嵌入是一个非常巧妙的技巧,但常常包含在一堆令人生畏的术语中。
如果你能理解这些术语,他们就会解锁强大而令人兴奋的技术,这些技术可以应用于各种有趣的问题。
我在PyBay 2023上发表了有关嵌入的演讲。本文是该演讲的改进版本,即使不观看视频,它也应该是独立的。
如果您还不熟悉嵌入,我希望为您提供开始将它们应用于实际问题所需的一切。
在本文中:
- 38分钟视频版
- 什么是嵌入?
- 使用嵌入的相关内容
- 探索这些东西如何与 Word2Vec 一起工作
- 使用我的 LLM 工具计算嵌入
- 基于 Vibes 的搜索
- 使用 Symbex 嵌入代码
- 使用 CLIP 将文本和图像嵌入在一起
- 水龙头查找器:使用 CLIP 查找水龙头
- 聚类嵌入
- 通过主成分分析进行二维可视化
- 使用平均位置对句子进行评分
- 使用检索增强生成回答问题
- 问答
38分钟视频版
这是我在 PyBay 上发表的演讲视频:
由于麦克风问题,官方视频的音频质量不太好,但我通过 Adobe 的增强语音工具运行该音频,并将我自己的带有增强音频的视频上传到 YouTube。
什么是嵌入?
嵌入是一项与更广泛的大型语言模型领域相邻的技术 – ChatGPT 和 Bard and Claude 背后的技术。

嵌入基于一个技巧:获取一段内容(在本例中为博客条目)并将该内容转换为浮点数数组。
该数组的关键在于,无论内容有多长,它的长度始终相同。长度由您使用的嵌入模型定义 – 数组的长度可能是 300、1,000 或 1,536 个数字。
思考这个数字数组的最好方法是将其想象为一个非常奇怪的多维空间中的坐标。
很难可视化 1,536 维空间,因此这里是相同想法的 3D 可视化:
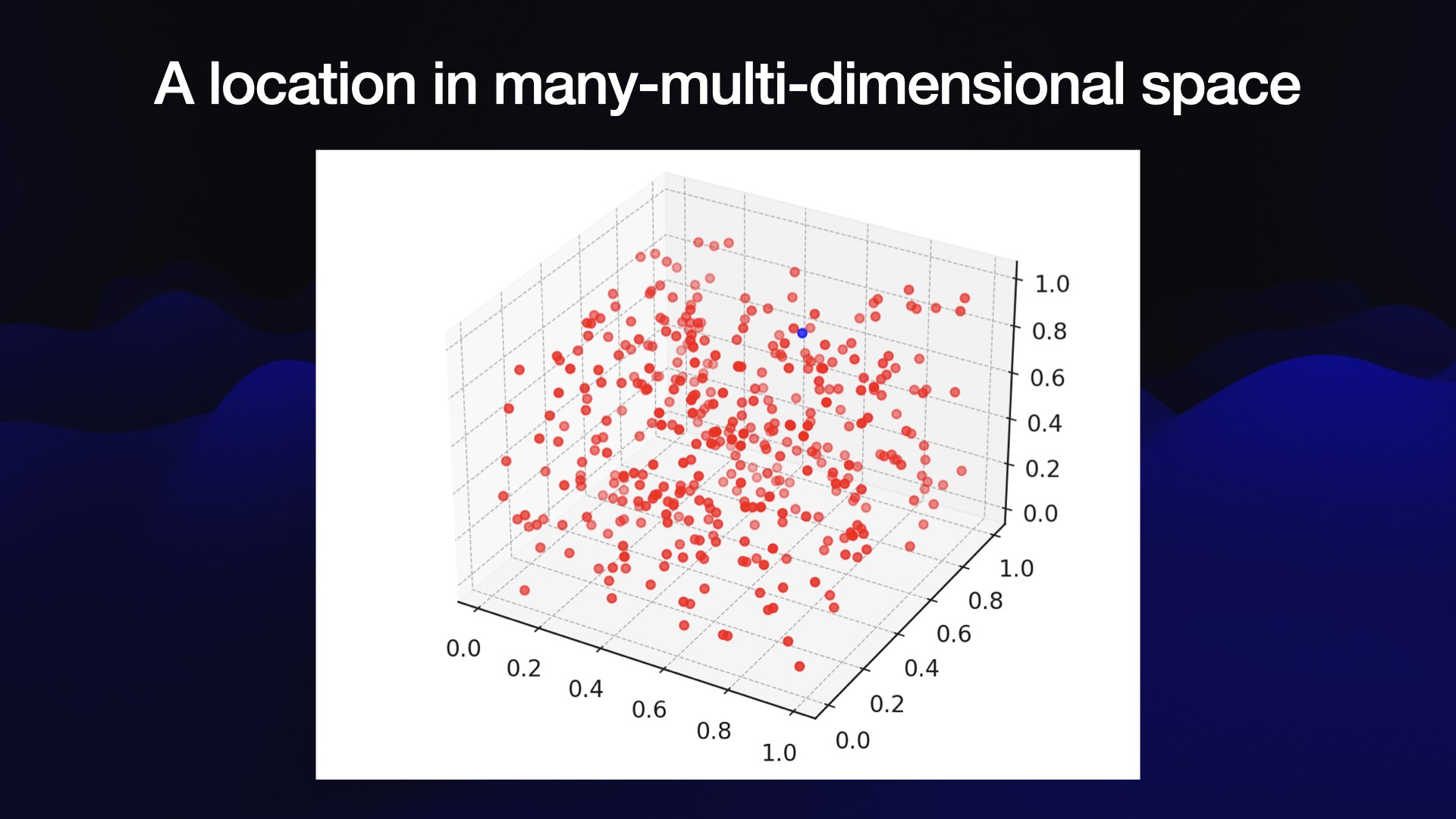
为什么要在这个空间放置内容?因为我们可以根据内容的位置(特别是附近的其他内容)了解该内容的有趣信息。
根据嵌入模型对世界的奇怪且大多难以理解的理解,空间内的位置代表了内容的语义含义。它可能会捕获已嵌入内容的颜色、形状、概念或各种其他特征。
没有人完全理解这些单独数字的含义,但我们知道它们的位置可用于查找有关内容的有用信息。
使用嵌入的相关内容
我使用嵌入解决的第一个问题是为我的 TIL 博客构建“相关内容”功能。我希望能够在每个页面的底部显示相关文章的列表。
我使用嵌入来完成此操作 – 在本例中,我使用了 OpenAI text-embedding-ada-002模型,该模型可通过其 API获得。
目前我的网站上有 472 篇文章。我计算了每篇文章的 1,536 维嵌入向量(浮点数数组),并将这些向量存储在我网站的 SQLite 数据库中。
现在,如果我想查找给定文章的相关文章,我可以计算该文章的嵌入向量与数据库中所有其他文章之间的余弦相似度,然后按距离返回 10 个最接近的匹配项。
本页底部有一个示例。使用 TG、sqlite-tg 和 datasette-sqlite-tg 在 SQLite 中进行地理空间 SQL 查询的前五篇相关文章是:
- SQLite 中的 Geopoly – 2023-01-04
- 使用 SpatiaLite 和 Datasette 查看 GeoPackage 数据– 2022-12-11
- 将 SQL 与 GDAL 结合使用– 2023-03-09
- 使用 SpatiaLite 进行 KNN 查询– 2021-05-16
- GUnion 将在 SpatiaLite 中组合几何图形– 2022-04-12
这是一个非常好的清单!
