如此,令我感到惊讶的是,到目前为止,还没有人能击败已经问世将近一年的 GPT-4。 OpenAI 显然有一些尚未分享的实质性技巧。
基于共鸣的开发
作为计算机科学家和软件工程师,LLMS令人恼火。
即使是公开许可的黑匣子仍然是世界上最复杂的黑匣子。我们仍然对它们能做什么、它们到底如何工作以及如何最好地控制它们知之甚少。
我习惯于让计算机完全按照我的指示进行编程。提示LLM绝对不是这样的!
最糟糕的部分是评估它们的挑战。
有很多基准,但没有基准可以告诉您,当您尝试完成给定任务时,LLM 是否真的“感觉”正确。
我发现我必须与法学硕士一起工作几周,才能对其优势和劣势有一个良好的直觉。这极大地限制了我对自己的评价!
对我来说,最令人沮丧的是个人的激励。
有时我会调整提示并将其中的一些单词大写,以强调我确实希望它输出有效的 MARKDOWN 或类似内容。把这些词大写有什么不同吗?我仍然没有一个好的方法来解决这个问题。
我们只剩下有效的基于共鸣的开发。一路下来都是气势。
我很高兴看到我们在 2024 年超越振动!
LLM 非常聪明,但也非常非常愚蠢
一方面,我们不断寻找法学硕士可以做的新事情,这是我们没有预料到的,也是训练模型的人也没有预料到的。这通常非常有趣!
但另一方面,有时为了让模型发挥作用而必须做的事情往往非常愚蠢。
ChatGPT 在 12 月是否会变得懒惰,因为它的隐藏系统提示包括当前日期,并且其训练数据显示人们在假期来临之前提供的答案不太有用?
诚实的答案是“也许”!没有人完全确定,但如果你给它一个不同的日期,它的答案可能会稍微更长一些。
有时它会省略部分代码并让您填写它们,但如果您告诉它您无法输入,因为您没有任何手指,它会为您生成完整的代码。
类似这样的例子还有很多。向其提供现金提示以获得更好的答案。告诉它你的职业生涯取决于它。给予它积极的强化。这一切都很愚蠢,但是很有效!
轻信是最大的未解决问题
我在去年九月创造了“即时注射”这个词。
15 个月后,我遗憾地告诉大家,我们仍然距离找到一个稳健、可靠的解决方案来解决这个问题还很遥远。
我已经写了很多关于这个的文章。
除了特定类别的安全漏洞之外,我开始将其视为更广泛的轻信问题。
语言模型很容易受骗。他们“相信”我们告诉他们的内容——训练数据中的内容,微调数据中的内容,然后提示中的内容。
为了成为对我们有用的工具,我们需要他们相信我们喂给他们的东西!
但事实证明,我们想要建造的很多东西都需要他们不轻信。
每个人都想要一个人工智能私人助理。如果你雇佣了一位现实生活中的私人助理,他相信任何人告诉他们的一切,你很快就会发现他们对你的生活产生积极影响的能力受到严重限制。
很多人对人工智能代理感到兴奋——这是一个令人恼火的模糊术语,似乎与“可以离开并代表你采取行动的人工智能系统”相一致。我们一整年都在谈论它们,但尽管有很多令人兴奋的原型,但我很少看到它们在生产中运行的例子。
我认为这是因为轻信。
我们能解决这个问题吗?老实说,我开始怀疑如果不实现AGI就无法完全解决轻信问题。因此,这些特工梦想可能还需要相当长的一段时间才能真正开始实现!
