
今年伊始承诺进行更多实验。这在一定程度上也是为什么在过去的几周里我写了很多关于 AI 和各种思考它的方法的原因。但我认为了解它的实际运作方式很有用。所以我做了一堆关于我现在可以用它做什么的实验,下面是我认为可能会发生的事情!
在计算时代的黎明,昔日的微处理器开始并创造了一场确定性革命1 。逻辑门在他们允许的范围内是严格的。您输入的内容决定了输出的内容,并且可以证明并且可重复地相同。
事实上,直到最近,这才是将 AI 应用于事物的问题。虽然你在广告或新闻源等领域看到了大量应用,但在没有更高准确度就无法生存的领域中,应用要少得多。就像医学或执法一样。需要多个 sigmas 精度的事情过去是,现在仍然是 AI 的致命弱点。
那是因为它试图像一个黑盒计算器一样工作,以足够的准确性重复进行类似机械的操作。相反,我喜欢将 LLM 概念化为模糊处理器。一个在分析方面做得更好的人,这是一项服务工作。它在其阶段的许多部分已经没有很高的准确性,但它确实需要大量信息的巧妙组合2 。
我们可以从小事做起,像对待乐高积木一样对待他们。可以说langchain和其他人开始提供帮助。但是乐高积木必须手动构建。尽管人们建造了月球大小的战舰,但制造它们的复杂程度是有上限的。诀窍是尝试让零件自行组装。
如今,他们会产生幻觉,有时还会产生奇怪的输出,尤其是在对话模式和零镜头模式下完成时。但我们今天对待这些产品及其变体就像对待计算机一样。询问 Bing、Sydney、ChatGPT。让它写诗,问它关于历史奥秘的问题。
我认为这可能就是为什么我们尝试将其拟人化的原因。相反,如果我们将它们视为我们将部分思维外包给的处理器,那么错误就会变成需要纠正的错误。这就是为什么我喜欢模糊处理器类比3的原因。法学硕士的力量,在今天看来令人惊叹,并不局限于按需创作诗歌。当您将其中的 10,000 个链接在一起时,就像处理器一样,真正的魔法就会发生!
您每天进行多少次 Google 搜索? ChatGPT 请求怎么样? 100? 500?一切以人为本。在最后一分钟,您的处理器可能在没有做很多事情的情况下获得了大约 25,000 次 ping。
这是近 20 年来第一次有可能构建真正史诗般的东西,一个操作系统来构建一个全新的类别。让我们从我所说的三个示例开始,记住这些就像我们在 DOS 上编写的 Hello World 程序!
三个例子
一个简短的回避步骤,看看我们如何创建乐高积木。以下是我尝试尝试并自己稍微测试一下功能类型的三个示例。 (如果您不觉得这很有趣,请随意跳到下一节,或者如果您需要更多屏幕截图,请在脚注中找到。)
-
通过创建搜索条目找到答案,找到最重要的条目和与您的问题相关的主题,然后总结最热门的搜索链接
我们现在可以迭代查询并实时了解我们喜欢的任何事情,并将处理器与真实世界的信息联系起来。
我是根据家人的旅行计划做的,对我们喜欢的东西有限制。但想象一下这里有什么可能。我们可以搜索特定的数据库,比如只搜索科学论文,我们可以根据特定的属性进行预选,比如作者机构或引用,然后让 LLM 为你总结。或者 YouTube 视频并在总结之前转录它们。
今天,有时搜索不是很好。我找到的解决方案是使用另一个 LLM 调用来首先提取任何关键实体或相关信息,然后进一步优化查询。这意味着从搜索引擎和 LLM 开始,我们现在基本上可以使用它们来创建、研究和分析多个假设,并从中进行选择4 。
更多这里5 !
-
上传文档或目录,找出文件类型,并将它们编入索引以进行问答,或递归总结任何查询的答案
我尝试的另一件事是找到越来越复杂的偷懒方法。在编写 Strange Loop 的过程中,我阅读了一些论文、书籍和许多无聊的网站。
其中大部分内容当然是试图找出文档实际所说内容的要点,并进行相当多的来回询问。因此,我尝试了递归摘要(将文本切成块并分别对每一位进行摘要,然后对摘要进行摘要)并创建嵌入来搜索文本,这很有用!我们可以对整个目录做同样的事情,在那里我们可以读取里面的所有文件并做完全相同的事情6 。
如果启动得当,它甚至可以进行比较,并对每个块进行签名以确保我们有引用!
