如何设计一个可投入生产的人工智能系统,以最大限度地提高每一美元的效益?如何管理和减少依赖锁定?此外,如何区分计算、网络和存储之间的问题?在本次演讲中,我将涵盖所有这些内容,并向您展示如何设计一个具有生产价值的人工智能设置,让您可以在提供商之间游移,尽可能轻松地寻找交易。
视频
https://cdn.xeiaso.net/file/christine-static/talks/2025/nomadic-compute/index.m3u8
成绩单
这是口语。它不像我写博客文章那样写。为了您的方便,将其转载于此。
 演讲的标题幻灯片。它显示演讲者姓名和标题。
演讲的标题幻灯片。它显示演讲者姓名和标题。
大家好,我是小泽。我在 Tigris Data 工作,我将讨论针对人工智能工作负载的游牧基础设施设计的概念。
 这不是产品演示。
这不是产品演示。
但免责声明,这不是产品演示。
(观众欢呼)
我想这就是思想领导力,这是一种产品。
 工作负载的三个部分:计算、网络和存储。
工作负载的三个部分:计算、网络和存储。
工作负载由三个基本部分组成。计算、网络和存储。计算是进行数字运算或线性代数的部分。网络将我们所有的计算机连接在一起。这就是为什么我们必须每五飞秒更新一次所有内容。而存储就是记住下次的事情。
这是您随着时间的推移而计费的。
当我一直在与新的供应商打交道并试图找到廉价的黑客手段让我的人工智能产品以低得离谱的价格运行时,我发现了一件非常奇怪的事情。
 计算时间比存储时间便宜。
计算时间比存储时间便宜。
计算时间比存储时间便宜。
我不知道为什么会这样。有了Vast.ai、RunPod,所有这些竞标收购的GPU市场;花时间下载东西比存储它们以备下次运行要便宜。
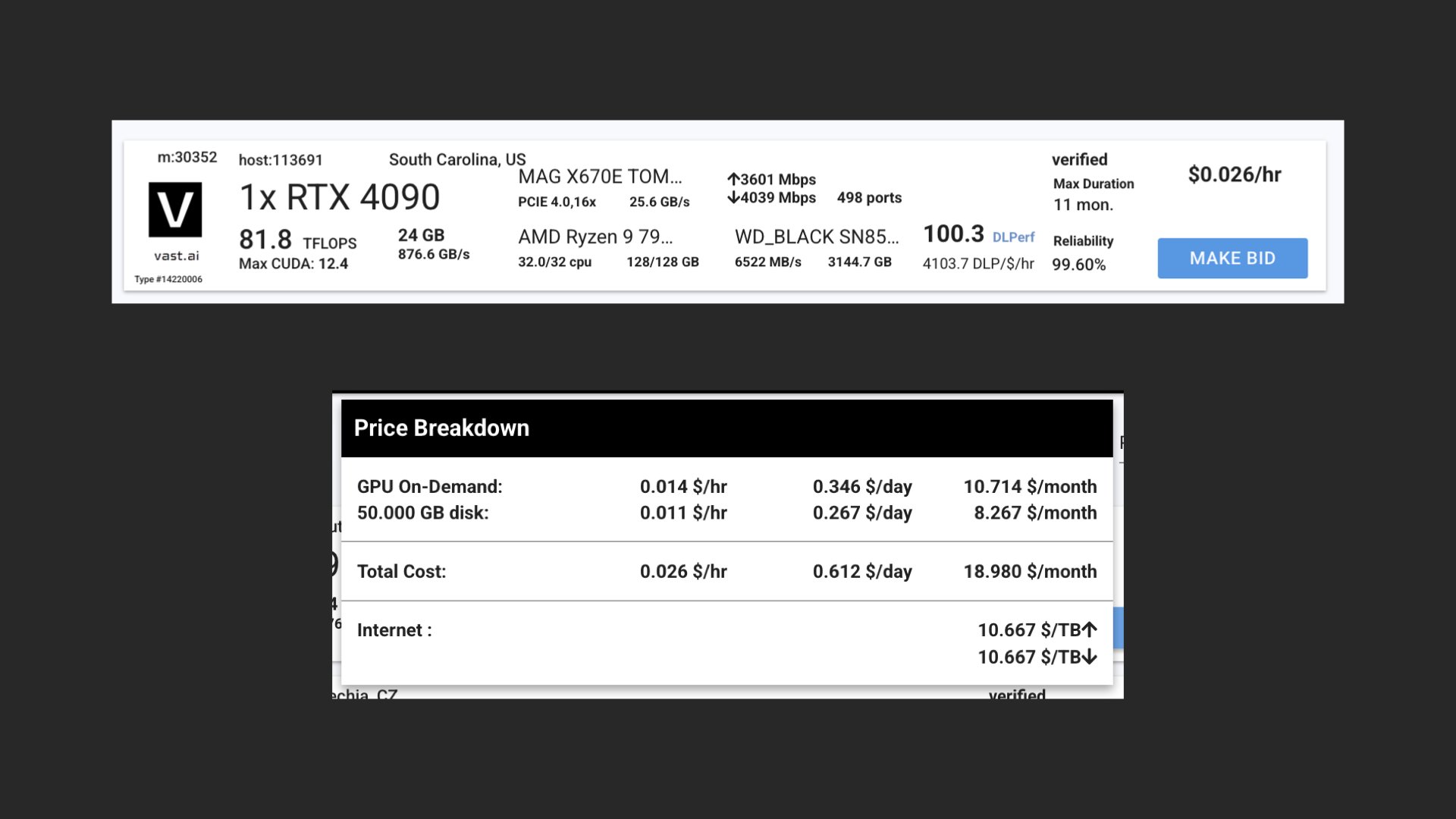 南卡罗来纳州随机 4090 的定价详细信息。
南卡罗来纳州随机 4090 的定价详细信息。
就像,看看这个。我随机选择了南卡罗来纳州的 40.90 美元。使用 50 GB 本地存储运行每小时花费两美分。保存这些数据的费用是每小时一美分。这是实例价格的一半。当然,可能有一些……创造性的财务决策会影响到这样的定价。
