除了探索新的 MusicCaps 培训和评估数据外,我还一直致力于大型 Datasette JSON 重构,并对我根本没有参与的 Datasette 项目感到兴奋。
数据集刮板
关于插件系统的最好的事情是,有一天你可以醒来,你的软件已经增加了额外的功能,甚至不需要审查拉取请求。
Colin Dellow 的datasette-scraper – 几周前首次发布 – 更进了一步:它是一个在 Datasette 之上构建整个自定义应用程序的插件。
这个真的很酷!
Colin 在 YouTube 上有一个十分钟的演示,非常值得一试。
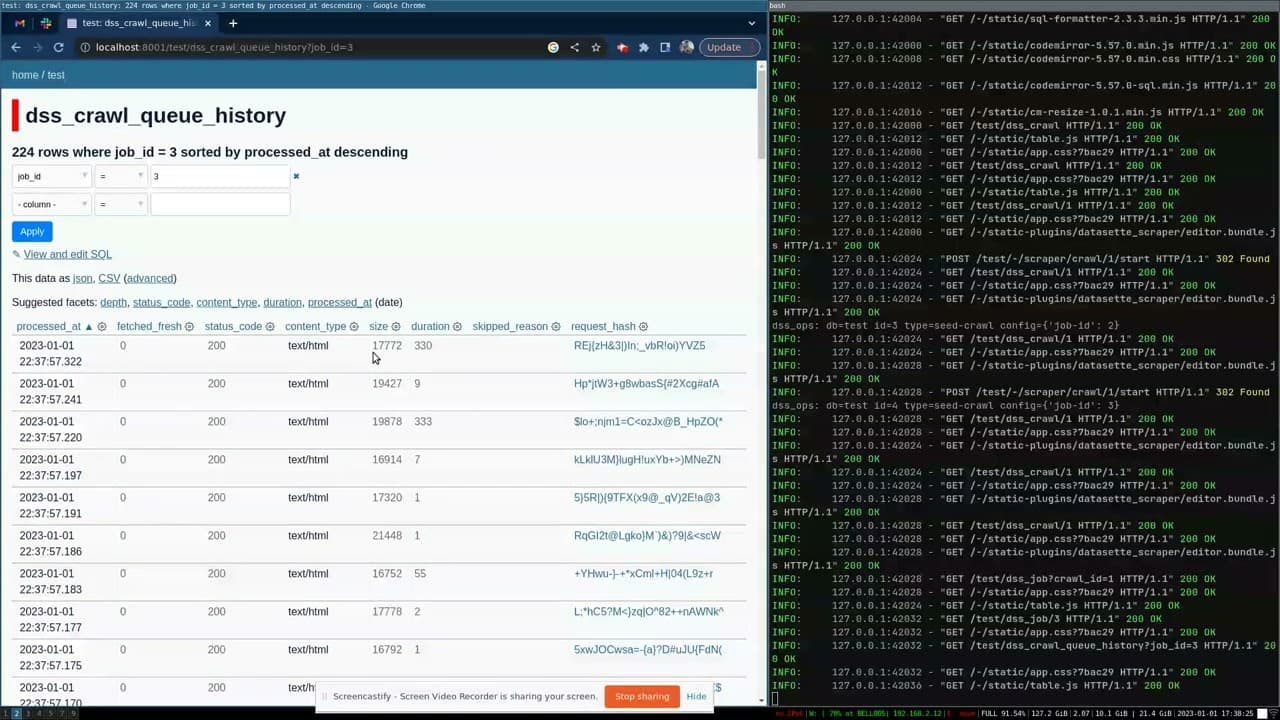
该插件实现了一个网站爬虫,它可以爬取页面、建立队列(如果可用,则使用sitemap.xml ),然后获取和缓存内容——将其进度和结果数据存储在由 Datasette 托管的 SQLite 数据库中。
它使用一些非常巧妙的技巧来自定义 Datasette 界面的各个部分,以提供用于配置和控制爬虫的界面。
最令人印象深刻的是,它实现了自己的插件挂钩……这意味着您可以使用小型自定义插件来定义您希望如何从正在抓取的页面中提取数据。
Colin 还有很多其他的 Datasette 插件也值得一试:
- datasette-rewrite-sql monkey-patches Datasette 的数据库连接代码(因为那里还没有合适的插件挂钩)为进一步的插件功能提供自己的挂钩,这些插件功能可以在执行之前重写 SQL 查询。
- datasette-ersatz-table-valued-functions ( ersatz (adj.): made or used as as a substitute, typically an inferior one, for something. ) 是一个令人愉快的粗糙 hack,它支持 SQLite 中的自定义表值 SQL 函数,尽管Python 的
sqlite3模块不提供这些。它的工作原理是针对返回 JSON 的函数重写 SQL 查询,以使用粗糙的 CTE 和 json_each()组合代替。 - datasette-ui-extras是全新的:它以各种方式调整 Datasette 默认界面,在侧边栏中添加粘性标题和 facets 等功能。我很高兴看到有人以这种方式尝试对默认 UI 进行更改,并且我完全希望 Colin 在这里尝试的一些想法将来会成为 Datasette 核心。
进展情况?_extra=
我终于开始在Datasette 问题 #262 上取得进展:添加 ?_extra= 机制以请求 JSON 中的额外属性– 于 2018 年 5 月首次开放!