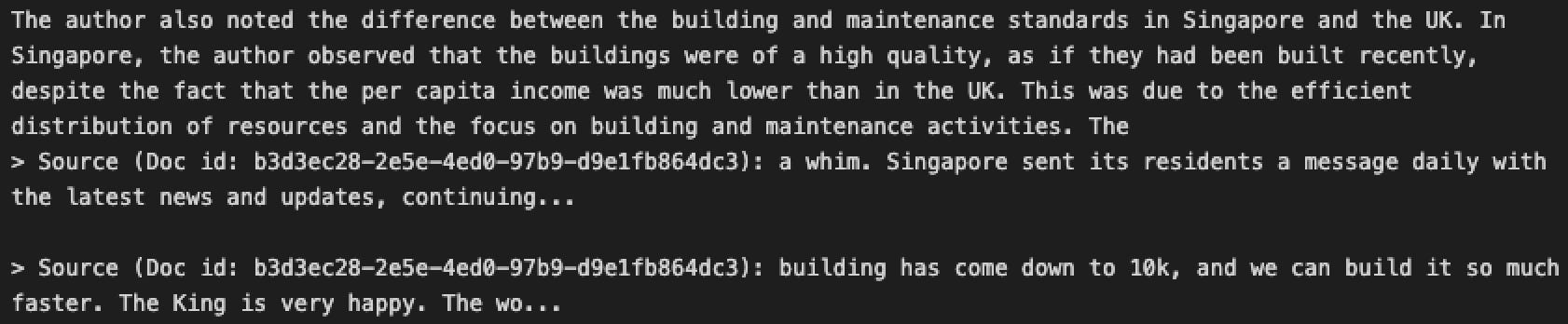
(如果你是那种阅读 Strange Loop Canon 的人,这就是它认为你喜欢的人才选择7 。)
-
将问题分解为核心元素,分离每个实体,使用 Wolfram Alpha 进行计算并总结结果
对于大量查询,很难从 GPT-3 的文本自动完成中获得直接答案,因为预测下一个标记与实际计算某物的工作原理是两码事。
为此,您可以提取实体或要求 LLM 以计算形式表达特定问题,然后将其传递给 Wolfram Alpha 让它回答问题。
困难主要是因为我想知道的问题类型并不是特别计算性的,计算元素在许多问题中是“固有的”,而不是要点。

更多在这里8 !
还缺什么
在我的探索中有趣的是,如果不经过大量的反复试验,要弄清楚这些新的模糊处理器什么是可能的,什么是不可能的并不是那么容易。为了处理通过它们传入的数据,它们必须“了解”我们所生活的世界。
这意味着它不是一个简单的处理器,而是一个内部有迷你世界的处理器。到目前为止,大多数处理器将它们正在处理的内容与它们使用的方法分开,但在这里它们错综复杂地联系在一起。
如果您真的愿意,这就是人们假设 GPT-3 内部存在麦克斯韦妖的地方,拉动它的矩阵弦使答案成真。但唯恐我们拟人化太多,这也是我们可以将其用作小型模块化堆栈的原因。
处理这些迷你世界很困难,因为我们还没有它们的操作码,没有关于如何使用它们的手册,也没有超越过去几年我们共同创造的试错猜测的途径.
就像,对于我问的大多数问题,包括许多总结和问答问题,需要的是一个“持续监控”模块,它可以提取答案中需要计算的方面。
“持续监控”模块需要来自备用 LLM 的更多常规输出 <> 输入,在今天并不容易,但很快就会变得可行。
建造它需要我们几年的时间,但这是值得的!
