RedPajama是“一个创建领先的开源模型的项目,从复制超过 1.2 万亿个令牌的 LLaMA 训练数据集开始”。这是 Together、Ontocord.ai、ETH DS3Lab、Stanford CRFM、Hazy Research 和 MILA Québec AI Institute 之间的合作。
他们刚刚发布了他们的第一个版本: RedPajama-Data-1T ,这是一个 1.2 万亿令牌数据集,以原始 LLaMA 论文中描述的训练数据为模型。
完整的数据集是 2.67TB,所以我决定不尝试下载整个数据集!到目前为止,这是我已经弄明白的。
如何下载
数据分为 2,084 个不同的文件。这些列在此处的纯文本文件中:
https://data.together.xyz/redpajama-data-1T/v1.0.0/urls.txt
数据集卡建议您可以像这样下载它们 – 假设您有 2.67TB 的磁盘空间和带宽可用:
wget -i https://data.together.xyz/redpajama-data-1T/v1.0.0/urls.txt
我几次提示 GPT-4 编写一个快速的 Python 脚本来对该文件中的每个 URL 运行HEAD请求,以便收集Content-Length并计算数据的总大小。我的脚本在这篇文章的底部。
然后我将大小数据处理成适合加载到Datasette Lite中的格式。
探索尺寸数据
这是一个指向 Datasette Lite 页面的链接,该页面显示了所有 2,084 个文件,按大小和一些有用的方面排序。
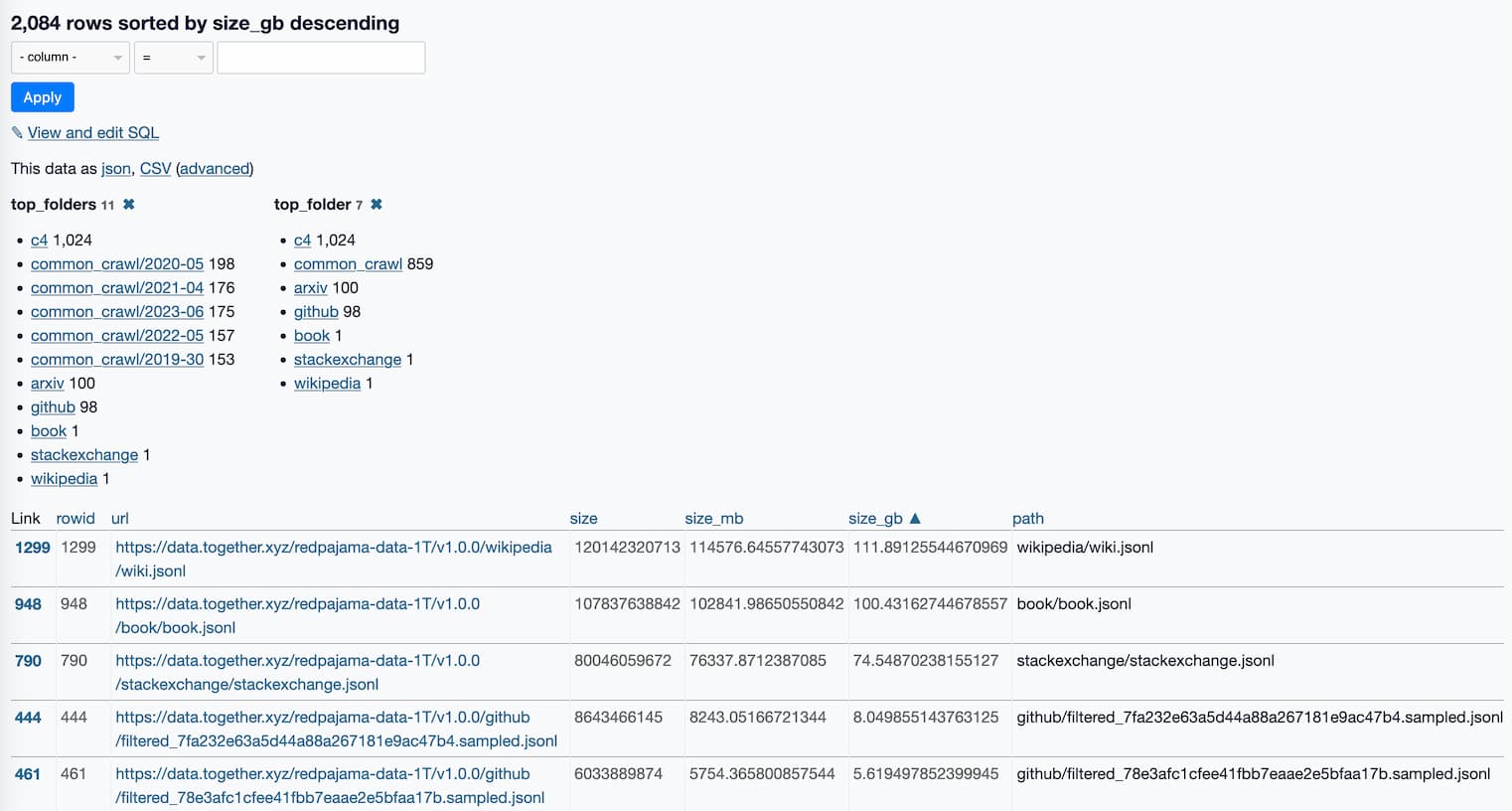
这已经揭示了很多关于数据的信息。
top_folders facet 启发我运行这个 SQL 查询:
选择 顶级文件夹, 将( sum (size_gb)作为整数)转换为total_gb, 计数( * )作为num_files 从原始 按 top_folders 分组 按总和排序(size_gb) desc
以下是结果:
| 顶级文件夹 | 总计_gb | 文件数 |
|---|---|---|
| c4 | 806 | 1024 |
| common_crawl/2023-06 | 288 | 175 |
| common_crawl/2020-05 | 286 | 198 |
| common_crawl/2021-04 | 276 | 176 |
| common_crawl/2022-05 | 251 | 157 |
| common_crawl/2019-30 | 237 | 153 |
| 知乎 | 212 | 98 |
| 维基百科 | 111 | 1个 |
| 书 | 100 | 1个 |
| arxiv | 87 | 100 |
| 堆栈交换 | 74 | 1个 |
那里有很多 Common Crawl 数据!