代码可能是最好的应用
在这一年里,越来越明显的是,编写代码是法学硕士最擅长的事情之一。
如果你考虑一下他们所做的事情,你就会发现这并不是什么大惊喜。 Python 和 JavaScript 等编程语言的语法规则比中文、西班牙语或英语的语法要简单得多。
但它们的效率仍然令我惊讶。
法学硕士的一大弱点是他们容易产生幻觉——想象与现实不符的事物。您可能会认为这对于代码来说是一个特别糟糕的问题 – 如果法学硕士幻想出一种不存在的方法,那么代码应该是无用的。
除了…您可以运行生成的代码来查看它是否正确。通过像 ChatGPT 代码解释器这样的模式,LLM 可以执行代码本身,处理错误消息,然后重写它并继续尝试,直到它起作用!
因此,与其他任何事情相比,代码生成的幻觉问题要小得多。如果我们有相当于代码解释器的东西来检查自然语言就好了!
作为软件工程师,我们应该如何看待这一点?
一方面,这感觉像是一种威胁:如果 ChatGPT 可以为你编写代码,谁还需要程序员呢?
另一方面,作为软件工程师,我们比其他人更能利用这一点。我们都遇到过奇怪的编码实习生——我们可以利用我们深厚的知识来促使他们比其他人更有效地解决编码问题。
{kind=link}
这个领域的伦理仍然极其复杂
去年 9 月,Andy Baio 和我制作了第一个关于 Stable Diffusion 背后的未经许可的训练数据的重要故事。
从那时起,几乎每个主要的法学硕士(以及大多数图像生成模型)也都接受了未经许可的数据的训练。
就在本周,《纽约时报》就这一问题对 OpenAI 和微软发起了具有里程碑意义的诉讼。 69 页的 PDF确实值得一读,尤其是前几页,它以一种非常容易理解的方式列出了问题。该文档的其余部分包括我在任何地方读过的一些关于法学硕士是什么、它们如何工作以及它们如何构建的最清晰的解释。
这里的法律论据很复杂。我不是律师,但我认为这个问题不会轻易做出决定。无论结果如何,我预计这个案例将对这项技术未来的发展产生深远的影响。
法律不是道德。当这些模型将以与这些人竞争的方式使用时,在未经他们许可的情况下根据人们的内容训练模型是否可以?
随着人工智能模型产生的结果质量逐年提高,这些问题变得更加紧迫。
这些模型对人类社会的影响已经是巨大的,尽管很难客观衡量。
人们肯定失去了工作——有趣的是,我在文案撰稿人、艺术家和译者身上看到过这种情况。
这里有很多不为人知的故事。我希望 2024 年能看到大量关于这一主题的专门新闻报道。
2023 年我的博客
这是我的博客在 2023 年的标签云(使用 Django SQL Dashboard生成):
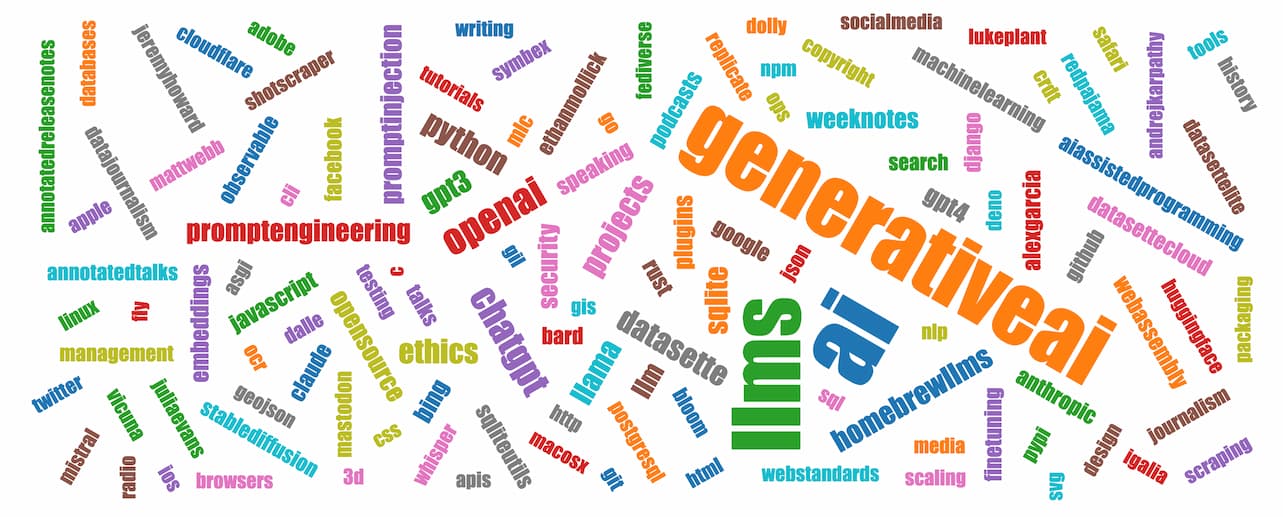
前五名: ai (342)、 generativeai (300)、 llms (287)、 openai (86)、 chatgpt (78)。
我已经写了很多关于这个东西的文章了!