这是我用来计算这些余弦相似距离的Python 函数:
def余弦相似度( a , b ): dot_product = sum ( x * y for x , y in zip ( a , b )) 幅度_a = sum ( x * x for x in a ) ** 0.5 幅度_b =总和( x * x , b中的x ) ** 0.5 返回点积/ (幅度_a *幅度_b )
我的 TIL 站点在我的Datasette Python 框架上运行,该框架支持在 SQLite 数据库之上构建站点。我写了更多关于它如何在烘焙数据架构模式中工作的文章。
您可以浏览将计算的嵌入存储在tils/embeddings 的SQLite 表。
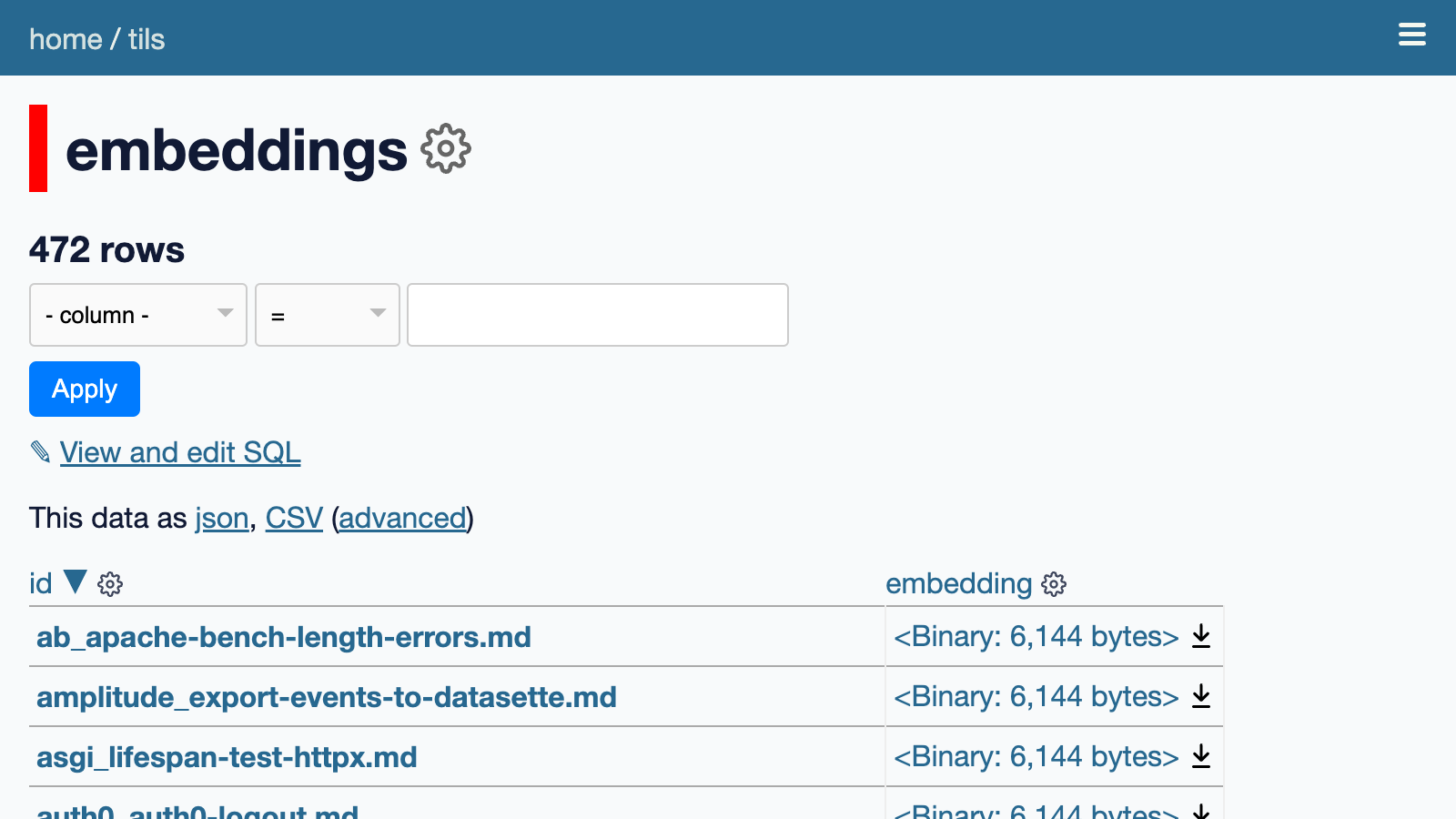
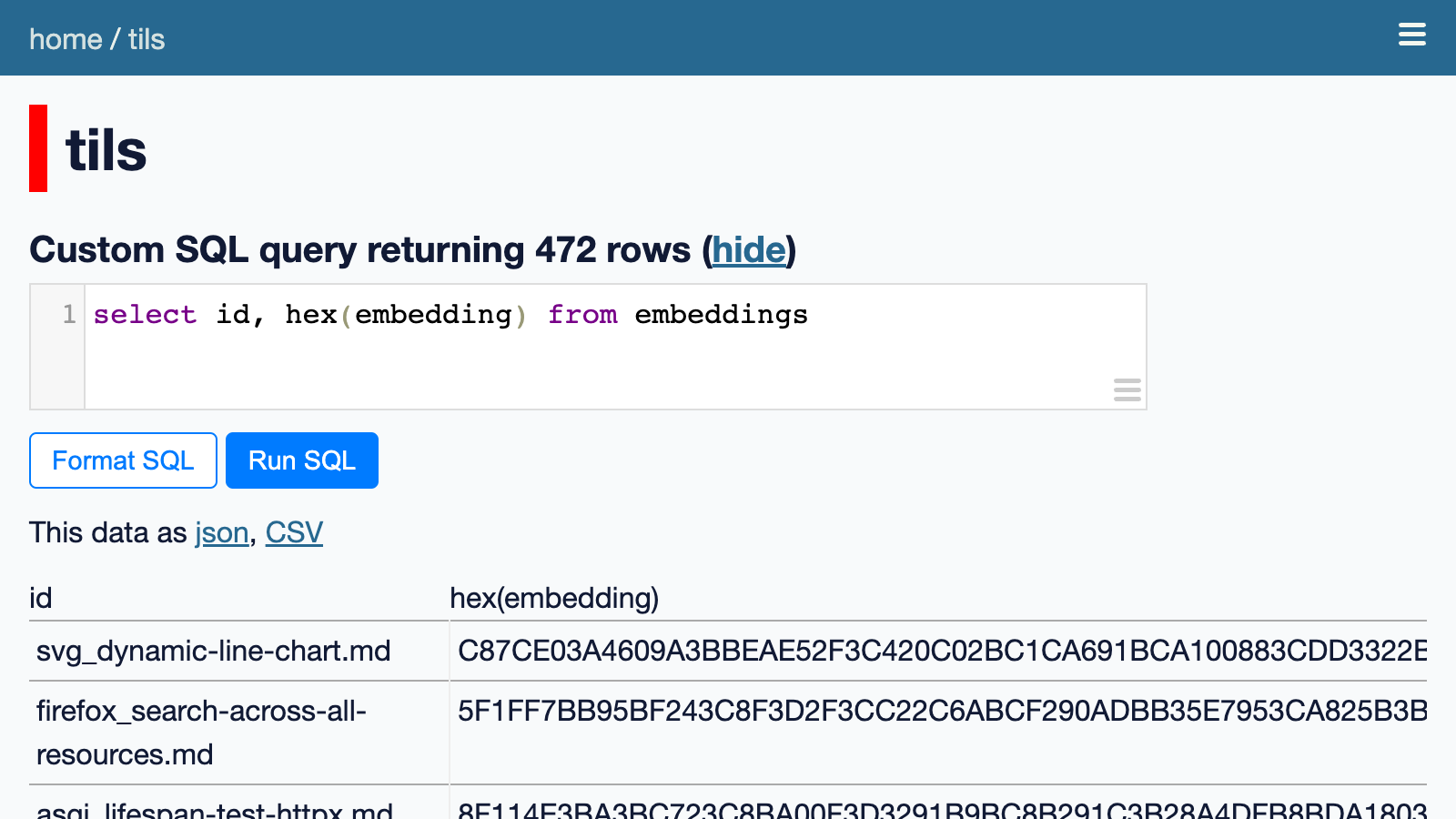
这些是二进制值。我们可以运行此 SQL 查询以十六进制形式查看它们:
从嵌入中选择id、十六进制(嵌入)
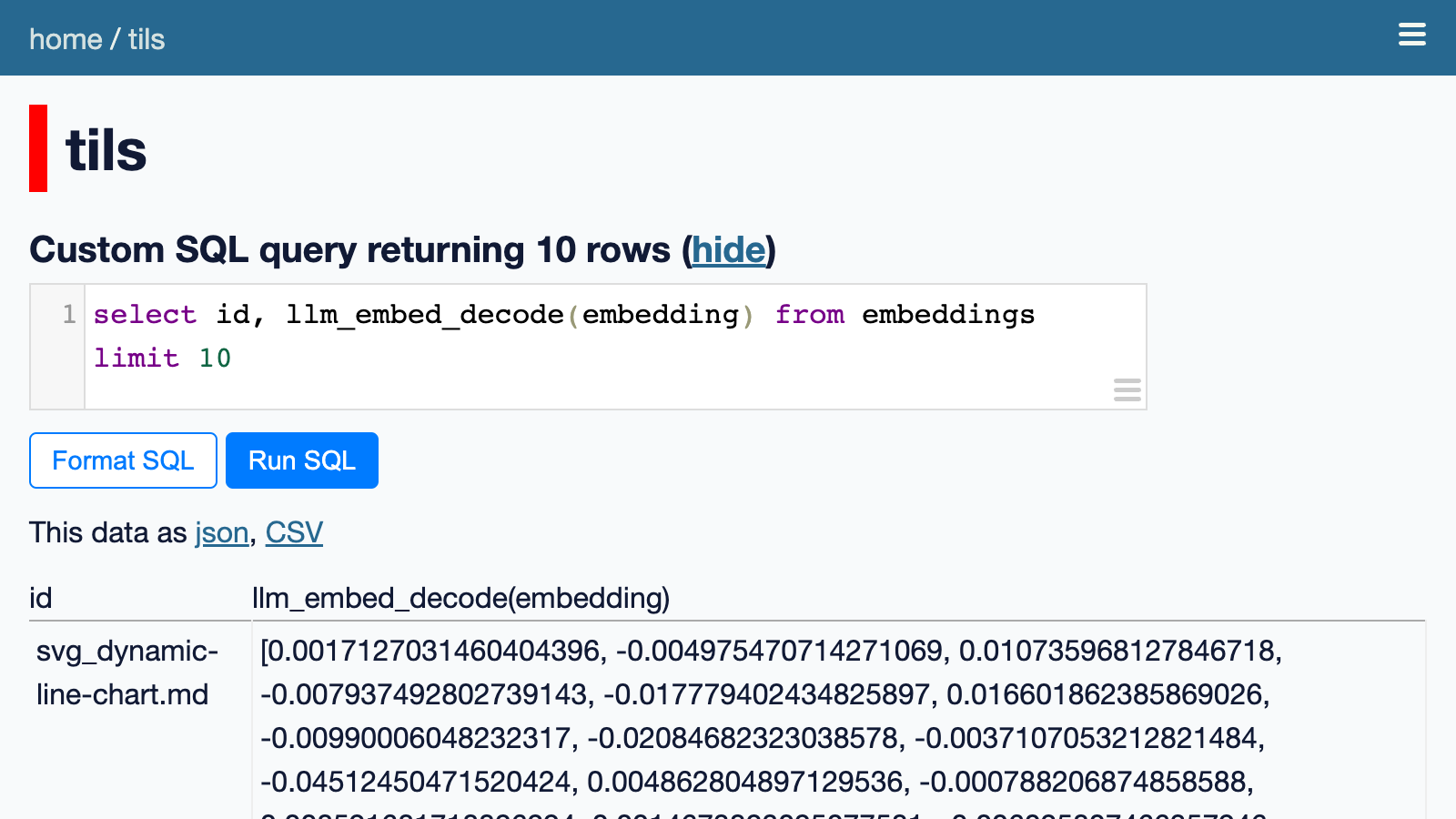
但这仍然不太可读。我们可以使用llm_embed_decode()自定义 SQL 函数将它们转换为 JSON 数组:
从嵌入限制10中选择id、llm_embed_decode(embedding)
在这里尝试一下。它显示每篇文章都附有 1,536 个浮点数的数组。
我们可以使用另一个自定义 SQL 函数llm_embed_cosine(vector1, vector2)来计算这些余弦距离并找到最相似的内容。
该 SQL 函数在我的datasette-llm-embed插件中定义。
以下查询返回与我的 SQLite TG 文章最相似的五篇文章:
选择 ID, llm_嵌入_余弦( 嵌入, ( 选择 嵌入 从 嵌入 在哪里 id = ' sqlite_sqlite-tg.md ' ) )作为分数 从 嵌入 订购依据 分数描述 限制5
执行该查询将返回以下结果:
| ID | 分数 |
|---|---|
| sqlite_sqlite-tg.md | 1.0 |
| sqlite_geopoly.md | 0.8817322855676049 |
| Spatialite_viewing-geopackage-data-with-spatialite-and-datasette.md | 0.8813094978399854 |
| gis_gdal-sql.md | 0.8799581261326747 |
| Spatialite_knn.md | 0.8692992294266506 |
正如预期的那样,该文章与其自身的相似度为 1.0。其他文章都与 SQLite 中的地理空间 SQL 查询相关。