所以,建立你自己的个人分析师
就像原来的处理器很弱,不能做很多事情一样,只有将一大堆处理器结合在一起,你才能获得魔力。
当我们以前这样做的时候,我们有个人电脑。当我们现在这样做时,我们会得到个人分析师。
将所有这些联系在一起,我们已经可以看到它栩栩如生,尽管形式更简单。可以:
-
阅读并总结任何文档
-
创建可以聪明地获得答案的问题,然后对其进行问答
-
如果需要,对照另一组文本检查答案
-
根据需要计算事物,如果答案需要的话
-
上网查查不熟悉的东西,总结答案
-
以最有影响力的各种格式编写它们
如果您想扩展它以创建更聪明的分析师,我们可以进一步添加模块:
-
添加 LLM 模块以测试答案和摘要,并检查它们是否“叠加”到任何任意能力
-
使这些模块针对特定任务进行微调——检查答案的模块不必与创建答案的模块相同,监控性能的模块不必与充当“图书馆员”进行搜索的模块相同并从谷歌中提取信息
-
使模块特定于您的输入,从个性到特定数据集,并“允许”代表您采取某些行动
-
是的,一个模块可以接受任何产生的答案,并在它的末尾创建一个美丽而令人回味的书面输出——一篇文章、一张图片、一首诗、一首挽歌等等!
想想这些能做什么!在业务环境中,它可以处理编码、客户交互、编写报告、分析仪表板、创建几乎任何类型的内容或对其进行编辑,并采取措施读取/编辑/写入您选择的数据库或发送 Slack 消息或者 …..
这让我得出了最令人惊讶的结论:LLM 的大多数错误都可以通过添加更多的 LLM 调用来改善。
模糊处理器是我们一直在做的下一个计算块的解锁,即使我们将计算卸载到机器上也是如此。随着成本下降 90% 并再次成倍下降,这些更接近现实。
我们今天开始看到这一点。今天,像Consensus和Elicit这样的公司正在将各个部分连接在一起,以创造出真正有价值的输出,这在以前需要一名研究助理——帮助研究总结、搜索、找出要问的新问题等等!
像大多数自动化一样,它大大增加了个人做更多事情的潜力。
曾经有“计算机”,由女性组成的团队计算复杂的数值问题,帮助我们登上月球,现在被我们贺卡中存在的计算量所取代。
这里的一台新机器可能会取代“分析师”——分析复杂问题的人员团队,他们帮助产生了世界上许多伟大的创新,他们将慢慢被取代。
当“计算机”被计算机取代时,就有了分工。计算机的计算部分实现了自动化,而计算的思考部分却没有。它慢慢迁移到我们创建和应用算法以帮助理解世界的方法中。
同样,当分析师被“分析师”取代时,就会出现分工。公司内部和外部将开始出现责任转移的趋势。我认识的每个分析师都认为他们的大部分工作都是“胡说八道的工作”,即使边界扩大,这也会变得自动化。
也许这是一份需要开公司的工作。或者一个新的Homebrew Analyst Club来试验和开发这项技术。
谁的游戏?


如果您喜欢这篇文章,您可能还喜欢:

这里的战斗让我想起了过去的筹码大战。 Intel 4004 开始它的生活试图成为 MOS 硅栅技术王者,准备计算。很快,市场上出现了多个用于特定任务的专用处理器,随着通用处理器变得越来越好,这些处理器逐渐被淘汰。
您拥有数字信号处理器,专门用于实时有效地处理音频和视频。你有现场可编程门阵列,用于航空航天和国防等。你有浮点阵列,旨在执行高速浮点运算,或网络处理器,旨在执行其同名任务。
并且有一些公司建立在这个基础上。用于 FPGA 的 Xilinx,或 Altera。 Analog Devices 的 DSP 芯片。 Altera 被 Intel 以 160 亿美元收购,AMD 以 350 亿美元收购了 Xilinx。
这有点类似于 AI 世界。我们拥有像 GPT-3 这样的基础模型,这些模型由现在规模足以成为现有企业的初创公司构建,并且我们有人试图创建自己的通用处理器或与这些通用处理器竞争。
模糊处理器在这里特别熟练。它们建立在生成人工智能的基础上,生成的人工智能可以是任何机器的任何东西,并且它们内部有某种版本的内部世界模型。因此,他们倾向于对大量人类问题给出相对连贯但不确定的答案。就像计算器工作是因为算术运算的想法对它“有意义”一样,LLM 可以“理解”单词,只是在更模糊的程度上。
但是因为 AI 本身变得越来越好,而且因为 LLM 提供了新的处理器,我们现在可以做更多的事情。
正如一位朋友指出的那样,这可能更适用于小芯片而不是处理器,但我更喜欢处理器的声音作为类比
我也在 linkedin、www.strangeloopcanon.com 和 twitter 上为我的个人资料做了这个,它很好地了解了我对人才、初创公司和 AI 的看法。随着您可以向 LLM 提供的信息类型的增加,我们也可以以我们未曾想到的方式使用这些处理器!