但如果启动需要 30 秒,并且每小时花费 2 美分,那么存储东西的成本比不存储东西的成本更高。想想真是奇怪的事情。
 如何在基础设施设计中作弊。
如何在基础设施设计中作弊。
因此,让我们学习如何欺骗基础设施设计,并找出为什么我不再被允许成为 SRE。星号。
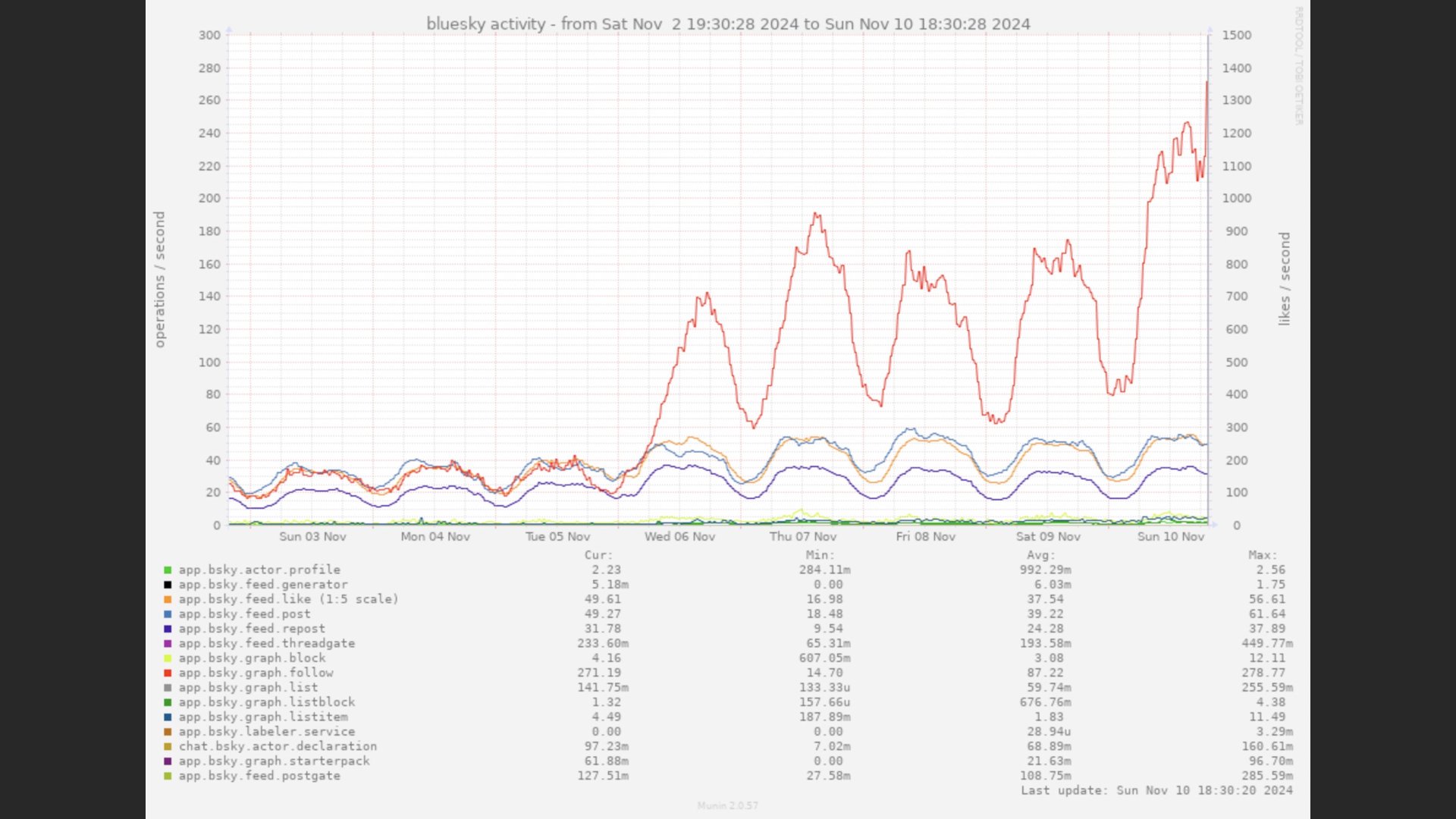 Bluesky 用户活动图表。
Bluesky 用户活动图表。
因此,您可以做的第一件事就是扩展到零,因为人们在睡觉时不会使用工作负载。这张图有一个正弦波,来自去年年底爆炸时的蓝天。美国白天中间有一个高峰,然后当美国人入睡时,一切都会降到非常低的水平。
如果您曾经从事过 SRE 相关工作,您就会经常看到这种情况。这就是您的请求率。这就是您的活跃用户帐户的样子。这就是健康产品的样子。因此,如果您在无人使用时关闭服务,那么每天就可以节省 12 小时的运行时间。
 一个绿发动漫女人自焚金钱并大笑。
一个绿发动漫女人自焚金钱并大笑。
就像,记住,这可能不是你的钱,但现在钱很贵。免费套餐即将结束。在某些时候,炒作将会消失,计算价格将反映购买硬件的价格。
您的 AI 工作负载是依赖项。如果没有这些工作负载,你的产品就注定失败。那些控制基础设施香料、控制基础设施宇宙或弗兰克·赫伯特在《沙丘》中所说的任何人。
权衡
 权衡。
权衡。
所以当你作弊时,一切都是为了做出权衡。有几个因素需要考虑,但在我看来,最重要的因素是时间,因为这就是你的计费标准。
 AI 工作负载冷启动所涉及的步骤列表。
AI 工作负载冷启动所涉及的步骤列表。
具体来说,冷启动时间或从服务未运行到服务运行所需的时间。以下是在某处某个云提供商上运行工作负载所涉及的所有步骤的示例。
据统计,Docker 是互联网通用的包格式。它将位于必须提取的 Docker 映像中,视频内容就像 GB 的随机 C++ 库和一大堆您没有的 GPU 字节码,但无论如何都必须发送,因为谁知道呢,您可能会在 2060 上运行它。
它被拉动、提取,然后就开始了。您的应用程序启动后意识到,“哦,我没有任何模型。我需要将它们拉下来。”
然后,从拉取模型到加载模型所需的时间就是您没有做任何有用的事情的时间。但是,一旦到达模型加载的阶段,您就可以推断它们,做任何事情并以某种方式获利。但推理模型步骤之上的所有内容实际上都是浪费时间。