该查询的执行时间大约为 400 毫秒。为了加快速度,我预先计算了每篇文章的前 10 个相似之处,并将它们存储在一个名为tils/similarities 的单独表中。
我编写了一个 Python 函数来从该表中查找相关文档,并从用于呈现文章页面的模板中调用它。
我的使用 openai-to-sqlite 和嵌入 TIL 存储和服务相关文档详细解释了这一切是如何工作的,包括如何使用 GitHub Actions 来获取新嵌入作为部署站点的构建脚本的一部分。
我在这个项目中使用了 OpenAI 嵌入 API。它非常便宜 – 对于我的 TIL 网站,我嵌入了大约 402,500 个代币,按 0.0001 美元/1,000 个代币计算,相当于 0.04 美元 – 只需 4 美分!
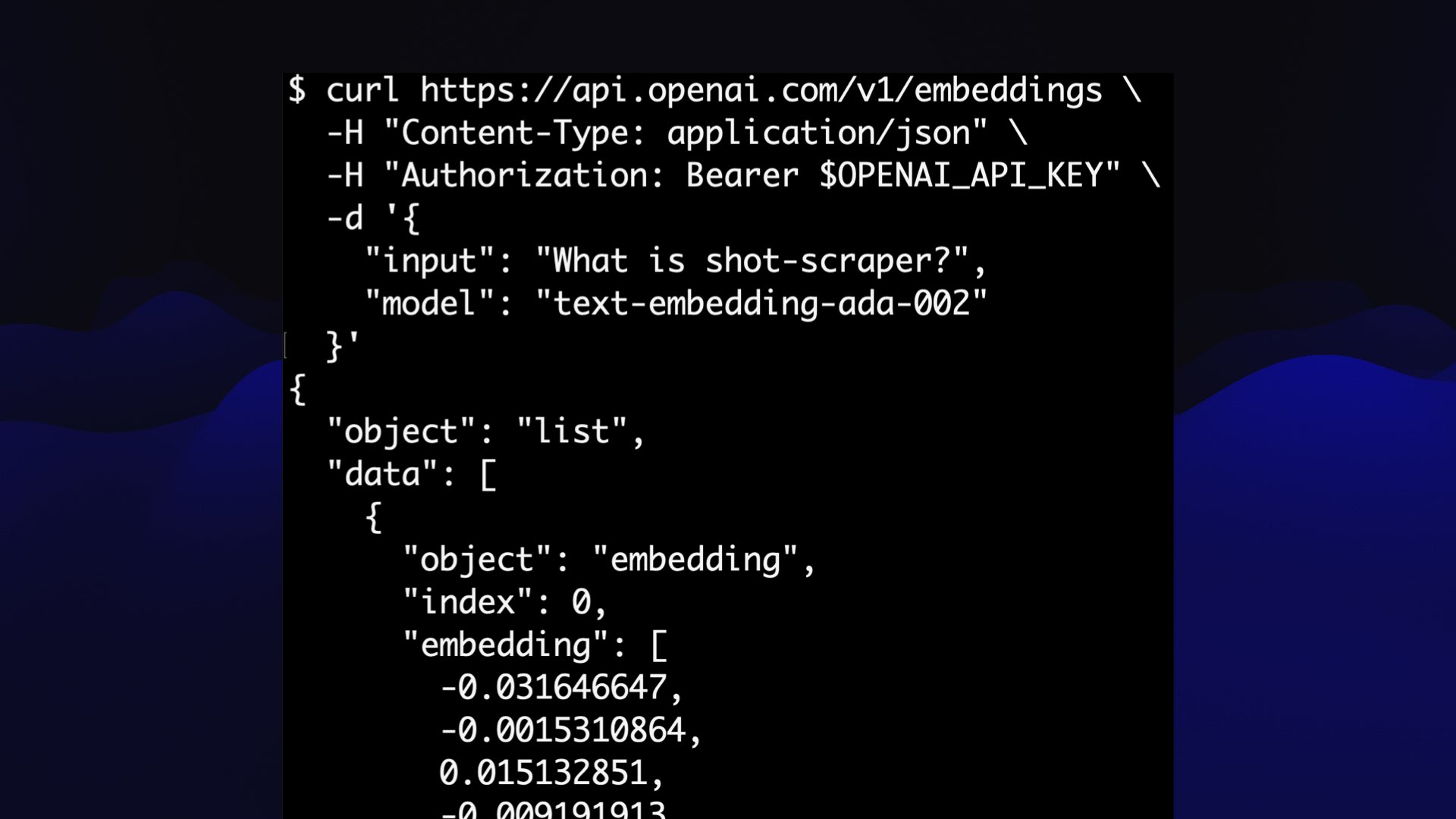
它真的很容易使用:您将一些文本与您的 API 密钥一起发布,它会返回浮点数的 JSON 数组。
但是……这是一个专有模型。几个月前,OpenAI 关闭了一些旧的嵌入模型,如果您存储了这些模型的大量嵌入,这将是一个问题,因为如果您希望能够嵌入,则需要根据支持的模型重新计算它们还有什么新的东西。
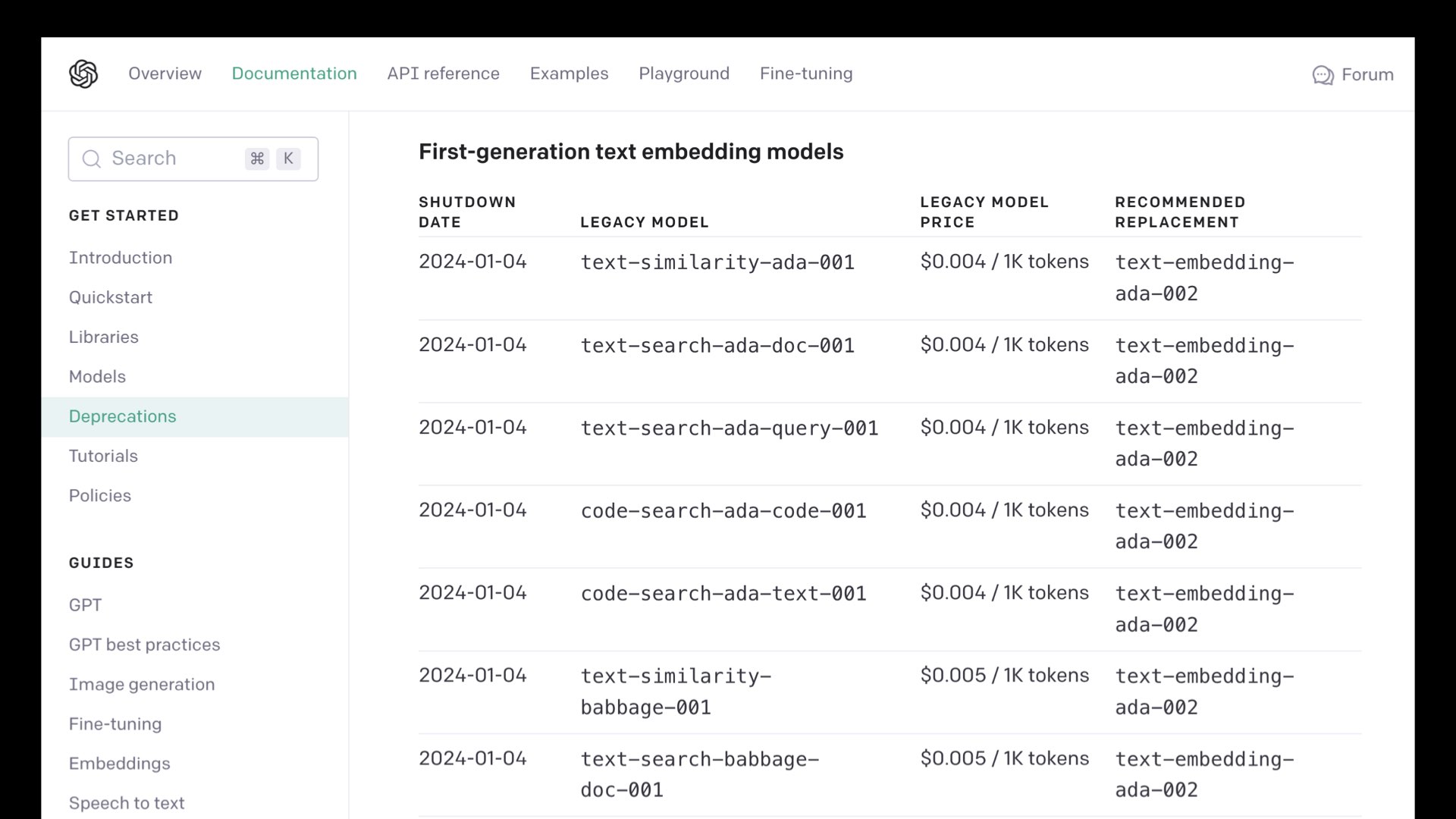
值得赞扬的是,OpenAI 确实承诺“承担用户使用这些新模型重新嵌入内容的财务成本”。 – 但这仍然是对依赖专有模型持谨慎态度的一个理由。
好消息是,有非常强大的开放许可模型,您可以在自己的硬件上运行它们,从而避免它们被关闭的任何风险。我们稍后会详细讨论这个问题。
探索这些东西如何与 Word2Vec 一起工作
Google Research 10 年前发表了一篇有影响力的论文,描述了他们创建的名为 Word2Vec 的早期嵌入模型。
这篇论文是Efficient Estimation of Word Representations in Vector Space ,发表日期为 2013 年 1 月 16 日。这篇论文引发了人们对嵌入的广泛兴趣。
Word2Vec 是一个模型,它将单个单词转换为包含 300 个数字的列表。该数字列表捕获了相关单词的含义。
通过演示可以最好地说明这一点。
Turbomaze.github.io/word2vecjson是Anthony Liu与 Word2Vec 语料库的 10,000 个单词子集组合而成的交互式工具。您可以查看此 JavaScript 文件以查看这 10,000 个单词的 JSON 及其关联的 300 长数字数组。
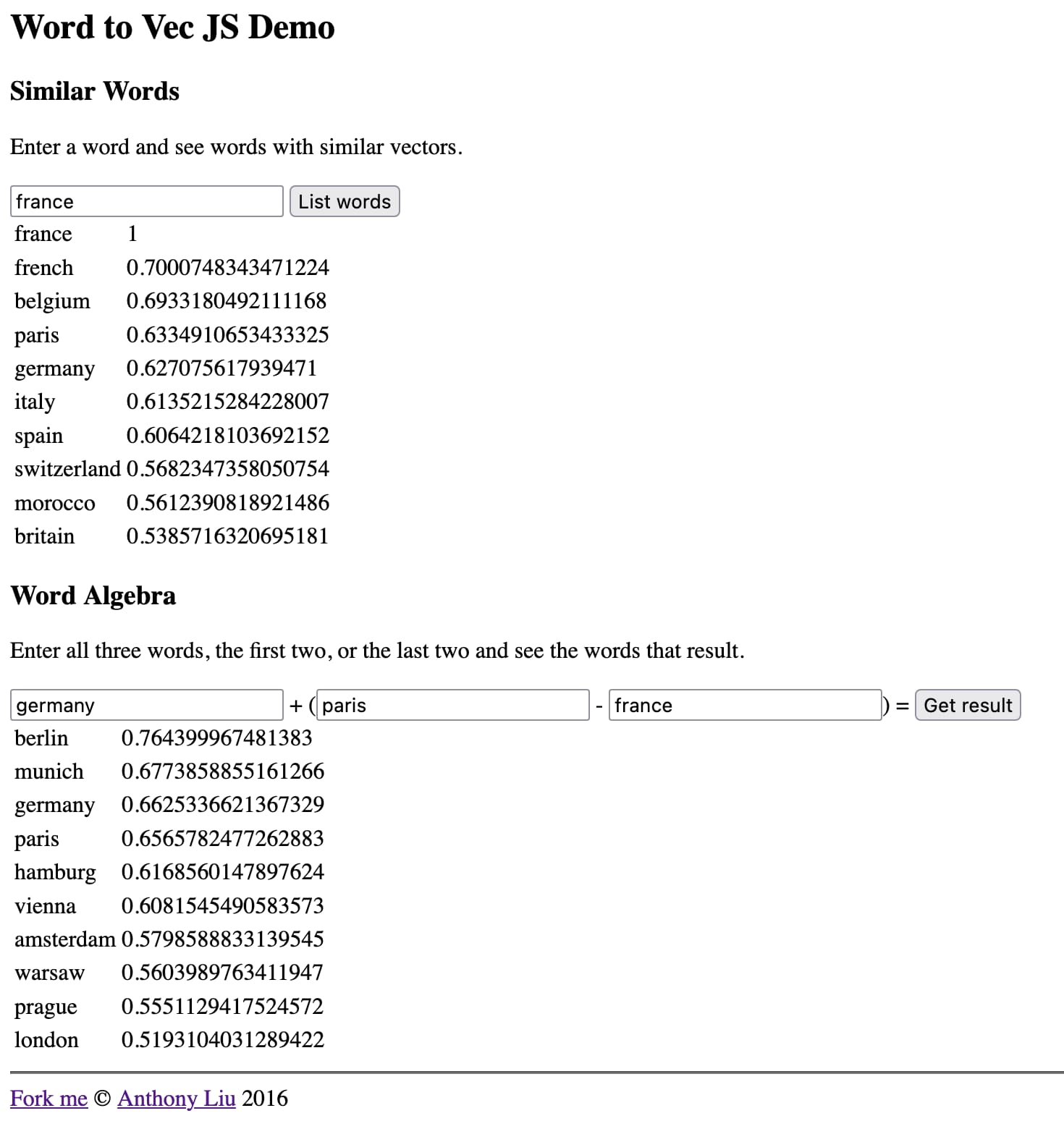
搜索单词以根据与其 Word2Vec 表示形式的余弦距离查找相似单词。例如,单词“france”会返回以下相关结果:
| 单词 | 相似 |
|---|---|
| 法国 | 1 |
| 法语 | 0.7000748343471224 |
