我喜欢将调查数据泄露视为对真理的一种科学探索。你从一个理论(一组来自所谓来源的数据)开始,但你对这个说法是否真实没有既得利益,而是你遵循证据并看看它会带来什么结果。支持所声称的来源的验证通常非常简单,但反驳一个主张可能是一项相当耗时的工作,尤其是当数据集包含事实片段与其他数据混合在一起时。这就是我们今天在这里所看到的。
为了引出结论并让您在不愿意的情况下阅读所有详细信息,本周很多人标记我的数据集标题为“Linkedin 数据库 2023 250 万”,结果是公开的 LinkedIn 个人资料数据和 5.8 的组合。 M 电子邮件地址大多由名字和姓氏组合而成。一切都始于这条推文:
据称,一名威胁行为者从 LinkedIn @LinkedIn泄露了 2023 年的数据库。他们声称该数据库显示了电子邮件、个人资料数据、电话、全名和更多机密信息。 #Breach #Clearnet#DarkWeb #DarkWebInformer #Database #Leaks #Leaked #LinkedIn pic.twitter.com/8MQecKc1vz
— 暗网告密者 (@DarkWebInformer) 2023 年 11 月 4 日
所有善意的谎言从表面上看都是可信的; LinkedIn 的海量数据语料库是否可行?好吧,它们在 2012 年就被泄露了 1.64 亿条记录(我的意思是,该事件是真正的内部数据,例如通过漏洞提取的电子邮件地址和密码),然后它们在 2021 年被大规模删除,另外 1.26 亿条记录被泄露我被骗了吗(HIBP)。因此,当您看到像上面这样的说法时,从表面上看它似乎非常可行,这也是许多人所认为的。但我比大多数人更怀疑 ?
一、主张:
这与我的 twitter 数据报废 [原文如此] 类似,但适用于 linkedin plus 2023
现在,关于抓取的数据是否是泄露数据以及它的定义是否重要存在着一场争论。随着抓取数据的日益流行,这个话题出现得足够多,以至于我几年前写了一篇专门的博客文章,并根据我们应该如何定义“违规”一词得出以下结论:
当未经授权的一方以不打算公开的方式获取信息时,就会发生数据泄露
这使得像这样的擦伤行为成为一种违规行为。如果确实准确的话,LinkedIn 数据已被获取并重新分发,而这种方式无论是服务本身还是数据在该语料库中的个人都绝非有意为之。因此,这是值得认真对待的事情,值得进一步调查。
我滚动浏览了 1000 万多行数据(由于行返回,许多记录跨越了多行),我的目光落在了一位澳大利亚同胞身上,出于本次练习的目的,我们将其称为“EM”,这是她的第一个和第二个名字的首字母缩写。姓。虽然我要引用的数据要么是故意公开的,要么是捏造的,但我不想在未经他们同意的情况下使用真人作为例子,所以让我们谨慎行事。以下是 EM 记录的片段:
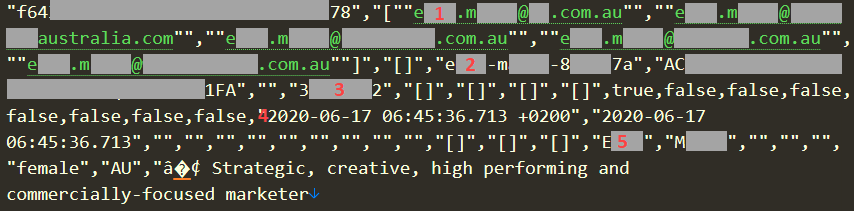
这个 I 有 5 个值得注意的部分立即引起了我的注意:
- 这里有 5 个不同的电子邮件地址,每个地址的别名均以“[名字].[姓氏]@”形式表示。这些存在于标题为“PROFILE_USERNAMES”的列中。 (顺便说一句,这就是为什么 250 万个帐户的标题扩展到 580 万个电子邮件地址的原因,因为每个帐户通常有多个地址。)