根据您使用的平台,这可能会导致您无所事事而花钱。
 完全正常的刺猬索尼克绘画。
完全正常的刺猬索尼克绘画。
我们怎样才能让它快点呢?我们如何才能提高我们的基础设施 Sanic 的速度?用户并不关心你是否想便宜。他们关心响应能力。有两种方法可以解决这个问题,而且都是不同的作弊方式。
 批量操作。
批量操作。
作弊的最大方法之一就是让你的工作量定期发生,这样你就可以一起做一大堆事情。这称为批处理操作。这就是美国金融体系的运作方式。这是一件可怕的事情。你把所有的事情分成大批量,每 6、12、24 小时做一次,无论时间父亲告诉你应该做什么。
这太棒了。假设您有一个每日壁纸应用程序,并且出于某种原因您希望拥有 AI 生成的每张壁纸。据统计,如果有当天的壁纸,您不需要每天运行它超过一次。所以你可以让它执行 cron 作业,启动它,生成壁纸,将其存储到某个地方。在通过一些基本过滤后,将其标记为已准备好投入使用。鲍勃是你叔叔,你很好。
这使您可以使用您希望拥有字节数的任何模型以低廉的价格运行应用程序中最昂贵的部分。这样您就不能让上游基础设施提供商说:“哦,我们将关闭您正在使用的模型。祝您好运!”
 加快下载速度。
加快下载速度。
但另一种作弊方法是加快冷启动过程。让我们再看一下该列表。
 冷启动操作列表的另一个副本。
冷启动操作列表的另一个副本。
拉取模型是最慢的部分,因为这通常是由 Python 程序完成的,而 Python 在《纪元 2025》中仍然是单线程的。您的应用程序必须坐在那里什么也不做,等待模型拉动并准备就绪。如果您不走运,这可能需要几分钟;如果您真的不走运,则可能需要数十分钟。
如果您可以在不向您收费的阶段进行作弊,该怎么办?您可以将其与运行时一起放入 Docker 映像中,对吧?所以我就这样做了,令我恐惧的是,它的效果还不错。
类似的问题还有很多。
 Docker 讨厌这个
Docker 讨厌这个
第一,Docker 讨厌这个。 Docker 绝对鄙视这一点,因为 Docker 的工作方式就是一堆穿着风衣的焦油球,对吗?为了拉取 Docker 映像,您必须提取所有 tar 球。它一次只能提取一个焦油球,因为焦油球很奇怪。