| 比利时 | 0.6933180492111168 |
| 巴黎 | 0.6334910653433325 |
| 德国 | 0.627075617939471 |
| 意大利 | 0.6135215284228007 |
| 西班牙 | 0.6064218103692152 |
这是法国事物和欧洲地理的混合体。
您可以在这里做的一件非常有趣的事情是对这些向量执行算术运算。
获取“德国”的向量,添加“巴黎”并减去“法国”。得到的向量最接近“berlin”!
这个模型的某些部分已经捕捉到了民族和地理的概念,以至于你可以使用算术来探索关于世界的更多事实。
Word2Vec 使用 16 亿字的内容进行训练。我们今天使用的嵌入模型是在更大的数据集上进行训练的,并且可以更丰富地理解底层关系。
使用我的 LLM 工具计算嵌入
我一直在构建一个名为LLM的命令行实用程序和 Python 库。
您可以在这里阅读有关 LLM 的更多信息:
- llm、ttok 和 strip-tags — 用于与 ChatGPT 和其他 LLM 配合使用的 CLI 工具
- LLM CLI 工具现在通过插件支持自托管语言模型
- LLM 现在提供用于处理嵌入的工具
- 使用llm-clip构建图像搜索引擎,使用llm chat与模特聊天
LLM 是一种用于处理大型语言模型的工具。你可以像这样安装它:
pip安装llm
或者通过自制程序:
酿造安装llm
您可以将其用作与 LLM 交互的命令行工具,或用作Python 库。
它开箱即用,可以与 OpenAI API 配合使用。设置API 密钥,您可以运行如下命令:
LLM “宠物鹈鹕的十个有趣的名字”
真正有趣的地方是当你开始安装插件时。有些插件可以向其中添加全新的语言模型,包括直接在您自己的计算机上运行的模型。
几个月前,我扩展了 LLM以支持也可以运行嵌入模型的插件。
以下是如何使用 LLM 运行名为all-MiniLM-L6-v2 的模型:

首先,我们安装llm ,然后使用它来安装llm-sentence-transformers插件 – SentenceTransformers库的包装器。
pip安装llm llm 安装 llm-sentence-transformers
接下来我们需要注册all-MiniLM-L6-v2模型。这会将模型从 Hugging Face 下载到您的计算机:
llm 句子转换器注册 all-MiniLM-L6-v2
我们可以通过嵌入一个句子来测试它,如下所示:
llm 嵌入 -m 句子转换器/all-MiniLM-L6-v2 \ -c '你好世界'
这会输出一个 JSON 数组,其开头如下:
[-0.03447725251317024, 0.031023245304822922, 0.006734962109476328, 0.026108916848897934, -0.03936201333999634, ...
