
你是否曾经让你的人工智能编码助理提出过一些离谱的建议,以至于你怀疑它是否在欺骗你?欢迎来到自回归失败的世界。
法学硕士是这些助手背后的大脑,他们非常擅长根据输入的内容预测下一个单词或下一行代码。但是,当上下文变得过于复杂或上下文中的关注点混合在一起时,他们就会失去线索并陷入可笑(或令人沮丧)的错误领域。让我们深入探讨为什么会发生这种情况以及如何阻止它发生。
首先,我需要您阅读以下博客文章,从基本原则来了解代理。

什么是代理:用不到 400 行代码解释
还在读书吗?伟大的。在下图中,代理已配置了两个工具。每个工具还配置了工具提示,向LLM宣传如何使用该工具。
这些工具是:
- 工具 1 – 访问网站并提取页面内容。
- 工具 2 – 执行 Google 搜索并返回搜索结果。
现在,想象一下该代理是一个交互式控制台应用程序,您可以使用它来搜索 Google 或访问 URL。
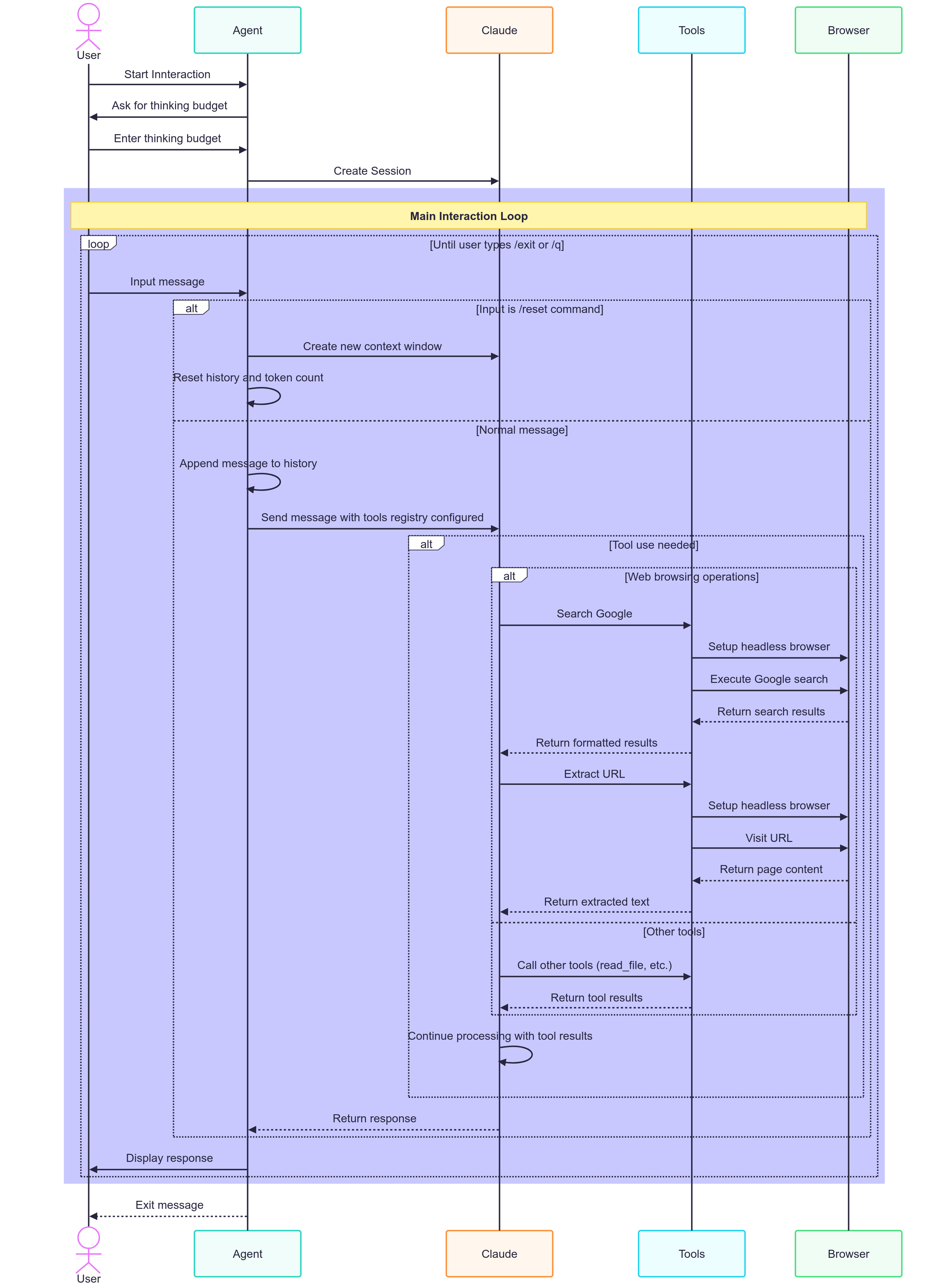
使用代理时,您执行以下操作:
- 访问新闻网站。
- 在 Google 上搜索派对帽。
- 访问有关猫鼬的维基百科文章。
每个操作都会将上述操作的结果分配到内存中 – LLM 上下文窗口。
 当数据被
当数据被malloc()插入 LLM 的上下文窗口时。除非您创建一个全新的上下文窗口,否则它不能被free() 。
将所有上下文加载到窗口中后,现在当您提出问题时,所有数据都可供考虑。因此,它有可能会生成一篇关于猫鼬戴着派对帽子的新闻文章,以响应对猫鼬事实的搜索(即维基百科)。
这听起来似乎很明显,但事实并非如此。大多数软件开发人员日常使用的工具都会向用户隐藏上下文窗口,并鼓励在同一上下文窗口内进行无休止的chatops 会话,即使当前任务与前一个任务无关。
这会产生不好的结果,因为加载到内存中的内容与要完成的工作无关,并导致软件工程师发出噪音说“人工智能不起作用”,但实际上,问题在于软件工程师持有/使用工具的方式。
我现在对人们的第一条建议是对一项任务使用上下文窗口,并且仅对一项任务使用。如果您的编码代理行为不当,则需要创建一个新的上下文窗口。如果保龄球掉进了排水沟,就没有办法挽救它了。它在阴沟里。
我的第二条建议是不要对上下文窗口进行红线标注(见下文)

附注社交
- X – https://x.com/GeoffreyHuntley/status/1914350677331231191
- 蓝天 – https://bsky.app/profile/ghuntley.com/post/3lndk65i7fu25
- LinkedIn – https://www.linkedin.com/posts/geoffreyhuntley_autoregressive-queens-of-failure-activity-7320115355262074881-FfPI
注册杰弗里·亨特利
我在一辆在澳大利亚缓慢行驶的货车上远程工作。跟随我了解远程工作、露营和#vanlife 的交叉点。
没有垃圾邮件。随时取消订阅。