没有日志的数据确实让我们有可能进行猜测。
我快速浏览了一下curl.se网站现在的流量情况。只是出于好奇。
免责声明:我们根本不记录网站访问者,我们不在网站上运行任何网络分析,因此我们基本上不知道谁在网站上做了什么。这样做既是出于隐私原因,也是出于实际原因。管理此设置的日志是我宁愿避免做和付费的工作。
我们拥有的是一个由 Fastly 在其 CDN 网络上托管(前端)的网站,作为该设置的一部分,我们有一个提供累积流量数据的管理界面。我们得到了一些数字,但没有细节和细节。
带宽
上个月,该网站提供了62.95 TB 的服务。这使得平均每天超过 2TB 。在此期间最活跃的一天,它发送了3.41 TB 数据。
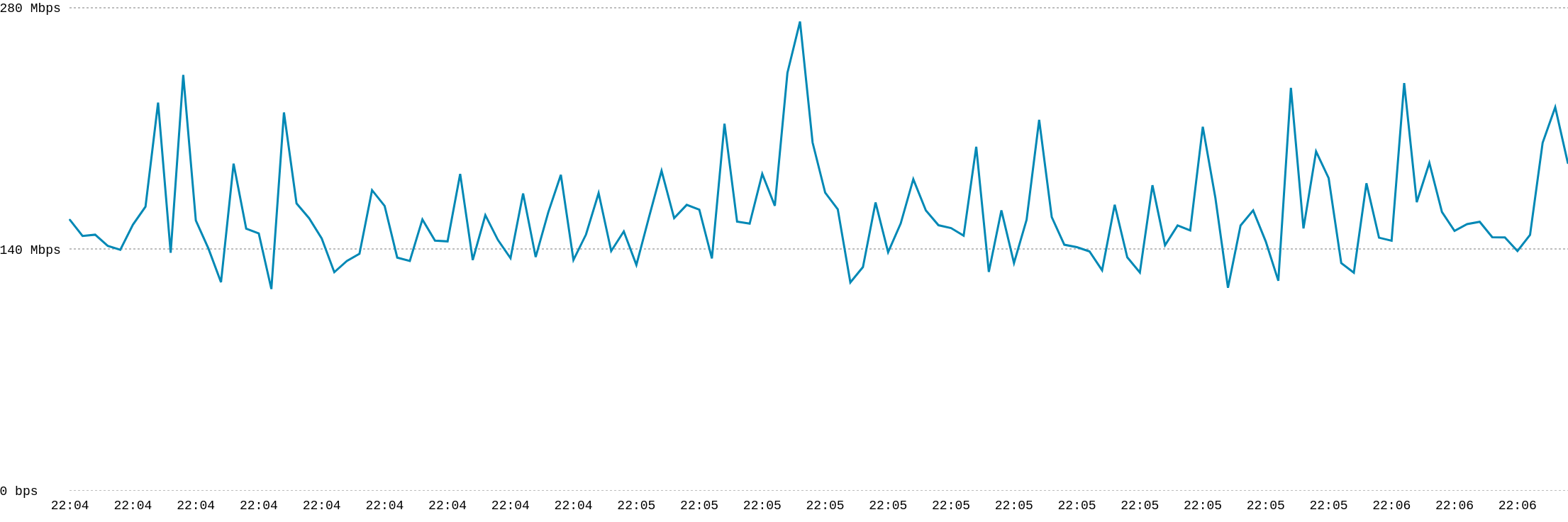 这是我在撰写这篇博文时显示的实时带宽计。
这是我在撰写这篇博文时显示的实时带宽计。要求
在124.3亿个请求时,平均请求传输大小为5568字节。
下载
由于我们没有日志,所以无法完美统计curl的下载情况。但我们确实有来自站点的不同大小对象的请求频率统计数据,并且在 1MB-10MB 类别中我们基本上只有curl tarball。
上个月此类对象的下载量为112万次。每天下载37,000 次,或者全天候每隔一秒下载一个卷曲 tarball。
当然,大多数curl 用户从来不会从curl.se 下载它。源档案也从 github.com 提供,用户通常从他们的发行版下载 curl 或将其与操作系统一起安装等。
但…?
最近 22 个版本的平均卷曲 tarball 大小为4,182,317字节。 3.99 MB。
112 万 x 3.99 MB仅为4,362 GB 。连总流量的百分之十都不到。
即使我们仅计算最近版本的 zip 存档的平均大小( 6,603,978字节),总共也只有6,888 GB。与近 63 TB 的总量相去甚远。
再加上每个请求的平均传输大小较低,似乎表明其他内容以相当大的数量从站点传输出去。
原点卸载
99.77%的请求由 CDN 处理,但未到达源站。我想这是我们主要拥有一个没有 cookie 和动态选择的静态网站的好处之一。它使我们能够获得非常高的缓存命中率和直接从 CDN 服务器提供的内容,从而使我们的源服务器仅承受轻负载。
地区
Fastly是一个CDN,接入点分布在全球,而curl网站是任播的,所以理论上用户访问的是附近的服务器。在同一地区。如果我们假设这有效,我们就可以看到curl 网站的大部分流量来自哪里。
前三名:
- 北美 – 48% 的带宽
- 欧洲 – 24%
- 亚洲 – 22%
传输层安全协议
现在我不是 TLS 协议协商如何与 Fastly 配合工作的专家,所以我在这里进行一些猜测。
令人惊讶的是, 99%的流量都使用 TLS 1.2。这似乎意味着其中很大一部分不是基于浏览器的,因为当今所有流行的浏览器大多都协商 TLS 1.3。
HTTP协议
看似同意我的 TLS 分析,HTTP 版本分布似乎也表明大量流量不是浏览器面前的人类。如今,他们更喜欢 HTTP/3,如果这导致问题,他们会使用 HTTP/2。
98.8%的curl.se 流量使用 HTTP/ 1,1.1%使用 HTTP/2,只有不到0.1%的剩余一小部分使用 HTTP/3。
通过curl 下载?
我不知道实际使用curl 完成的下载份额有多大。我的猜测是公平的份额。 TLS + HTTP 数据意味着大量的机器人流量,但现代的curl 版本至少会选择HTTP/2,除非引导它的用户明确选择不这样做。
那么所有的流量是多少?
过去,我们看到来自中国的下载我们提供的CA 证书存储的流量相当大,但现在流量负载似乎在全球范围内分布得相当均匀。随着时间的推移。
据统计,100KB-1MB范围内的对象被下载了20731万次。这比我们在网站上的图像大,比curl 下载的小。正是 CA 证书 PEM 的范围。最近的一个大小为 247KB。符合道理。
247 KB 的文件下载了 2.07 亿次,相当于 46 TB。也许这就是解释?
赞助
curl 网站托管由Fastly慷慨赞助。
原文: https://daniel.haxx.se/blog/2025/02/22/curl-website-traffic-feb-2025/