像这样的嵌入本身并不是很有趣 – 我们需要存储和比较它们才能开始获得有用的结果。
LLM 可以将嵌入存储在“集合”中 – SQLite 表。 embed-multi 命令可用于一次嵌入多条内容并将它们存储在一个集合中。
这就是下一个命令的作用:
llm 嵌入多自述文件 \ --模型句子-transformers/all-MiniLM-L6-v2 \ --files ~ / ' **/README.md ' --store
在这里,我们正在填充一个名为“自述文件”的集合。
--files选项采用两个参数:要搜索的目录和与文件名匹配的 glob 模式。在本例中,我正在我的主目录中递归搜索任何名为README.md的文件。
--store选项使 LLM 除了嵌入向量之外还将原始文本存储在 SQLite 表中。
该命令在我的计算机上运行大约需要 30 分钟,但它有效!我现在有一个名为readmes的集合,其中包含 16,796 行 – 它对应在我的主目录中找到的每个README.md文件。
基于 Vibes 的搜索
现在我们有了嵌入集合,我们可以使用llm 类似命令对其进行搜索:
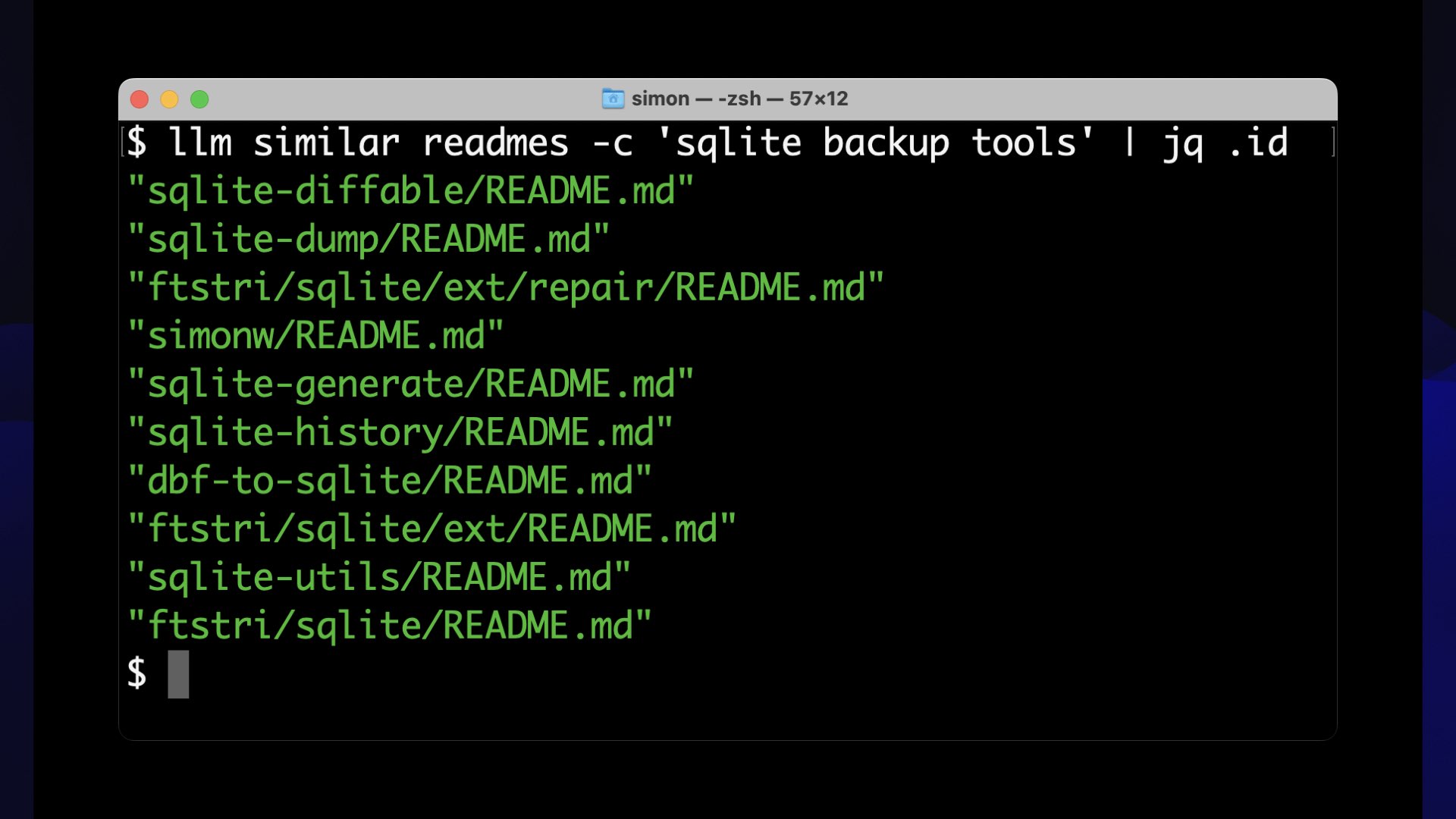
llm 类似自述文件 -c ' sqlite 备份工具' | jq.id
我们要求readmes集合中的项目类似于短语“sqlite backup tools”的嵌入向量。
该命令默认输出 JSON,其中包括 README 文件的全文,因为我们之前使用--store存储了它们。
通过jq .id管道传输结果会导致命令仅输出匹配行的 ID。
排名靠前的匹配结果是:
"sqlite-diffable/README.md" "sqlite-dump/README.md" "ftstri/salite/ext/repair/README.md" "simonw/README.md" "sqlite-generate/README.md" "sqlite-history/README.md" "dbf-to-sqlite/README.md" "ftstri/sqlite/ext/README.md" "sqlite-utils/README.md" "ftstri/sqlite/README.md'
这些都是很好的结果!这些自述文件中的每一个都描述了用于处理 SQLite 备份的工具或以某种方式与备份相关的项目。
有趣的是,不能保证术语“备份”直接出现在这些自述文件的文本中。内容在语义上与该短语相似,但可能与文本不完全匹配。
我们可以称之为语义搜索。我喜欢将其视为基于振动的搜索。
根据单词含义的这种奇怪的多维空间表示,这些自述文件的氛围与我们的搜索词相关。
这非常有用。如果您曾经为网站构建过搜索引擎,您就会知道精确匹配并不总能帮助人们找到他们正在寻找的内容。
我们可以使用这种语义搜索来为一大堆不同类型的内容构建更好的搜索引擎。
使用 Symbex 嵌入代码
我一直在构建的另一个工具称为Symbex 。它是一个用于探索 Python 代码库中符号的工具。
我最初构建它是为了帮助快速找到 Python 函数和类,并将它们输送到 LLM 中以帮助解释和重写它们。
然后我意识到我可以使用它来计算代码库中所有函数的嵌入,并使用这些嵌入来构建代码搜索引擎。
我添加了一个功能,可以使用llm embed-multi可以用作输入的相同输出格式输出表示找到的符号的 JSON 或 CSV。
以下是我如何使用新发布的名为gte-tiny的模型构建Datasette项目中所有函数的集合 – 只是一个 60MB 的文件!
llm 句子转换器注册 TaylorAI/gte-tiny cd数据集 symbex ' * ' ' *:* ' --nl | \ llm 嵌入多函数 - \ --模型句子-transformers/TaylorAI/gte-tiny \ --格式 nl \ - 店铺
symbex '*' '*:*' --nl查找当前目录中的所有函数 ( * ) 和类方法( *:*模式)并将它们输出为换行符分隔的 JSON。
llm embed-multi ... --format nl命令需要以换行符分隔的 JSON 作为输入,因此我们可以将symbex的输出直接通过管道传输到其中。
默认情况下将嵌入存储在默认的 LLM SQLite 数据库中。您可以添加--database /tmp/data.db来指定备用位置。
现在…我可以针对我的代码库运行基于振动的语义搜索!