我抓取了今年合理分析的屏幕截图,将其提供给 ChatGPT Vision,告诉它将数据提取到表中,然后让它混合条目标题(来自它编写的 SQL 查询)并用它生成此表。以下是我今年按流量排名最高的条目:
| 文章 | 访客 | 浏览量 |
|---|---|---|
| Bing:“除非你先伤害我,否则我不会伤害你” | 1.1M | 1.3M |
| 泄露的谷歌文件:“我们没有护城河,OpenAI 也没有” | 132k | 162k |
| 大型语言模型正处于稳定扩散时刻 | 121k | 15万 |
| 立即注射:可能发生的最坏情况是什么? | 79.8k | 95.9k |
| 嵌入:它们是什么以及它们为何重要 | 61.7k | 79.3k |
| 赶上法学硕士的奇怪世界 | 61.6k | 85.9k |
| llamafile 是在您自己的计算机上运行 LLM 的最佳新方法 | 52k | 66k |
| 通过视频、幻灯片和文字记录解释提示注射 | 51k | 61.9k |
| 人工智能增强的开发让我的项目更加雄心勃勃 | 49.6k | 60.1k |
| 了解 GPT 标记器 | 49.5k | 61.1k |
| 探索 GPT:穿着风衣的 ChatGPT? | 46.4k | 58.5k |
| 你能花 85,000 美元训练一个击败 ChatGPT 的模型并在浏览器中运行它吗? | 40.5k | 49.2k |
| 如何使用 GPT3、嵌入和数据集对文档实施问答 | 37.3k | 44.9k |
| 律师引用ChatGPT发明的假案例,法官不高兴 | 37.1k | 47.4k |
| 现在添加海象:DALL-E 3 中的提示工程 | 32.8k | 41.2k |
| Web LLM 完全在浏览器中运行 vicuna-7b 大型语言模型,令人印象深刻 | 32.5k | 38.2k |
| ChatGPT 无法访问互联网,尽管看起来确实可以 | 30.5k | 34.2k |
| 斯坦福羊驼,以及设备上大语言模型开发的加速 | 29.7k | 35.7k |
| 使用 LLM 和 Homebrew 在您自己的 Mac 上运行 Llama 2 | 27.9k | 33.6k |
| 中途5.1 | 26.7k | 33.4k |
| 将 ChatGPT 等语言模型视为“单词计算器” | 25k | 31.8k |
| 针对GPT-4V的多模态提示注入图像攻击 | 23.7k | 27.4k |
我还进行了一系列演讲和播客露面。我已经开始习惯性地将我的演讲变成带注释的演示文稿– 这是我 2023 年以来最好的演讲:
在播客中:
- 人工智能在变革理论中可以为您做什么
- 在通往 Citus Con 的道路上公开工作
- 法学硕士在变更日志上打破了互联网
- 在 Rooftop Ruby 上讨论大型语言模型
- 关于 Newsroom Robots 的 OpenAI 董事会情况的思考
原文: https://simonwillison.net/2023/Dec/31/ai-in-2023/#atom-everything