在其云数据峰会上,谷歌今天宣布推出 BigLake 的预览版,这是一种新的数据湖存储引擎,可让企业更轻松地分析其数据仓库和数据湖中的数据。
其核心理念是利用 Google 在运行和管理其 BigQuery 数据仓库方面的经验,并将其扩展到 Google Cloud Storage 上的数据湖,将最好的数据湖和仓库结合到一个服务中,从而抽象出底层存储格式和系统。
值得注意的是,这些数据可以存在于 BigQuery 中,也可以存在于 AWS S3 和 Azure Data Lake Storage Gen2中。通过 BigLake,开发人员可以访问一个统一的存储引擎,并能够通过单个系统查询底层数据存储,而无需移动或复制数据。
“跨不同的湖泊和仓库管理数据会产生孤岛并增加风险和成本,尤其是在需要移动数据时,”谷歌云数据库、数据分析和商业智能副总裁兼总经理 Gerrit Kazmaier在今天的公告中解释道。 “ BigLake 允许公司统一他们的数据仓库和湖泊来分析数据,而无需担心底层存储格式或系统,这消除了从源复制或移动数据的需要,并降低了成本和效率低下。”
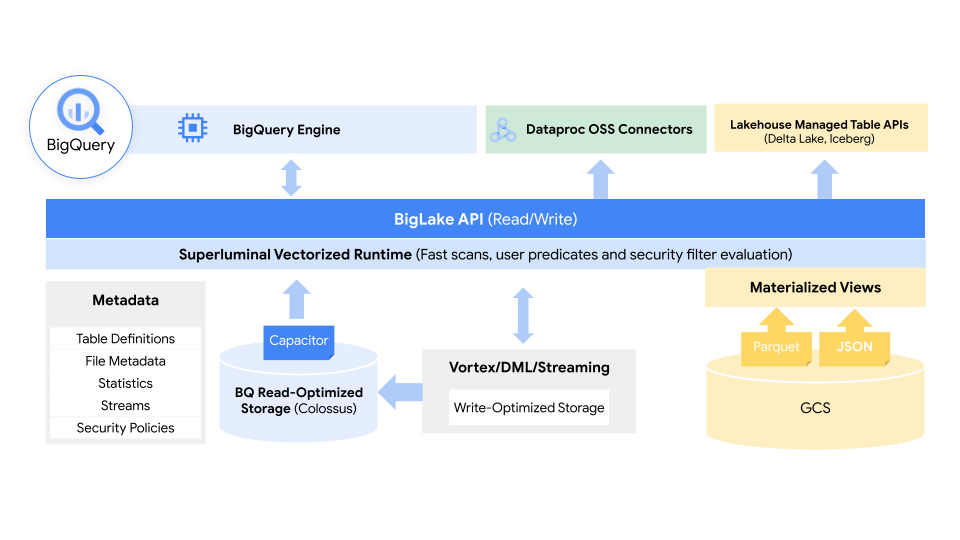
图片来源:谷歌
使用策略标签,BigLake 允许管理员在表、行和列级别配置他们的安全策略。这包括存储在 Google Cloud Storage 以及两个受支持的第三方系统中的数据,其中 Google 的多云分析服务BigQuery Omni支持这些安全控制。这些安全控制还确保只有正确的数据流入 Spark、Presto、Trino 和 TensorFlow 等工具。该服务还与 Google 的Dataplex工具集成以提供额外的数据管理功能。