这是精简 Datasette 表和查询的默认 JSON 表示的关键步骤。
我想默认返回这个:
{
“好的” :是的,
“行” :[
{ "id" : 1 , "title" : "示例 1 " },
{ "id" : 2 , "title" : "示例 2 " },
{ "id" : 3 , "title" : "示例 3 " }
],
“下一个” :空
}
然后允许用户指定各种额外信息 – 表模式、建议的方面、列信息、底层 SQL 查询……所有这些都通过在 URL 上添加?_extra=x参数来实现。
事实证明这需要大量工作:我必须完全重构 Datasette 代码库中最复杂部分的内部结构。
还有很多路要走,但我很高兴终于在这里取得进展。
改进的数据集示例
Datasette 网站长期以来一直有一个从顶部导航链接到的示例页面 – 分析显示它是该网站上访问量最大的页面之一。
我终于对该页面进行了所需的升级。它现在从已选择的插图示例开始,以帮助突出 Datasette 可以做什么——它可以用来解决的各种问题,以及可以使用插件添加额外功能的方式。
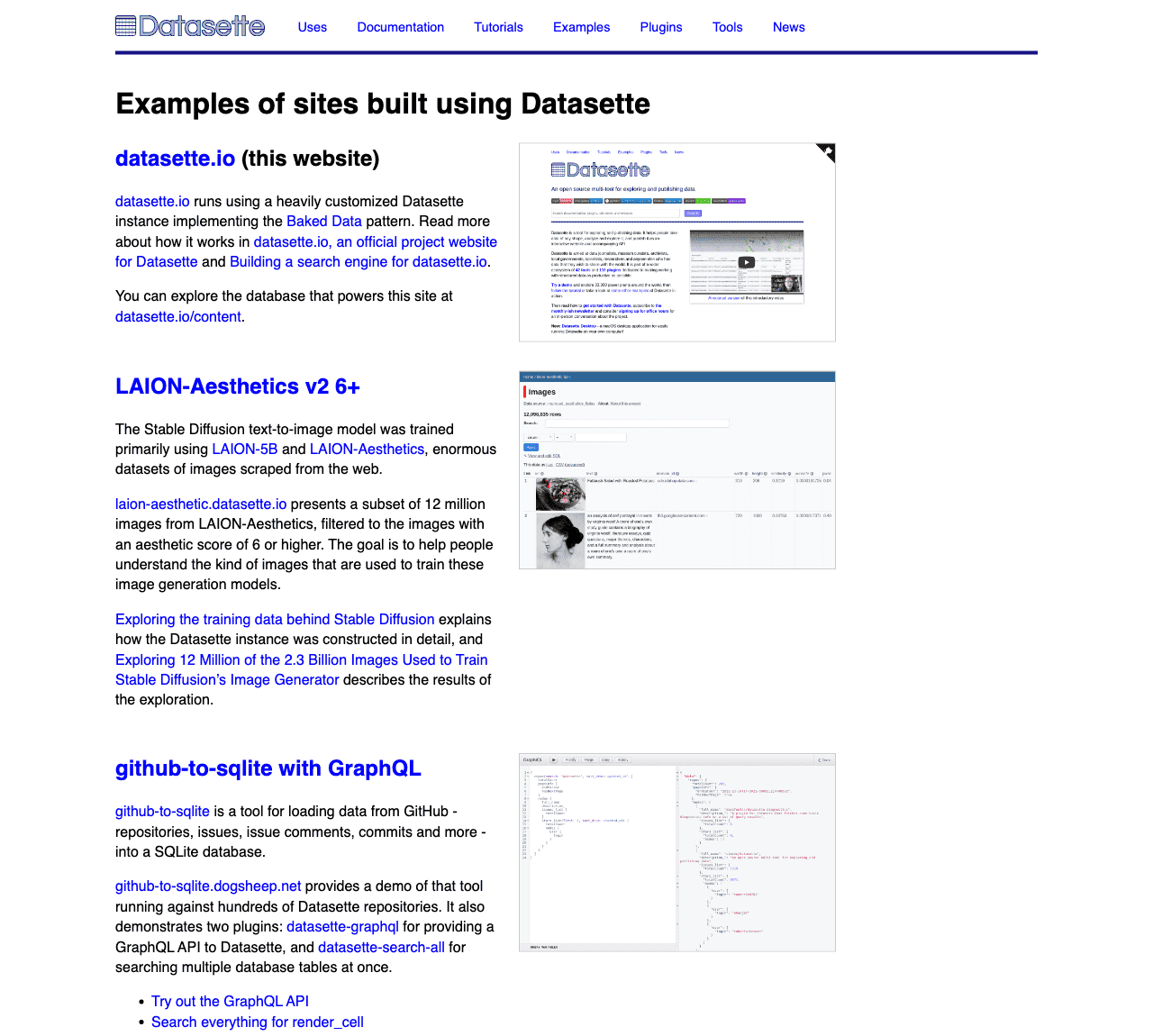
喷丸机 1.1
我使用我的shot-scraper截图自动化工具为示例页面实现了新的截图。
屏幕截图由datasette-screenshots存储库中的 GitHub Actions 工作流截取。
我向支持该工作流的 YAML 添加了 5 个新的屏幕截图定义,该工作流由shot-scraper multi命令使用。
在使用shot-scraper时,我发现了一些小改进的机会, 1.1 版有以下变化:
数据集
Granian是一个新的 Web 服务器,用于运行 Python WSGI 和 ASGI 应用程序,用 Rust 编写。
不久前,我构建了 datasette-gunicorn ,这是一个插件,它添加了一个datasette gunicorn my.db命令,用于使用Gunicorn WSGI 服务器为 Datasette 提供服务。
datasette-granian现在使用 Granian 提供同样的东西。这是一个 alpha 版本,因为我还没有在生产中实际使用它,但它似乎运行良好,并且它为想要部署 Datasette 的人增加了另一个选择。
Granian Giovanni Barillari 的创建者真的很有帮助,帮助我弄清楚如何动态地为新配置的 ASGI 应用程序提供服务,而不是仅仅将模块路径传递给granian CLI 命令。
数据集-faiss 0.2
几周前我介绍了 datasette-faiss 。它是一个插件,支持使用 Facebook Research 的FAISS矢量搜索库在 Datasette 中进行快速矢量相似性查找。