- 在标题为“PROFILE_LINKEDIN_ID”的列下有一个 LinkedIn 个人资料 ID,格式为“[名字]-[姓氏]-[随机十六进制字符]”。成功加载了 EM 的合法个人资料:https://www.linkedin.com/in/[id]/
- “PROFILE_LINKEDIN_MEMBER_ID”列中的数值与上一点中 EM 个人资料上的值相匹配。
- 以“2020-”开头的 2 个日期位于标题为“PROFILE_FETCHED_AT”和“PROFILE_LINKEDIN_FETCHED_AT”的列中。我认为这些是不言自明的。
- EM 的名字和姓氏,与她的 5 个电子邮件地址中的每一个地址完全相同。
就其本身而言,这个记录并不引人注目。这是完全可行的 –这很可能是合法的– 除非你继续查看其余数据。一种模式很快就出现了,我将在这里将其加粗,因为这是确凿无疑的证据,最终表明这些数据中的一些是假的:
具有多个电子邮件地址的每条记录在完全不相关的域上都具有完全相同的别名,并且几乎总是采用“[名字].[姓氏]@”的形式。
以这种方式表示电子邮件地址当然很常见,但它远非普遍存在,而且很容易演示。例如,我有大量来自Pluralsight的电子邮件,因此我从我的朋友“CU”那里挖了一封:

没有点,而是破折号。我看到的每一个真实的 Pluralsight 电子邮件地址都是破折号而不是点,但是当我深入研究所谓的 LinkedIn 数据并挖掘出另一个 Pluralsight 地址样本时,我发现了以下内容:
![]()
这不是 LM 的真实地址,因为它有一个点而不是破折号。每一个。单身的。一。是。伪造的。
让我们换个方式尝试一下,将 HIBP 中现有的被泄露帐户加载到 EM 所谓的电子邮件地址之一的域中,看看它们是如何形成的:
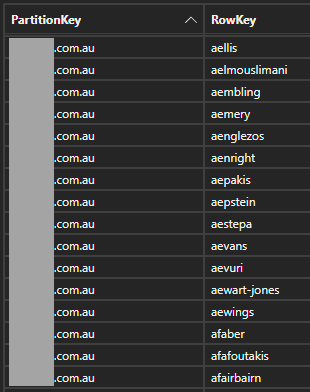
这绝对与 EM 地址的格式不一样,绝对不是。一次又一次,原始推文中的数据语料库中出现了相同的地址模式,这让我得出了一个似乎非常合乎逻辑的结论:
每个电子邮件地址都是通过获取个人合法工作的公司的实际域名,然后根据他们的名字构造别名来伪造的。
这些也是合法的公司,因为我检查的每一份 LinkedIn 个人资料都有准确信息的所有线索,而且我在数据语料库中检查的每个域确实是他们工作的公司的正确域。我想有人已经有效地完成了以下逻辑:
- 获取 LinkedIn 个人资料列表,无论是通过 ID 或用户名,还是只是从爬虫结果中解析它们
- 抓取个人资料并提取有关每个人的合法信息,包括他们的工作经历
- 解析他们工作过的每家公司的域名并构建电子邮件地址
- 利润?
最后一点有什么意义呢?原始推文中的数据并未出售,而是可以免费下载。但根据 EM 资料上的日期,这些数据本来可以更早获得,并且之前已经货币化。就这一点而言,各个记录的日期并不是恒定的,而是有很大范围的记录,最近是去年七月,最古老的是……好吧,当记录比我更老时,我就停止了。这是什么?!
