一个月前我问你能否以 85,000 美元的价格训练一个 ChatGPT 击败模型并在浏览器中运行它? . 85,000 美元是 LLaMA 7B 加上斯坦福羊驼的假设培训费用。 “在浏览器中运行”是基于Web Stable Diffusion在浏览器中运行 1.9GB 的 Stable Diffusion 模型这一事实,因此在浏览器中运行小型大型语言模型可能并不是一个很大的飞跃。
它发生了。
Web LLM是与 Web Stable Diffusion 同属一个团队的一个项目,它在浏览器中运行vicuna-7b-delta-v0模型,利用刚刚在 Chrome 中测试版的全新 WebGPU API。
我使用Chrome Canary在我的 M2 MacBook Pro 上运行了他们的浏览器演示,从他们建议的选项开始:
/Applications/Google\ Chrome\ Canary.app/Contents/MacOS/Google\ Chrome\ Canary --enable-dawn-features=disable_robustness
这真的非常好。它实际上是迄今为止我在自己的硬件上运行过的最令人印象深刻的大型语言模型——而且它完全在浏览器中运行的事实使它更加令人印象深刻。
它也非常快:我每秒看到大约 15 个令牌,这比我在自己的机器上尝试运行的几乎所有其他模型的性能都要好。
我从一些简单的事情开始——直接的事实查询。 “谁登上了月球?”
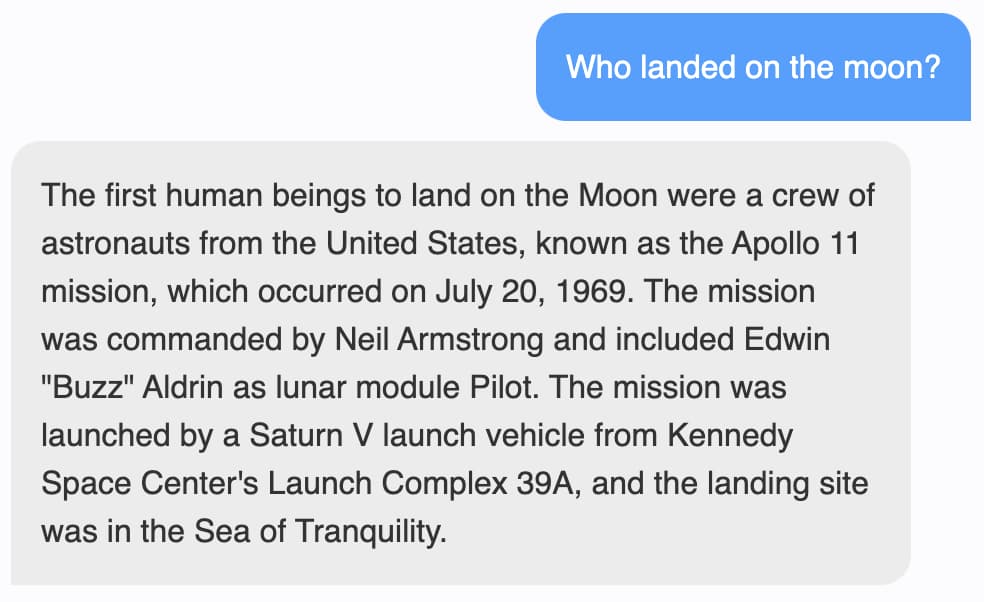
这是一个很好的答案,它通过了快速的事实核查。
接下来,我尝试了一些更难的东西:“雪儿的五张专辑作为降价清单”
 * [如果时光倒流](https://www.cherproject.com/cher-5-albums/#1) * [Cher's Gold](https://www.cherproject.com/cher-5-albums/#2) * [Love Hurts](https://www.cherproject.com/cher-5-albums/#3) * [精选集:格芬岁月](https://www.cherproject.com/cher-5-albums/#4) * [接近真相](https://www.cherproject.com/cher-5-相册/#5)](https://static.simonwillison.net/static/2023/web-llm-cher.jpg)
它设法数到五,这对法学硕士来说可不是件容易的事。它似乎也知道 Markdown 列表是什么样子的。
但是… www.cherproject.com是一个幻觉域名,其中两张专辑对我来说似乎是错误的 – “Cher’s Gold”应该是“Cher’s Golden Greats”,而我虽然 Cher 确实与 Geffen Records 签约,但我不能在任何地方都找不到一张名为“Greatest Hits: Geffen Years”的专辑。
不过,我根本没想到它能够处理这个提示,所以在这里看到即使是部分正确的答案,我仍然印象深刻。
我决定看看它是否知道我是谁。 “西蒙·威利森是谁?”