如果您有 Flux 开发人员,那就像一个 120 亿个参数模型。所以我们谈论的是 26 GB 的浮点数,包括模型、自动编码器和它所拥有的任何其他东西。
但这不是你必须付费的时候,而是用户可能会注意到的时候。但我们在作弊,所以你可以只进行批量操作。
如果你无论如何都想这样做,这是我学到的一个技巧:
模型权重不会经常变化。因此,您可以制作一个包含所有模型权重的单独 Docker 映像,然后将这些模型权重链接到运行时映像中。
FROM anu-registry.fly.dev/models/waifuwave AS models FROM anu-registry.fly.dev/runners/comfyui:latest COPY --link --from=models /opt/comfyui/models/checkpoints /opt/comfyui/models/checkpoints COPY --link --from=models /opt/comfyui/models/embeddings /opt/comfyui/models/embeddings COPY --link --from=models /opt/comfyui/models/loras /opt/comfyui/models/loras COPY --link --from=models /opt/comfyui/models/vae /opt/comfyui/models/vae
这有效。我很害怕。
您可以在这之间重用这些模型,因为如果您有一个基础稳定扩散检查点并且每个 LoRA 位于单独的层中,则默认情况下您可以让它们出现在图像中。如果您需要下载单独的 LoRa,您可以在运行时执行此操作,并且只需下载 150 兆而不是 5 兆。这样就快多了。
您还可以在项目或工作负载之间重用它们,这可能更可取,具体取决于您正在做什么。
 Docker Hub 讨厌这个
Docker Hub 讨厌这个
当你这样做时还有一个大问题,Docker Hub 不允许这样做。它的最大层大小约为 10 GB,最大图像大小为 10 GB。我使用 2023 年稳定扩散 1.5 进行的测试是一张 11 GB 的图像。