- CommonCrawl:CommonCrawl 的五个转储,使用 CCNet 管道进行处理,并通过多个质量过滤器进行过滤,包括选择类似维基百科页面的线性分类器。
- C4:标准 C4 数据集
看起来他们从 5 个不同的日期使用了CommonCrawl ,从 2019-30(30?那不是有效的月份)到 2022-05。我想知道他们是否删除了那些不同爬网中的重复内容?
C4是“Common Crawl 网络爬虫语料库的一个巨大的、清理过的版本”——所以是 Common Crawl 的另一个副本,以不同的方式清理过。
我下载了那个 100GB book.jsonl文件的前 100MB – 它的前 300 行都是来自 Project Gutenberg 的全文书籍,从 1611 年的 The Bible Both Testaments King James Version开始。
数据似乎都是 JSONL 格式——换行符分隔的 JSON。我查看的不同文件具有不同的形状,但常见的模式是包含文本的"text"键和包含元数据字典的"meta"键。
例如, books.jsonl的第一行看起来像这样(在使用jq漂亮打印之后):
{
“元” :{
"short_book_title" : "圣经新旧约英王詹姆士版本" ,
“publication_date” : 1611 ,
“网址” : “ http://www.gutenberg.org/ebooks/10 ”
},
"text" : " \n\n英王钦定版旧约圣经\n ... "
}
数据集卡片中有更多关于数据集组成的详细信息。
我的 Python 脚本
我写了一个快速的 Python 脚本来做下一个最好的事情:对每个 URL 运行一个HEAD请求来计算数据的总大小。
我提示 GPT-4 几次,然后想出了这个:
导入httpx 从tqdm导入tqdm async def get_sizes (网址): 尺寸= {} async def fetch_size ( url ): 尝试: 响应=等待客户。头(网址) 内容长度=响应。标题。得到( '内容长度' ) 如果content_length不是None : 返回url , int ( content_length ) 除了异常为e : 打印( f“处理URL' { url } '时出错: { e } ” ) 返回url , 0 与httpx异步。 AsyncClient ()作为客户端: # 使用 tqdm 创建进度条 与tqdm ( total = len ( urls ), desc = "Fetching sizes" , unit = "url" )作为pbar : # 使用 asyncio.as_completed 在结果到达时处理它们 coros = [ fetch_size ( url ) for url in urls ] 对于asyncio中的coro 。 as_completed ( coros ): url , size =等待coro 尺寸[ url ] =尺寸 # 更新进度条 酒吧。更新( 1 ) 退货尺寸
我将其粘贴到python3 -m asyncio – -m asyncio标志确保await语句可以在交互式解释器中使用 – 并运行以下命令:
>>> urls = httpx.get( " https://data.together.xyz/redpajama-data-1T/v1.0.0/urls.txt " ).text.splitlines() >>> 尺寸=等待get_sizes(urls) 获取大小:100%|██████████████████████████████████████| 2084/2084 [00:08<00:00, 256.60url/s] >>> sum (sizes.values()) 2936454998167
然后我添加了以下内容以将数据转换为适用于 Datasette Lite 的内容:
输出= [] 对于url ,大小为sizes 。项目(): 路径=网址。拆分( '/redpajama-data-1T/v1.0.0/')[1 ] 输出。追加({ “网址” :网址, “尺寸” :尺寸, “size_mb” :尺寸/ 1024 / 1024 , “size_gb” :尺寸/ 1024 / 1024 / 1024 , “路径” :路径, “top_folder” :路径。拆分( “/” )[ 0 ], “top_folders” :路径。 rsplit ( "/" , 1 )[ 0 ], }) 打开( “/tmp/sizes.json”,“w ” )。写( json . dumps ( output , indent = 2 ))
我将结果粘贴到 Gist 中。
原文: http://simonwillison.net/2023/Apr/17/redpajama-data/#atom-everything