对于旅行,这可能意味着提取有关地点、时间或旅行的特定信息,并创建替代搜索选项。这意味着您可以相互测试几个选项,如果您想要(同时检查您想要的旅行,它是相反的,或者它的同伴搜索)。

现在,如果您愿意,您可以添加另一个 LLM 以从搜索中进行选择,并根据您的喜好进行优化。

这不是很不可思议吗?
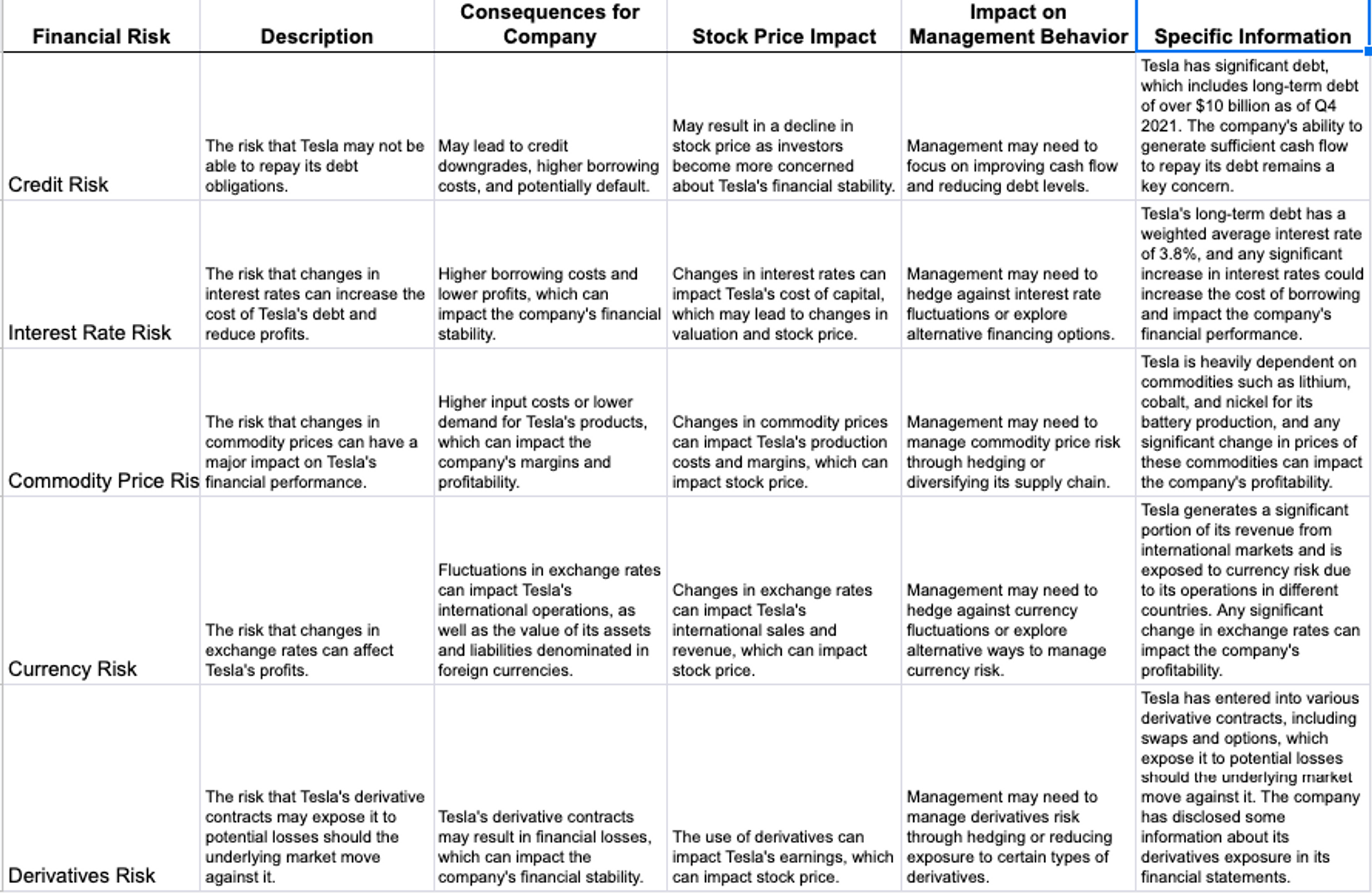