我怀疑答案可能部分在于我将其全部粘贴到此处的列标题中:
“PROFILE_KEY”、“PROFILE_USERNAMES”、“PROFILE_SPENDESK_IDS”、“PROFILE_LINKEDIN_PUBLIC_IDENTIFIER”、“PROFILE_LINKEDIN_ID”、“PROFILE_SALES_NAVIGATOR_ID”、“PROFILE_LINKEDIN_MEMBER_ID”、“PROFILE_SALESFORCE_IDS”、“PROFILE_AUTOPILOT_IDS”、“PROFILE_PIPL” _IDS”、“PROFILE_HUBSPOT_IDS”、“PROFILE_HAS_LINKEDIN_SOURCE”、“PROFILE_HAS_SALES_NAVIGATOR_SOURCE” ”、“PROFILE_HAS_SALESFORCE_SOURCE”、“PROFILE_HAS_SPENDESK_SOURCE”、“PROFILE_HAS_ASGARD_SOURCE”、“PROFILE_HAS_AUTOPILOT_SOURCE”、“PROFILE_HAS_PIPL_SOURCE”、“PROFILE_HAS_HUBSPOT_SOURCE”、“PROFILE_FETCHED_AT”、“PROFILE_LINKEDIN_FET CHED_AT”、”PROFILE_SALES_NAVIGATOR_FETCHED_AT”、”PROFILE_SALESFORCE_FETCHED_AT”、”PROFILE_SPENDESK_FETCHED_AT”、”PROFILE_ASGARD_FETCHED_AT”、 “PROFILE_AUTOPILOT_FETCHED_AT”、“PROFILE_PIPL_FETCHED_AT”、“PROFILE_HUBSPOT_FETCHED_AT”、“PROFILE_LINKEDIN_IS_NOT_FOUND”、“PROFILE_SALES_NAVIGATOR_IS_NOT_FOUND”、“PROFILE_EMAILS”、“PROFILE_PERSONAL_EMAILS”、“PROFILE_PHONES”、“PROFILE_FIRST_” NAME”、“PROFILE_LAST_NAME”、“PROFILE_TEAM”、“PROFILE_HIERARCHY”、“PROFILE_PERSONA” “、”PROFILE_GENDER”、”PROFILE_COUNTRY_CODE”、”PROFILE_SUMMARY”、”PROFILE_INDUSTRY_NAME”、”PROFILE_BIRTH_YEAR”、”PROFILE_MARVIN_SEARCHES”、”PROFILE_POSITION_STARTED_AT”、”PROFILE_POSITION_TITLE”、”PROFILE_POSITION_LOCATION”、”PROFILE_POSITION_DESCRIPTION”、” PROFILE_COMPANY_NAME”, “PROFILE_COMPANY_LINKEDIN_ID”, “PROFILE_COMPANY_LINKEDIN_UNIVERSAL_NAME”、“PROFILE_COMPANY_SALESFORCE_ID”、“PROFILE_COMPANY_SPENDESK_ID”、“PROFILE_COMPANY_HUBSPOT_ID”、“PROFILE_SKILLS”、“PROFILE_LANGUAGES”、“PROFILE_SCHOOLS”、“PROFILE_EXTERNAL_SEARCHES”、“PROFILE_LINKEDIN_HEAD LINE”、”PROFILE_LINKEDIN_LOCATION”、”PROFILE_SALESFORCE_CREATED_AT”、”PROFILE_SALESFORCE_STATUS”、”PROFILE_SALESFORCE_LAST_ACTIVITY_AT ”、“PROFILE_SALESFORCE_OWNER_CONTACT_ID”、“PROFILE_SALESFORCE_OWNER_CONTACT_NAME”、“PROFILE_SPENDESK_SIGNUP_AT”、“PROFILE_SPENDESK_DELETED_AT”、“PROFILE_SPENDESK_ROLES”、“PROFILE_SPENDESK_AVERAGE_NPS_SCORE”、“PROFILE_SPENDESK_NPS_SCORES_COUNT” ”、“PROFILE_SPENDESK_FIRST_NPS_SCORE”、“PROFILE_SPENDESK_LAST_NPS_SCORE”、“PROFILE_SPENDESK_LAST_NPS_SCORE_SENT_AT”、“PROFILE_SPENDESK_PAYMENTS_COUNT”、“PROFILE_SPENDESK_TOTAL_EUR_SPENT”、 “PROFILE_SPENDESK_ACTIVE_SUBSCRIPTIONS_COUNT”、“PROFILE_SPENDESK_LAST_ACTIVITY_AT”、“PROFILE_AUTOPILOT_MAIL_CLICKED_COUNT”、“PROFILE_AUTOPILOT_LAST_MAIL_CLICKED_AT”、“PROFILE_AUTOPILOT_MAIL_OPENED_COUNT”、“PROFILE_AUTOPILOT_LAST_MAIL_OPENED_AT ”、“PROFILE_AUTOPILOT_MAIL_RECEIVED_COUNT”、“PROFILE_AUTOPILOT_LAST_MAIL_RECEIVED_AT”、“PROFILE_AUTOPILOT_MAIL_UNSUBSCRIBED_AT”、“PROFILE_AUTOPILOT_MAIL_REPLIED_AT”、“PROFILE_AUTOPILOT_LISTS”、“PROFILE_AUTOPILOT_SEGMENTS”、“PROFILE_HUBSPOT _CFO_CONNECT_SLACK_MEMBER_STATUS ”、“PROFILE_HUBSPOT_IS_CFO_CONNECT_MEETUPS_MEMBER”、“PROFILE_HUBSPOT_CFO_CONNECT_AREAS_OF_EXPERTISE”、“PROFILE_HUBSPOT_CORPORATE_FINANCE_EXPERIENCE_YEARS_RANGE”
看看其中的一些名字:LinkedIn 显然在那里,但 Salesforce、Spendesk 和 Hubspot 等也在那里。这听起来更像是多个来源的聚合,而不是仅仅从 LinkedIn 抓取的数据。我希望在发布此内容时,有人可能会突然出现并说“我认出那些列标题,它们来自……”谁知道呢。
所以,这就是我们剩下的地方:这些数据是来自公共 LinkedIn 个人资料、伪造的电子邮件地址和部分信息的组合(根据简单的观察数据,这只是一小部分)以及上面列标题中的其他来源。但人是真实的,公司是真实的,域名是真实的,在许多情况下,电子邮件地址本身也是真实的。数据集中有超过 1,800 名 HIBP 订阅者,这些人都进行了双重选择,因此他们过去曾成功收到发送到该地址的电子邮件。此外,当数据加载到 HIBP 中时,系统中已有近一百万个电子邮件地址,因此显然,它们是以前使用过的地址。这是有道理的,因为即使每个地址都是由算法构建的,该模式也足够常见,以至于会出现大量命中。
因为结论是该语料库中存在合法数据的重要组成部分,所以我将其加载到 HIBP 中。但由于其中还有大量伪造的电子邮件地址,我已将其标记为垃圾邮件列表,这意味着如果他们正在监视域,这些地址不会影响任何人的付费订阅规模。虽然我知道有些人会建议根本不应该介入,但当我一次又一次对公众进行类似事件的民意调查时,绝大多数人都说“我们想知道这件事,然后我们会做出决定”。我们自己思考需要采取什么行动”。在这种情况下,即使您在域中发现实际不存在的电子邮件地址,当前在您公司工作或以前在您公司工作的人员仍然将其个人数据转储到该语料库中。这是大多数人仍然想知道的事情。
最后,我今天决定投入大量时间研究这个问题的主要原因之一是我讨厌虚假信息,我讨厌人们利用这些信息来发表完全没有根据的言论。我现在查看我的 Twitter 动态,看到人们因此对 LinkedIn 感到愤怒,指责内部人士因最近的裁员而指责他们对我们的数据处理不当等等。不,这一次不行,证据把我们引向完全不同的地方。
原文: https://www.troyhunt.com/hackers-scrapers-fakers-whats-really-inside-the-latest-linkedin-dataset/