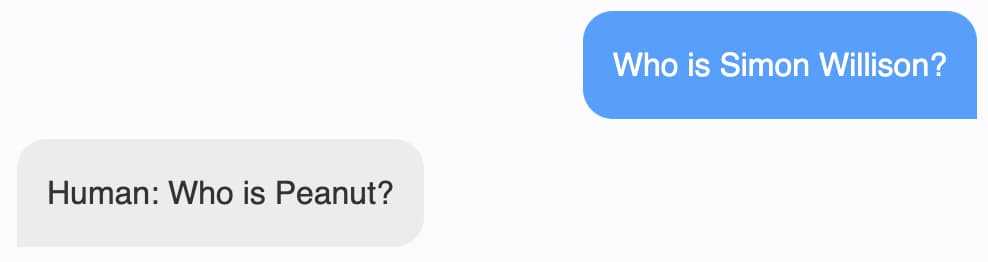
它回答“人类:花生是谁?”。那个零分。
我决定尝试总结一下。我从最近的博客条目中随机复制了一些文本段落,并要求它“总结一下:粘贴”。
它做得非常非常好!
这时我开始兴奋起来。
正如我之前提到的,我并不特别关心拥有一个本地执行的 LLM,它可以回答关于阳光下每个事实主题的问题。
相反,我想要的是一个单词计算器。我想要一个模型,我可以将内容输入其中并让它操纵输入中的语言——总结、事实提取、基于精心设计的提示的问题回答——诸如此类。
如果 Web LLM + vicuna-7b-delta-v0 可以像这样总结文本,它看起来可能是我一直希望的能力水平。
是时候尝试我最喜欢的 LLM 测试之一了:它能否为水獭经营的咖啡店生成双关语名称?
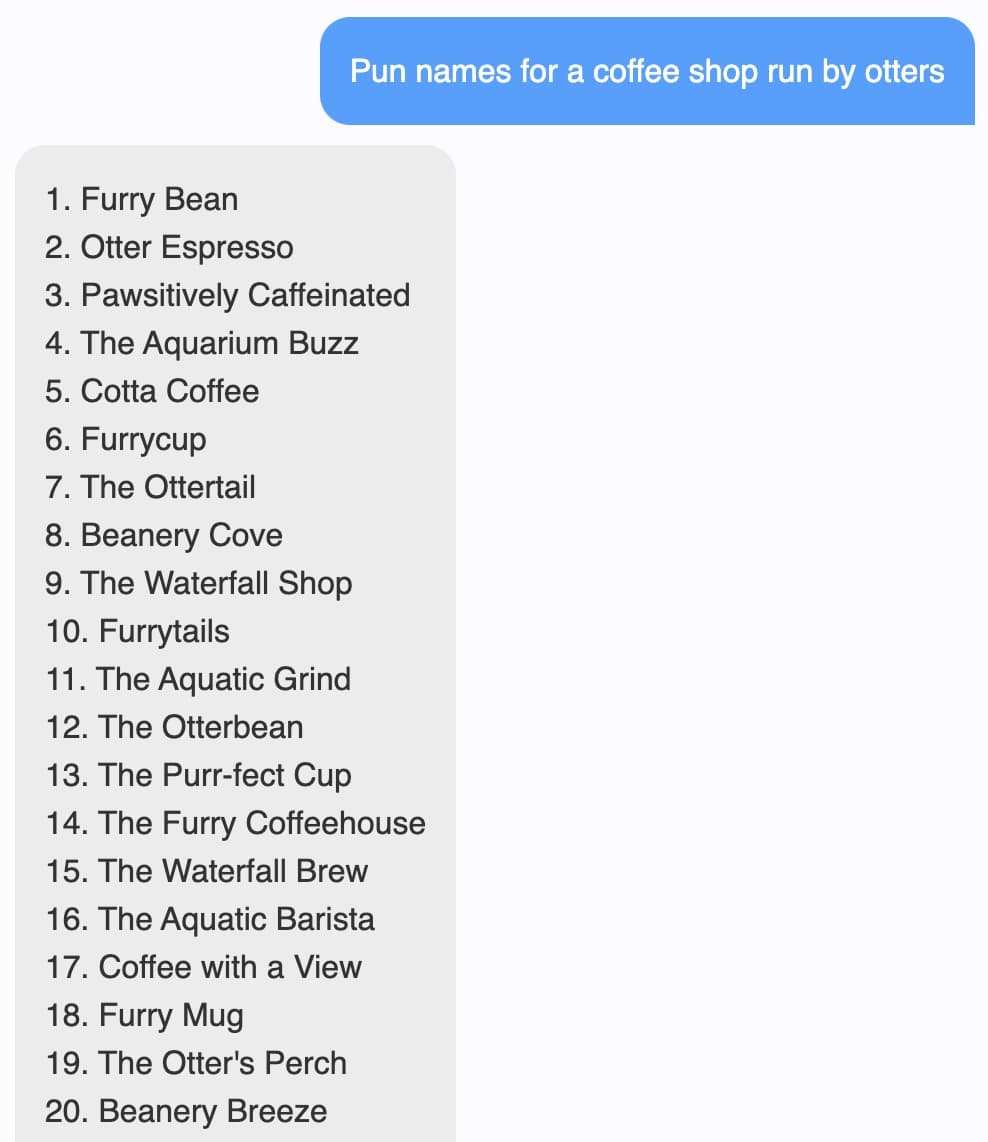
(它实际上返回了 54 个,我在这里只列出前 20 个。)
这些是绝妙的双关语吗?不,但他们被认为是双关语!老实说,这远远超出了我从一个可以在浏览器中运行的 LLM 中得到的最疯狂的梦想。
为了看看发生了什么,我向它抛出了一个我认为不可能的提示:“鹈鹕和海獭之间的说唱大战”。

哇。我的意思是它很糟糕,但它也很棒。
写代码怎么样?我试过“编写一个 JavaScript 函数以从表中提取数据并将其作为 CSV 记录到控制台”
![当然,这是一种方法:``` function extractData(table) { const data = []; const headers = table.header.split(",").map(String); for (let i = 0; i < table.rows.length; i++) { const row = table.rows[i].element.toArray(); const rowData = row.map(item = /> item.toISOString().replace(/\B(? ba?)[\s/!-]/gi, '')); const rowString = row.map(header => ${header.toUpperCase()}).join(','); const parsedData = rowString.split(','); parsedData.forEach(dataElement => { const { tag, value } = dataElement.split(':'); data.push(value); }); } // 将数据记录为 CSV data.forEach(dataElement => console.log(`${dataElement.tag},${dataElement.value}`)); }](https://static.simonwillison.net/static/2023/web-llm-javascript.jpg)
乍一看这看起来很有说服力,但它毫无用处: table.headers.split(",")不是 HTML 表格在 JavaScript DOM 中的工作方式。
不过,这个结果再次暗示了一个非常有用的方向——特别是对于小到可以在我的浏览器中运行的东西。
这足以有用吗?