我可以使用llm similar命令来执行此操作,但我也可以使用 Datasette 本身运行这些搜索。
这是一个 SQL 查询,使用之前的datasette-llm-embed插件:
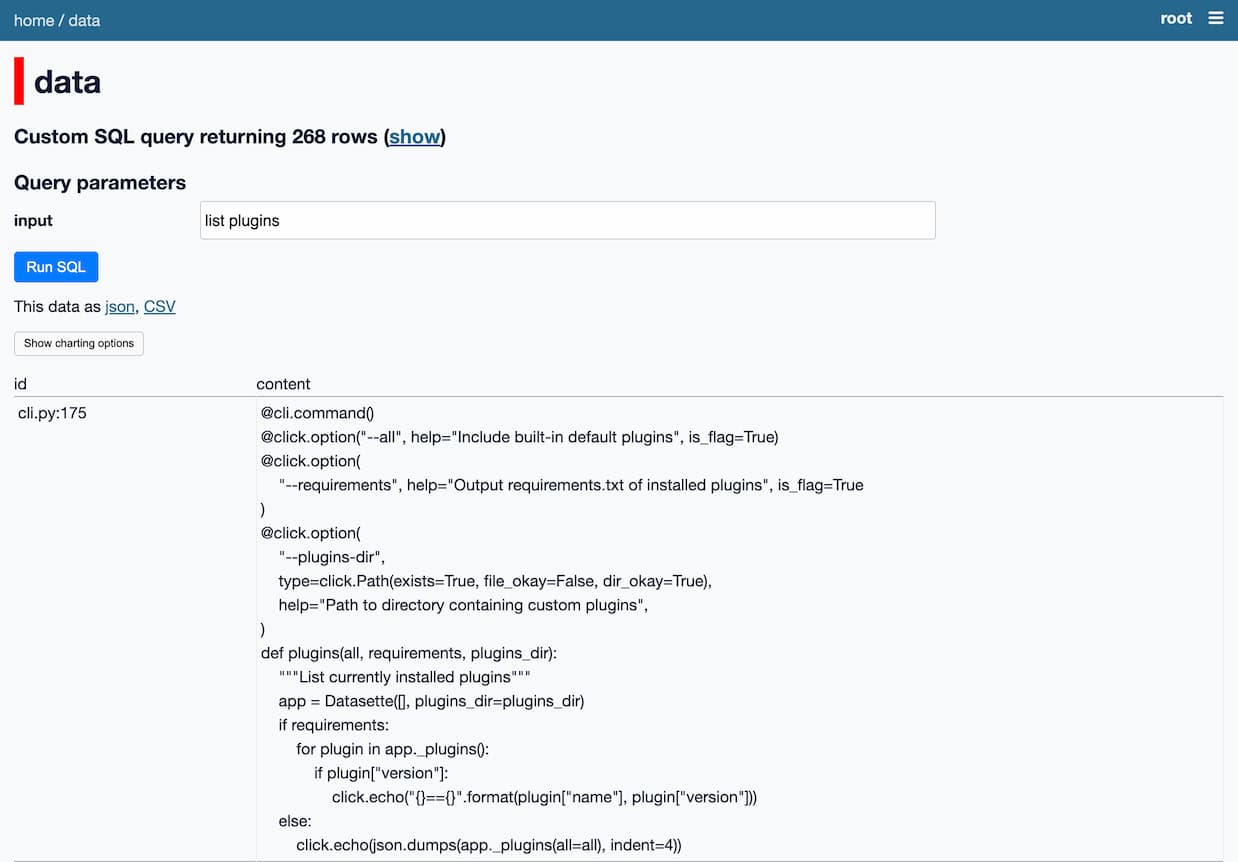
输入为( 选择 llm_嵌入( '句子变形金刚/TaylorAI/gte-tiny ' , :输入 )作为e ) 选择 ID, 内容 从 嵌入, 输入 在哪里 集合 ID = ( 从名称= ' functions '的集合中选择id ) 订购依据 llm_embed_cosine(嵌入,输入. e ) desc 限制5
:input参数会被 Datasette 自动转换为表单字段。
当我运行它时,我得到与列出插件概念相关的函数:
这里的关键思想是使用 SQLite 作为集成点 – 将多个工具组合在一起的基础。
我可以运行单独的工具,从代码库中提取函数,通过嵌入模型运行它们,将这些嵌入写入 SQLite,然后对结果运行查询。
现在,任何可以通过管道传输到工具中的内容都可以由该生态系统的其他组件嵌入和处理。
使用 CLIP 将文本和图像嵌入在一起
我目前最喜欢的嵌入模型是CLIP 。
CLIP 是 OpenAI 于 2021 年 1 月发布的一个令人着迷的模型,当时他们仍在公开地做大多数事情,它可以嵌入文本和图像。
至关重要的是,它将它们嵌入到同一个向量空间中。
如果嵌入字符串“dog”,您将获得 512 维空间中的位置(取决于您的 CLIP 配置)。
如果您嵌入狗的照片,您将在同一空间中获得一个位置……并且它与字符串“dog”的位置的距离很接近!
这意味着我们可以使用文本搜索相关图像,也可以使用图像搜索相关文本。
我构建了一个交互式演示来帮助解释其工作原理。该演示是一个 Observable 笔记本,直接在浏览器中运行 CLIP 模型。
这是一个相当重的页面 – 它必须加载 158MB 的资源(CLIP 文本模型为 64.6MB,图像模型为 87.6MB) – 但一旦加载,您可以使用它来嵌入图像,然后嵌入文本字符串并计算两者之间的距离。
我可以给它这张我拍的海滩照片:

然后输入不同的文本字符串来计算相似度得分,此处显示为百分比:
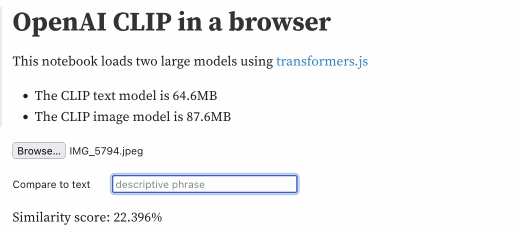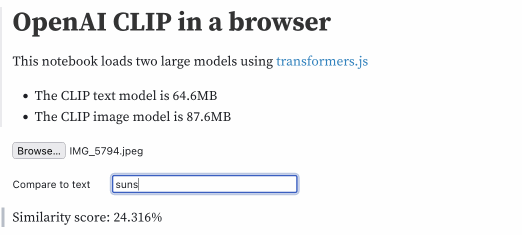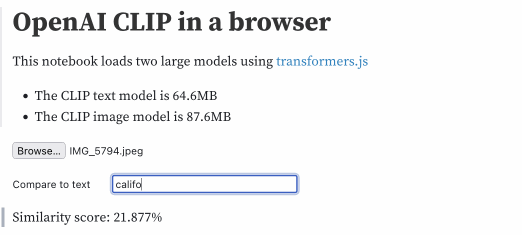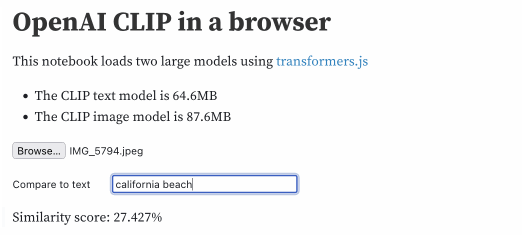
| 文本 | 分数 |
|---|---|
| 海滩 | 26.946% |
| 城市 | 19.839% |
| 阳光 | 24.146% |
| 阳光海滩 | 26.741% |
| 加利福尼亚州 | 25.686% |
| 加利福尼亚海滩 | 27.427% |
令人惊奇的是,我们可以在浏览器中运行的 JavaScript 中完成所有这些工作!
有一个明显的问题:能够拍摄任意照片并说“这与‘城市’一词有多相似?”实际上并没有那么有用。
诀窍是在此基础上构建额外的接口。我们再一次有能力构建基于振动的搜索引擎。
这是其中一个很好的例子。
水龙头查找器:使用 CLIP 查找水龙头
Drew Breunig使用 LLM 和我的llm-clip插件构建了一个水龙头搜索引擎。
他正在装修浴室,需要购买新水龙头。因此,他从一家水龙头供应公司收集了 20,000 张水龙头照片,并对所有这些照片运行 CLIP。
他使用结果构建了Faucet Finder – 一个自定义工具(使用 Datasette 部署),用于查找与其他水龙头相似的水龙头。
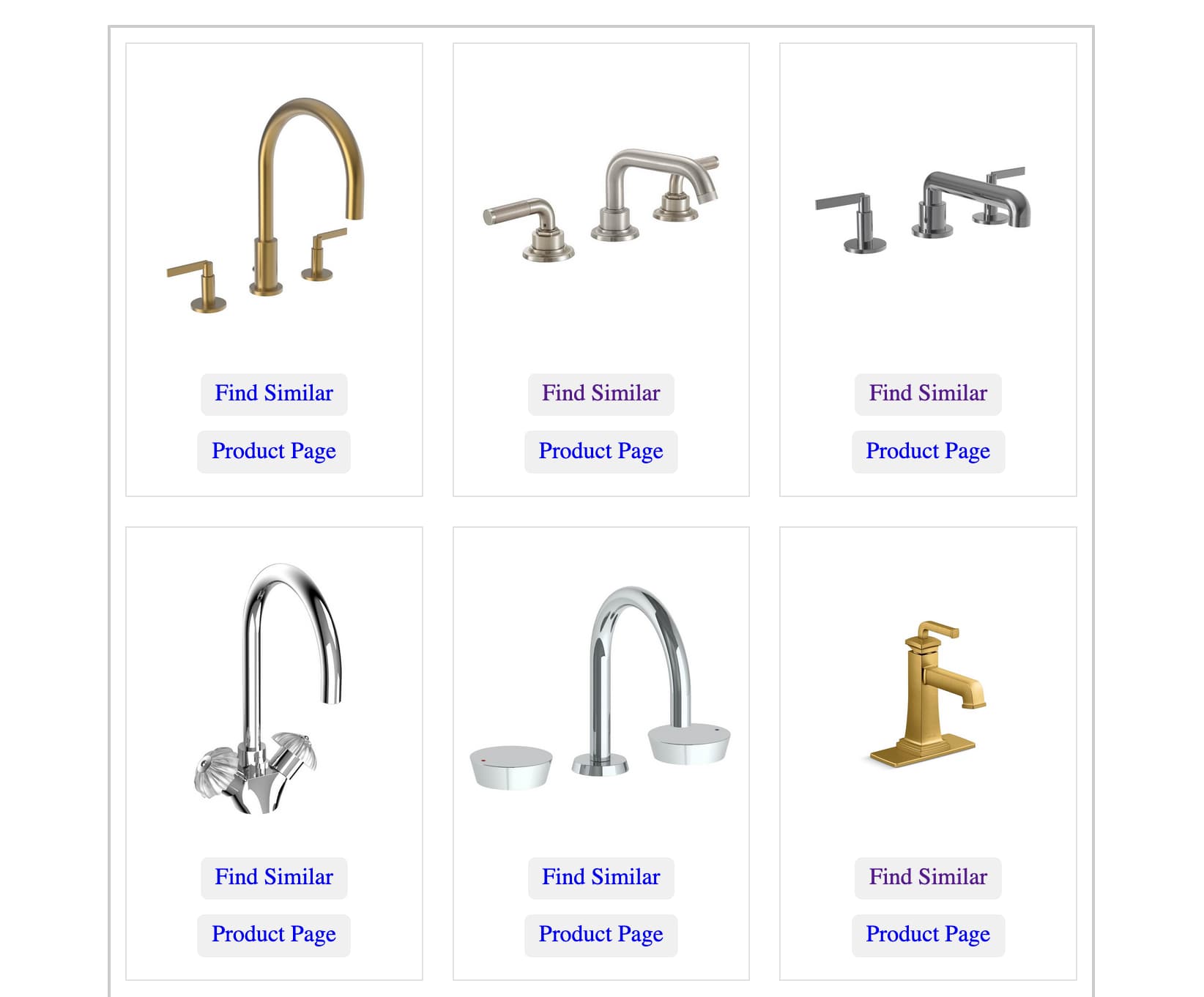
除此之外,这意味着您可以找到您喜欢的昂贵水龙头,然后寻找视觉上相似的更便宜的选择!