谷歌指出,BigLake 将提供细粒度的访问控制,其 API 将跨越谷歌云,以及面向开放列的 Apache Parquet等文件格式和 Apache Spark 等开源处理引擎。
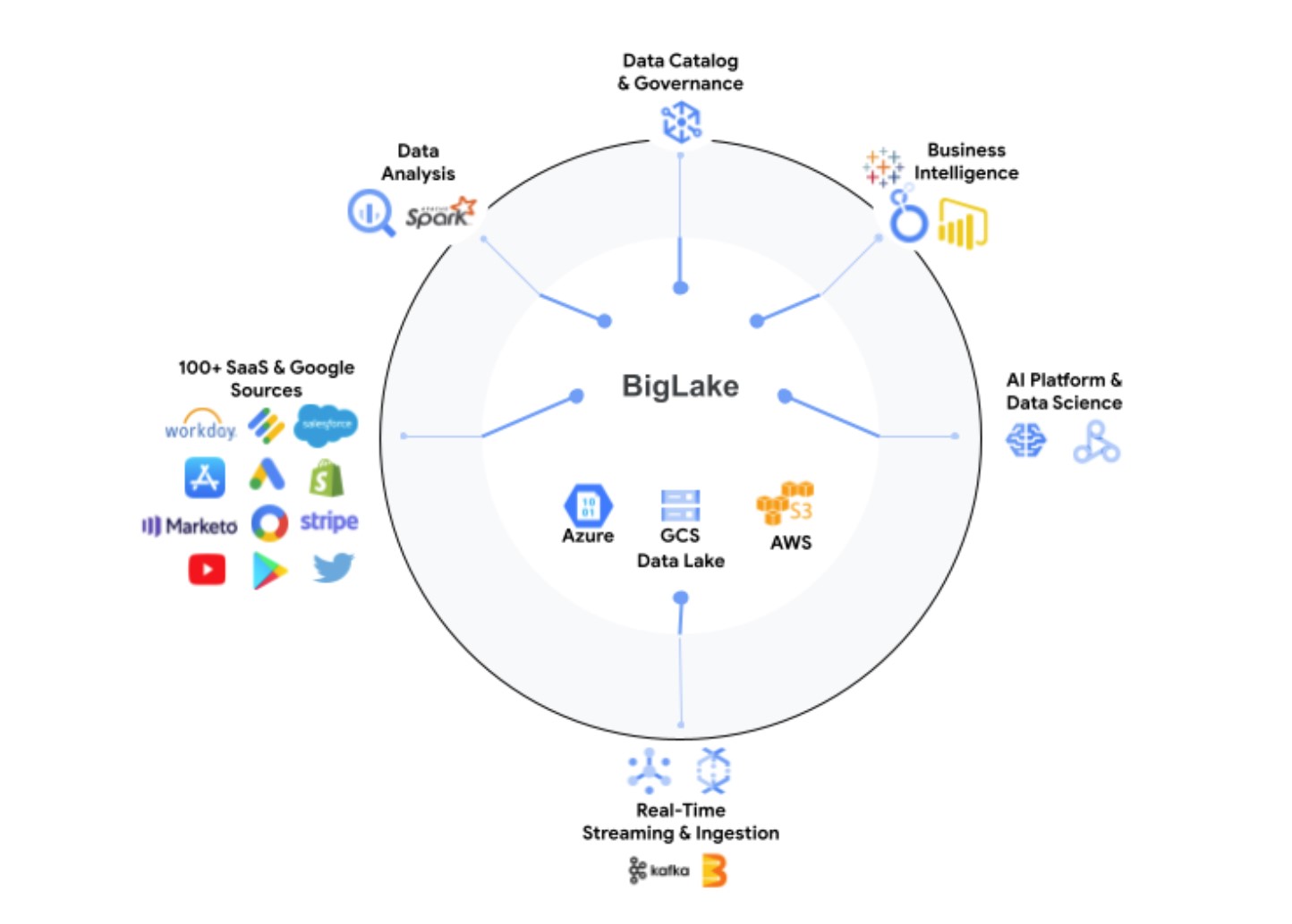
图片来源:谷歌
“组织必须管理和分析的宝贵数据量正以惊人的速度增长,”谷歌云软件工程师 Justin Levandoski 和产品经理 Gaurav Saxena 在今天的公告中解释道。 “这些数据越来越多地分布在许多地方,包括数据仓库、数据湖和 NoSQL 存储。随着组织的数据变得越来越复杂并在不同的数据环境中激增,孤岛出现了,从而增加了风险和成本,尤其是在需要移动数据时。我们的客户已经说得很清楚了;他们需要帮助。”
除了 BigLake,谷歌今天还宣布,其全球分布式 SQL 数据库Spanner将很快获得一项名为“更改流”的新功能。有了这些,用户可以轻松地实时跟踪对数据库的任何更改,无论是插入、更新还是删除。 “这确保客户始终可以访问最新数据,因为他们可以轻松地将更改从 Spanner 复制到 BigQuery 以进行实时分析,使用 Pub/Sub 触发下游应用程序行为,或将更改存储在 Google Cloud Storage (GCS) 中以实现合规性,”卡兹迈尔解释道。
谷歌云今天还推出了Vertex AI Workbench ,这是一种用于管理数据科学项目整个生命周期的工具,已完成测试版并进入普遍可用状态,并推出了适用于 Looker 的 Connected Sheets,以及在其 Data 中访问 Looker 数据模型的能力Studio BI 工具。