该插件的第一个版本在服务器启动时为每个包含嵌入列的表创建了一个 FAISS 索引。然后将针对整个表运行任何相似性搜索。
但是,如果您想将这些搜索与查询中的其他过滤器结合起来怎么办?例如,首先筛选出 2022 年发表的每篇文章,然后对剩下的文章进行相似性搜索。
在datasette-faiss 0.2 中,我引入了两个新的 SQLite 聚合函数: faiss_agg()和faiss_agg_with_scores() ,它们旨在处理这种情况。
新函数的工作原理是每次调用它们时从头开始构建一个新的 FAISS 索引,仅覆盖聚合处理过的行。
这最好用一个例子来说明。以下查询首先选择 2022 年发布的博客条目的嵌入,然后使用它们来查找与提供的 ID 最相似的项目。
entries_2022作为( 选择 ID, 嵌入 从 blog_entry_embeddings 在哪里 id in (从blog_entry 中选择id,其中的创建类似于“ 2022% ” ) ), 假设为( 选择 faiss_agg( ID, 嵌入, (从blog_entry_embeddings 中选择嵌入,其中id = :id), 10 )作为结果 从 条目_2022 ), ID为( 选择 值作为id 从 json_each ( faiss.results ), 费斯 ) 选择 博客条目。编号, 博客条目。标题, 博客条目。创建 从 ids 在ids上加入blog_entry。 id =博客条目。 ID
本周发布
- shot-scraper : 1.1 -(总共 25 个版本)- 2023-01-30
用于自动截取网站屏幕截图的命令行实用程序 - datasette-render-markdown : 2.1.1 -(总共 10 个版本)- 2023-01-27
用于渲染 Markdown 的 Datasette 插件 - 数据集-youtube-嵌入: 0.1 – 2023-01-27
将 YouTube 网址转换为 Datasette 中的嵌入式播放器 - 数据集-格兰尼安: 0.1a0 – 2023-01-20
使用 Granian HTTP 服务器运行数据集 - datasette-faiss : 0.2 -(总共 2 个版本)- 2023-01-19
维护指定数据集表的 FAISS 索引
直到本周
- 重写 Git 存储库以从历史中删除秘密
- SQLite pragma_function_list()
- 在 M1/M2 Mac 上为 Python 安装 lxml
- 在 SQLite 中结合 CTE 和 VALUES
原文: http://simonwillison.net/2023/Jan/30/datasette-scraper/#atom-everything