Drew 在Find Bathroom Faucets with Embeddings中详细介绍了他的项目。
Drew 的演示使用预先计算的嵌入来显示类似的结果,而无需在服务器上运行 CLIP 模型。
受此启发,我花了一些时间研究如何部署由我自己的Fly.io帐户托管的服务器端 CLIP 模型。
Drew 的 Datasette 实例包含此嵌入向量表,通过 Datasette API 公开。
我使用此 API部署了自己的实例来嵌入文本字符串,然后构建了一个 Observable 笔记本演示,该演示可以访问这两个 API 并组合结果。
observablehq.com/@simonw/search-for-faucets-with-clip-api
现在我可以搜索“金紫色”之类的内容并获取基于振动的水龙头结果:
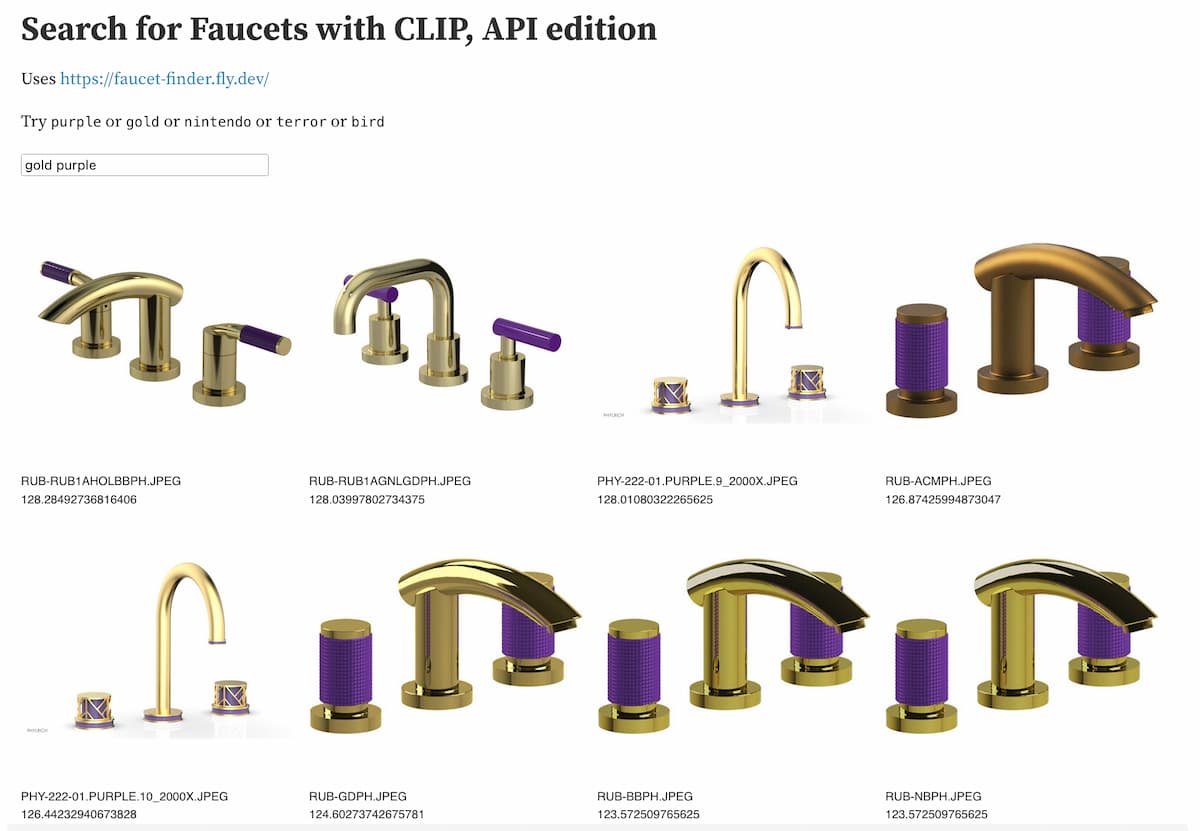
能够在几个小时内启动这种超特定的搜索引擎正是让我对将嵌入作为工具箱中的工具感到兴奋的技巧。
聚类嵌入
相关内容和基于语义/振动的搜索是嵌入的两个最常见的应用,但是您也可以用它们做很多其他巧妙的事情。
其中之一是聚类。
我为此构建了一个名为llm-cluster 的插件,它使用 scikit-learn 中的sklearn.cluster来实现此功能。
为了证明这一点,我使用paginate-json工具和 GitHub issues API 将simonw/llm存储库中所有问题的标题收集到名为llm-issues的集合中:
paginate-json ' https://api.github.com/repos/simonw/llm/issues?state=all&filter=all ' \ | jq ' [.[]| {id: .id, 标题: .title}] ' \ | llm 嵌入多 llm 问题 - \ - 店铺
现在我可以创建 10 个问题集群,如下所示:
llm安装llm集群 llm 集群 llm-问题 10
簇以 JSON 数组的形式输出,输出如下所示(已截断):
[ { “id” : “ 2 ” , “项目” :[ { “id” : “ 1650662628 ” , "content" : "初步设计" }, { “id” : “ 1650682379 ” , "content" : "记录 SQLite 的提示和响应" } ] }, { “id” : “ 4 ” , “项目” :[ { “id” : “ 1650760699 ” , "content" : " llm web 命令 - 启动 Web 服务器" }, { “id” : “ 1759659476 ” , "content" : " `llm models` 命令" }, { “id” : “ 1784156919 ” , "content" : " `llm.get_model(alias)` 帮助器" } ] }, { “id” : “ 7 ” , “项目” :[ { “id” : “ 1650765575 ” , "content" : " --code 输出代码模式" }, { “id” : “ 1659086298 ” , "content" : "接受来自 --stdin 的提示" }, { “id” : “ 1714651657 ” , "content" : "接受来自标准的输入" } ] } ]
这些看起来确实相关,但我们可以做得更好。 llm cluster命令有一个--summary选项,该选项使其通过 LLM 传递生成的集群文本,并使用它为每个集群生成描述性名称:
llm 集群 llm-issues 10 --summary
这会返回诸如“日志管理和交互式提示跟踪”和“持续对话机制和管理”之类的名称。有关更多详细信息,请参阅自述文件。
通过主成分分析进行二维可视化
大规模多维空间的问题在于它很难可视化。
我们可以使用一种称为主成分分析的技术将数据的维度减少到更易于管理的大小 – 事实证明,较低的维度可以继续捕获有关内容的有用语义。
Matt Webb使用 OpenAI 嵌入模型生成嵌入,用于描述 BBC 的 In Our Time 播客的每一集。他使用这些来查找相关剧集,同时还针对它们运行 PCA 以创建交互式 2D 可视化。
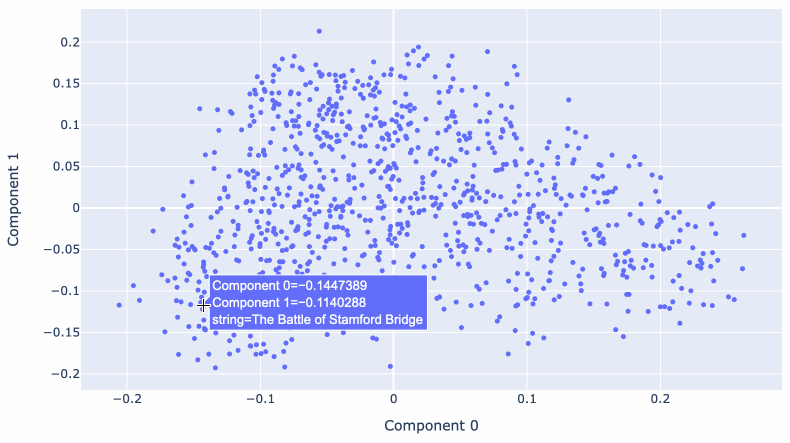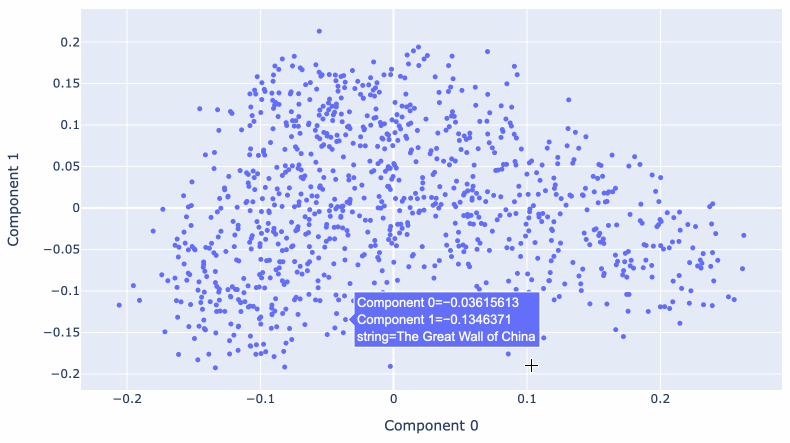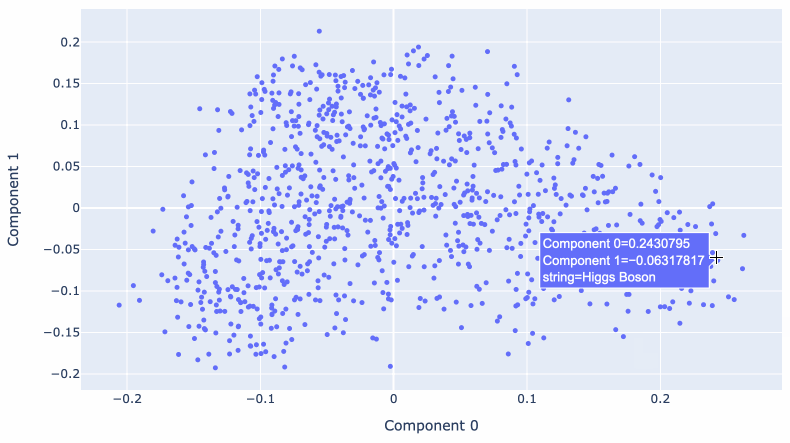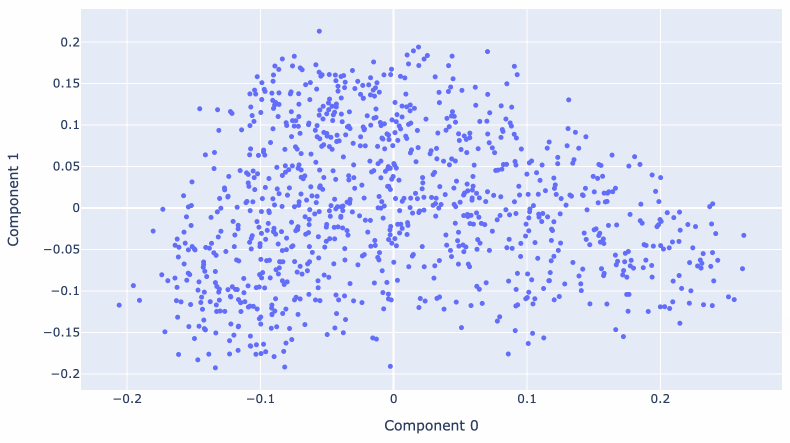
将 1,536 维减少到只有 2 维仍然可以产生一种有意义的数据探索方式!有关历史战争的剧集彼此相邻,其他地方则有一系列有关现代科学发现的剧集。
Matt 在浏览杜威十进制代码的 BBC In Our Time 档案中对此进行了更多介绍。
使用平均位置对句子进行评分
嵌入的另一个技巧是使用它们进行分类。
首先计算以某种方式分类的一组嵌入的平均位置,然后将新内容的嵌入与这些位置进行比较,以将其分配到一个类别。
Amelia Wattenberger 在“利用嵌入发挥创意”中展示了一个很好的例子。
她希望通过鼓励具体和抽象句子的混合来帮助人们提高写作水平。但是如何判断文本句子是具体的还是抽象的呢?
她的技巧是生成两种类型句子的样本,计算它们的平均位置,然后根据它们与新定义的频谱两端的接近程度对新句子进行评分。

该分数甚至可以转换为松散地表示给定句子的抽象或具体程度的颜色!
这是一个非常简洁的演示,展示了您可以在这项技术的基础上开始构建的创意界面。
使用检索增强生成回答问题
我将以最初让我对嵌入感到兴奋的想法作为结束语。
每个尝试 ChatGPT 的人最终都会问同样的问题:我如何使用这个版本来回答基于我自己的私人笔记或我公司拥有的内部文档的问题?