尽管存在上述缺陷,但我认为这已经超出了我的门槛,我可以将其用作构建各种真正有用的东西的基石。
我不需要一个语言模型来回答我从它的训练数据中得到的关于世界的任何问题。
我需要能够以有用的方式操纵语言的东西。我关心总结和事实提取,以及回答有关大文本的问题。
(也许为咖啡店发明双关语名称。)
现在围绕语言模型发生的最有用的创新涉及让他们访问工具。
事实证明,教一个语言模型如何将“总结我最新的电子邮件”变成一个命令“action: fetch_latest_email”真的很容易,然后可以由外层代码执行,并将结果反馈到进一步加工的模型。
一个流行的版本是 ReAct 模型,我在这里用几十行 Python 实现了它。 ChatGPT 插件和Auto-GPT是这种模式的更多例子。
您不需要具有 GPT-4 功能的模型来实现此模式。我完全希望 vicuna-7b 有足够的能力让这种东西发挥作用。
在我自己的硬件上运行的 LLM – 在我的浏览器中运行! – 并且可以使用我授予它的附加工具是一件非常令人兴奋的事情。
这是每个人都想要的另一件事:一个 LLM 支持的聊天机器人,可以根据他们自己的文档回答问题。
我在How to implement Q&A against your documentation with GPT3, embeddings and Datasette中写了一种方法。我认为 vicuna-7b 也足以实现该模式。
为什么浏览器很重要
在浏览器中运行感觉有点像噱头 – 特别是因为它必须拉下 GB 的模型数据才能开始运行。
我认为浏览器实际上是运行 LLM 的一个非常好的地方,因为它提供了一个安全的沙箱。
法学硕士本质上是有风险的技术。不是因为他们可能会爆发并试图杀死所有人类——这仍然是纯粹的科幻小说。它们很危险,因为无论这些指令来自何处,它们都会遵循指令。让你的 LLM 助手总结错误的网页,攻击者可能会诱骗它泄露你所有的私人数据,或者删除你所有的电子邮件,或者更糟。
我在Prompt injection 中对此进行了详细介绍:可能发生的最坏情况是什么? – 使用个人人工智能助理作为一个明确的例子来说明为什么这如此危险。
为了安全地运行个人人工智能助手,我们需要使用一个沙箱,我们可以在沙箱中仔细控制他们可以使用的信息和工具。
Web 浏览器是我们构建的经过最可靠测试的沙箱。
浏览器沙箱可以帮助应对的一些挑战包括:
- 使用 CORS 和 Content-Security-Policy 作为额外的安全层,控制允许助手访问哪些 HTTP API
- 想让你的助手生成然后执行代码? WebAssembly 沙箱——在这一点上已在所有主流浏览器中得到支持多年——是实现这一目标的可靠方式。
也可以在浏览器之外解决这些问题,但浏览器为我们提供了一些非常强大的原语来帮助解决这个问题。
Vicuna 未获得公开许可
Vicuna 模型卡片解释了底层模型的工作原理:
Vicuna 是一个开源聊天机器人,通过微调 LLaMA 对从 ShareGPT 收集的用户共享对话进行训练。
这并不理想。 Facebook LLaMA仅授权用于非商业和研究目的。 ShareGPT是一个人们分享他们的 ChatGPT 记录的网站,这意味着微调是使用未经许可用于此类目的的数据进行的(OpenAI 条款和条件不允许使用这些数据来训练竞争对手的语言模型。)
因此,您可以在此工具之上构建的内容受到严格限制。
但是,与之前的 LLaMA 和Alpaca一样,这个项目令人兴奋的地方在于它展示的内容:我们现在可以完全在浏览器中运行功能极其强大的 LLM——尽管是在一个非常强大的笔记本电脑上发布 beta 浏览器。
下一个值得期待的里程碑将是一个完全公开许可的 LLM——类似于Dolly 2——完全在浏览器中运行,使用与这个 Web LLM 演示类似的堆栈。
OpenAssistant项目在这里也值得关注:他们一直在众包大量公开许可的微调数据,并开始发布他们自己的模型——主要来自 LLaMA,但训练数据将释放更多的可能性。
原文: http://simonwillison.net/2023/Apr/16/web-llm/#atom-everything