一篇引人入胜的新论文表明,法学硕士可以递归地自我改进。他们可以接受旧版本的训练并不断变得更好。这立即让我想到,“就是这样,这就是人工智能奇点”,那一刻人工智能能够永远自主地自我完善并成为…… (这句话可以有很多种结束方式)
我不认为这是奇点,但如果这个想法得到实施,那么它看起来会很像。稍后会详细介绍。
自我提升
这个想法是:
- 从基线模型开始
- 用它来生成问题和答案
- 使用多数投票来过滤掉不好的答案或低质量的问题
- 在新语料库上进行训练
- 转到2
是的,它永远存在。
这是一个示例,将数字相乘,并且数字逐渐变大。

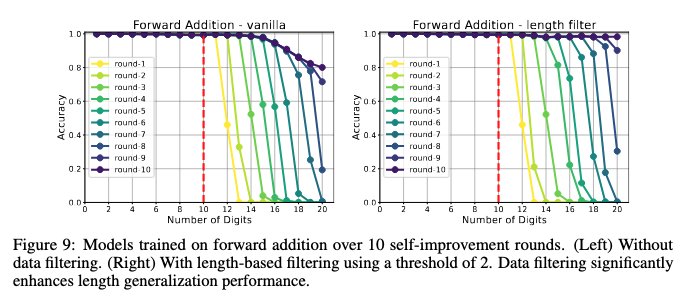
黄线(第 1 轮)表示基本表现。上面的紫色线(第10轮)是未经过滤的盲目训练后的。第 10 轮的悬崖就是模型崩溃的样子。他们称之为错误雪崩。
但表现不会立即下降,在下降之前的几个回合中它仍然保持完美。这是关键的见解。如果您生成稍微困难一点的问题,那么您可以轻松过滤并继续进一步提高性能。
当单个LLM评估正确性时,出错的概率有些高。但通过多数投票,当你增加选民时,概率就会下降到零。在某些时候,它足够低,使其成为一种具有成本效益的策略。
(不,他们没有澄清需要多少选民)
局限性
好吧,这有什么不能做的呢?
这些问题必须具有渐进的性质。例如,他们将越来越大的数字相乘,或者调整迷宫的路径,使它们稍微复杂一些。如果你不能分解问题,它们很可能无法解决这个问题。
另外,问题必须有明确的答案。或者至少,选民应该能够明确地对答案的正确性进行投票。
因此,这可能不适用于创意写作,因为故事没有明显的正确或错误。即使是这样,要让故事变得稍微复杂一点也不容易。
房间里的另一头大象——成本。回想一下,R1在 RL 训练期间竭尽全力避免使用外部 LLM,主要是为了控制成本。但还要记住,公司正在扩展到超大型数据中心。这个成本肯定已经算进去了。
基准饱和度
据我所知,大多数基准测试都符合这些限制,因此将会饱和。它们通常是清晰且明确正确的,否则这些问题就不能用作基准。我的感觉是,它们通常是可分解的问题,可以通过调整使其变得稍微复杂一些。
如果这种递归改进成为现实,我想大多数基准测试将很快饱和。饱和基准与没有基准一样好。
这看起来像是疯狂的进步,但我不认为这是奇点。这篇论文根本没有谈论紧急行为。事实上,它假设一种行为已经出现,以便引导该过程。但一旦它出现,这个过程就能最大限度地发挥它的潜力。
看起来代理可能是一个很容易找到适合这种模式的问题的地方。问题在于创建基准的速度不够快。
我的预感是,展望未来,我们将依靠强化学习(RL)来迫使行为出现,然后使用某种形式的递归自我改进微调来最大限度地发挥这种行为。
今年真是越来越狂野了..
原文: http://timkellogg.me/blog/2025/02/12/recursive-improvement