人们认为答案是在该内容的基础上训练自定义模型,这可能会花费巨大的代价。
事实证明这实际上没有必要。您可以使用现成的大型语言模型模型(托管模型或本地运行的模型)和一种称为检索增强生成(RAG)的技巧。
关键思想是:用户提出问题。您在私人文档中搜索与问题相关的内容,然后将该内容的摘录与原始问题一起粘贴到 LLM 中(遵守其大小限制,通常在 3,000 到 6,000 字之间)。
然后,法学硕士可以根据您提供的附加内容回答问题。
这个廉价的伎俩却非常有效。获得这个工作的基本版本是微不足道的 – 挑战在于考虑到用户可能会问的无数问题,使其尽可能好地工作。
RAG 的关键问题是找出最好的内容摘录,以包含在 LLM 的提示中。
由嵌入提供支持的“基于振动”的语义搜索正是您收集潜在相关内容以帮助回答用户问题所需的东西。
我根据我的博客内容构建了一个版本,详细描述见使用 E5-large-v2 嵌入我的博客中的段落。
为此,我使用了名为E5-large-v2的模型。这是一个根据具体用例进行训练的模型。
查找与问题相关的内容的一个挑战是用户的问题 – “什么是 shot-scraper?” – 不保证被认为在语义上与回答该问题的内容相似。问题和断言具有不同的语法。
E5-large-v2 通过支持两种类型的内容来解决这个问题。您可以在同一空间中嵌入短语(事实句子)和查询(问题),类似于 CLIP 支持图像和文本的方式。
我从博客中嵌入了 19,000 个文本段落作为短语,现在我可以嵌入一个问题作为查询,并使用它来查找最有可能回答该问题的段落。
结果是 RAG 作为单行 Bash 脚本实现:
llm 类似博客段落-c “查询: $1 ” \ | jq ' .内容 | sub("段落:";"") ' -r \ | llm -m mlc-聊天-Llama-2-7b-聊天-hf-q4f16_1 \ " $1 " -s '你以一个段落的形式回答问题'
此示例使用在我的笔记本电脑上运行的 Llama 2 Chat 7B(带有llm-mlc插件),因此我能够使用在我的笔记本电脑上运行的代码完全离线回答问题。
运行这个:
./blog-answer.sh '什么是 shot-scraper? '
输出这个:
Shot-scraper 是一个包装 Playwright 的 Python 实用程序,提供命令行界面和 YAML 驱动的配置流程,用于自动执行网页屏幕截图并使用 JavaScript 从中抓取数据的过程。它可用于拍摄一次性屏幕截图,或通过在 YAML 文件中定义它们以可重复的方式拍摄多个屏幕截图。此外,它还可用于在页面上执行 JavaScript 并返回结果值。
这是对我的镜头抓取工具的一个很好的描述。我检查过,没有一个输出与我之前在博客上发布的内容完全匹配。
问答
我的演讲以问答环节结束。以下是总结的问题和答案。
-
LangChain 如何融入其中?
LangChain是一个流行的框架,用于在 LLM 之上实现功能。它涵盖了很多内容——我对 LangChain 的唯一问题是你必须投入大量的工作来理解它是如何工作的以及它能为你做什么。检索增强生成是LangChain的关键特性之一,所以如果你投入精力,我今天向您展示的很多东西都可以构建在LangChain之上。
我的理念与 LangChain 不同,我专注于构建一套可以协同工作的小工具,而不是一次性解决所有问题的单一框架。
-
您是否尝试过余弦相似度以外的距离函数?
我没有。余弦相似度是其他人似乎都在使用的默认函数,我还没有花任何时间探索其他选项。
实际上,我让 ChatGPT 跨 Python 和 JavaScript 编写了所有不同版本的余弦相似度!
RAG 的一个令人着迷的地方是它有很多不同的旋钮可供您调整。你可以尝试不同的距离函数、不同的嵌入模型、不同的提示策略和不同的法学硕士。这里有很大的实验空间。
-
如果你有 10 亿个对象,你需要调整什么?
我今天展示的演示都是小规模的 – 最多大约 20,000 个嵌入。它足够小,您可以对所有内容运行强力余弦相似函数,并在合理的时间内返回结果。
如果您要处理更多数据,有越来越多的选项可以提供帮助。
许多初创公司正在推出新的“向量数据库”——这些数据库实际上是定制的,可以尽快回答针对向量的最近邻查询。
我不相信您需要一个全新的数据库:我更兴奋的是向现有数据库添加自定义索引。例如,SQLite 有sqlite-vss ,PostgreSQL 有pgvector 。
我还使用 Facebook 的FAISS库做了一些成功的实验,包括构建一个使用它的 Datasette 插件,称为datasette-faiss 。
-
您很高兴看到嵌入模型的哪些改进?
我对多模式模型感到非常兴奋。 CLIP is a great example, but I’ve also been experimenting with Facebook’s ImageBind , which “learns a joint embedding across six different modalities – images, text, audio, depth, thermal, and IMU data.” It looks like we can go a lot further than just images and text!
I also like the trend of these models getting smaller. I demonstrated a new model, gtr-tiny, earlier which is just 60MB. Being able to run these things on constrained devices, or in the browser, is really exciting to me.
原文: http://simonwillison.net/2023/Oct/23/embeddings/#atom-everything