GitHub 的容器注册表几乎不能容忍它。我必须使用自己的注册表。这并不难。注册管理机构基本上是资产翻转 S3,而我工作的公司基本上就是 S3。所以这很容易做到,我可以在演讲后告诉你如何做。我有贴纸。
 这样做的好处
这样做的好处
但是,进行这种可怕的犯罪行为的最大好处是,您的一个部署工件同时具有您的应用程序代码和您的权重。在你让你的模型从拥抱脸或 Civitai 中移除之前,这听起来并不是一个很大的优势。然后您会遇到无法轻松解决的生产事件,因为没有人缓存模型。
问我怎么知道的。
 他们两个模因被编辑为“其中之一”
他们两个模因被编辑为“其中之一”
而且因为只有其中之一,所以您无需处理多个工件。您不必喜欢有额外的逻辑来下载权重。令人惊奇的是,当您不需要编写代码时,您不必编写多少代码。
 Nomadic Compute 封面图片显示机器人正在搜寻交易
Nomadic Compute 封面图片显示机器人正在搜寻交易
但这是游牧计算设置的关键思想。你的工作量附带了它所需要的一切,这样它就可以快速启动,出去寻找它能做的任何交易,完成工作,然后回到洞穴睡觉或做其他事情。这个比喻崩溃了。对不起。
您也不需要受制于任何云提供商,因为如果您可以执行 AMD 64 字节代码并且您有 Nvidia GPU 并且有 CUDA 的现代版本,那么这并不重要。其他一切都是可替代的。您真正被锁定的唯一方法是如果您使用本地存储并记住我们正在努力省钱。所以我们不是。
所以你可以使用像Skypilot这样的工具。它就是有效的。
 现场演示
现场演示
好吧,那我们就来试探上帝吧。
我非常擅长网页设计,所以这是一个 HTML 1.0 表单。我的演示是页面上的一个按钮,如果单击该按钮,您会看到动漫女性:
 使用 Counterfeit v3.0 制作的棕色头发动漫女性仰望天空的侧面照片
使用 Counterfeit v3.0 制作的棕色头发动漫女性仰望天空的侧面照片
看,这是由 GPU 产生的幻觉,它按需旋转,当我们完成后它就会关闭。我很高兴这有效。
 特别鸣谢名单
特别鸣谢名单
特别感谢所有这些人。如果你在这个名单上,你就知道你做了什么。如果你不这样做,你就知道你没有做什么。
 最后一张幻灯片包含 Xe 的联系信息
最后一张幻灯片包含 Xe 的联系信息
至此,我就成为了Xe。如果您有任何疑问,请询问。我不咬人。