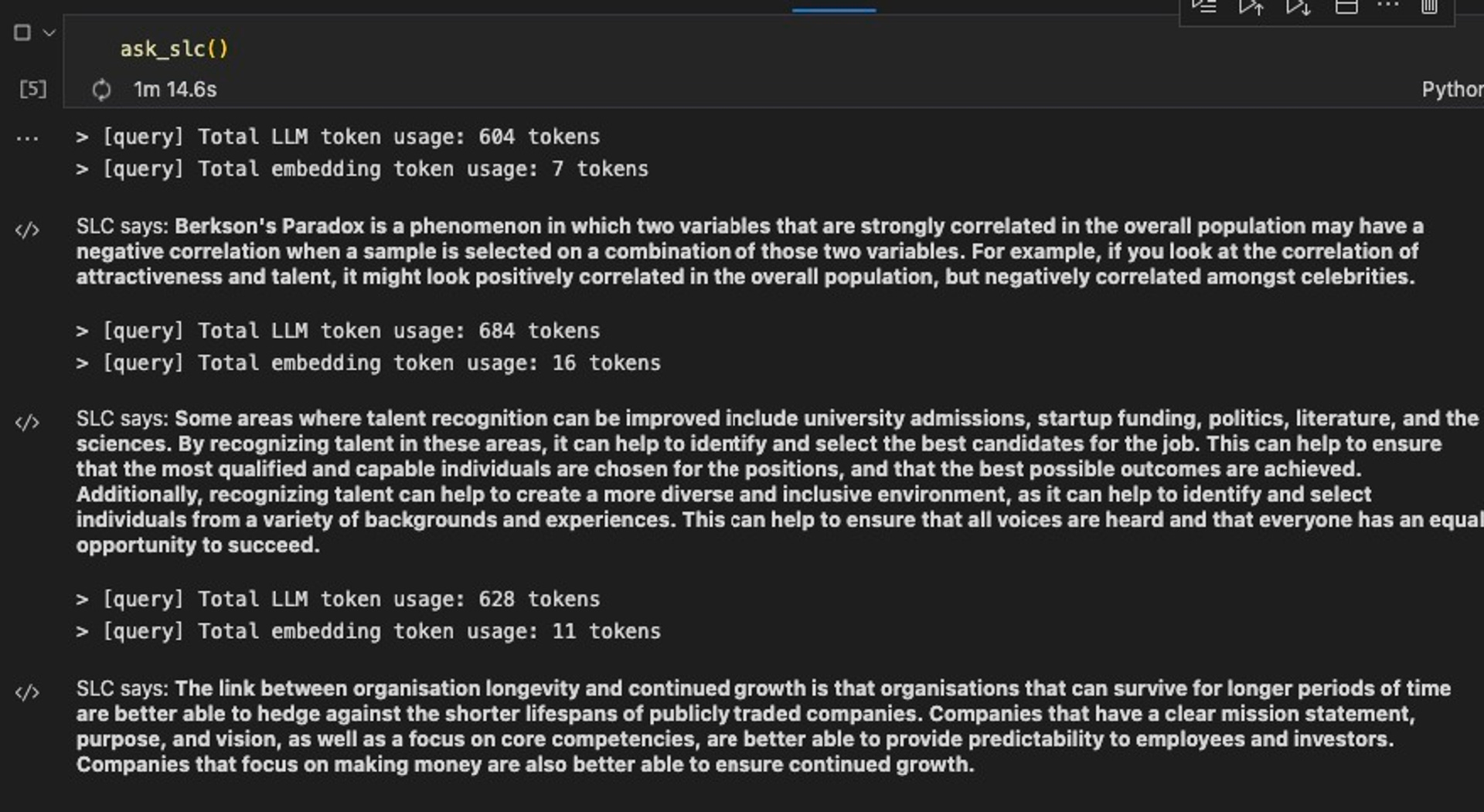
例如,对于之前的特斯拉问题,在对一堆年度报告进行索引之后,我想用它来进行各种计算,比如计算特定风险指标等。但是 Wolfram Alpha 需要更具体的输入,所以我必须训练 GPT-3 如何制作这些输入。
原文: https://www.strangeloopcanon.com/p/computer-used-to-be-a-job-now-its