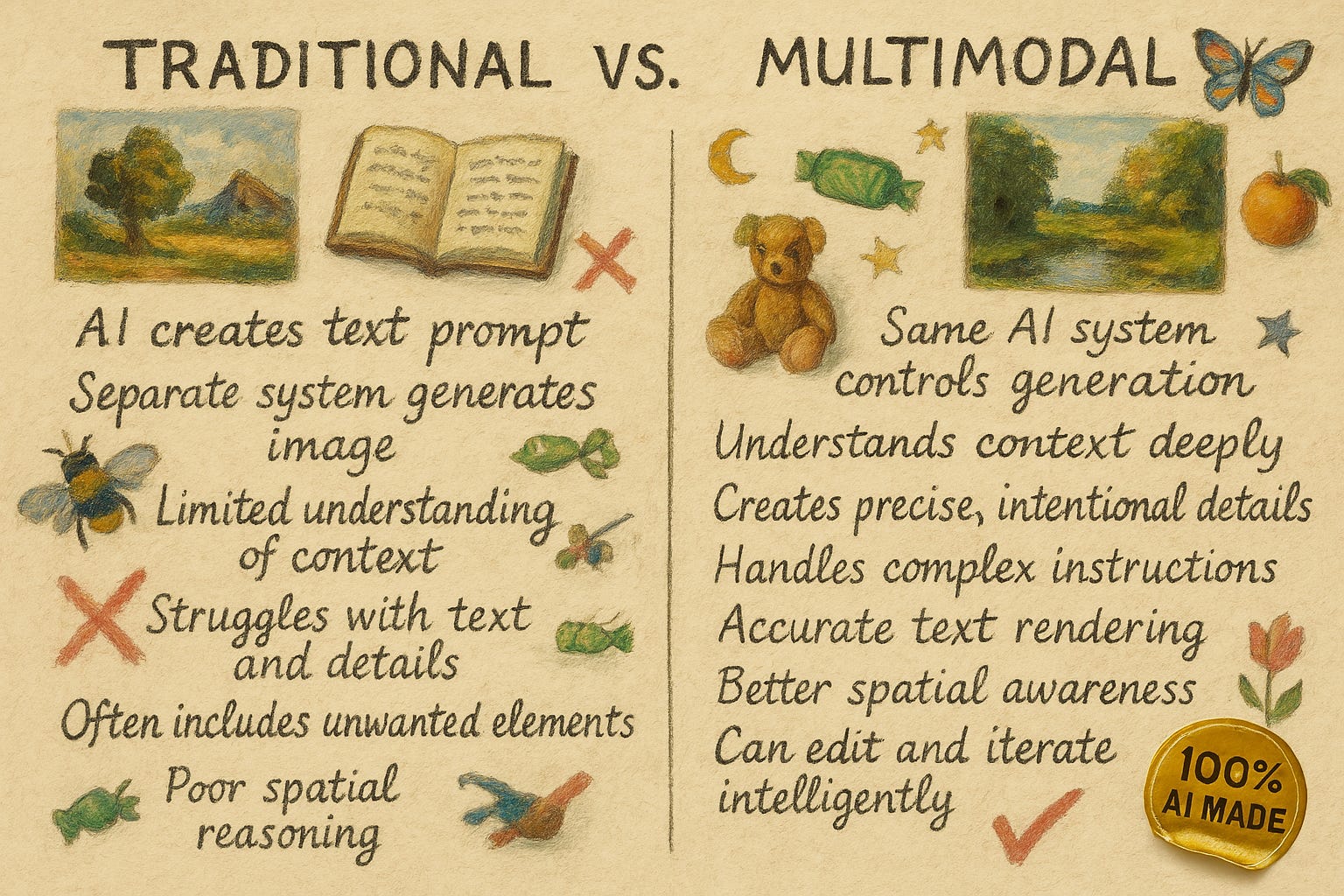
在过去的两周里,谷歌和 OpenAI 首先推出了他们的多模态图像生成功能。这是一件大事。以前,当大型语言模型人工智能生成图像时,并不是真正的法学硕士在做这项工作。相反,人工智能会向单独的图像生成工具发送文本提示,并向您显示返回的内容。人工智能创建文本提示,但另一个不太智能的系统创建图像。例如,如果提示“向我展示一个没有大象的房间,请确保对图像进行注释以向我展示为什么不可能有大象”,不太智能的图像生成系统会多次看到“大象”一词并将它们添加到图片中。结果,AI 图像生成相当平庸,文本扭曲,元素随机;有时很有趣,但很少有用。
另一方面,多模态图像生成让人工智能直接控制正在生成的图像。虽然有很多变化(而且公司对一些方法保密),但在多模式图像生成中,图像的创建方式与法学硕士创建文本(一次一个令牌)的方式相同。人工智能不是添加单独的单词来造句,而是将图像分成单独的部分,一个接一个地组合成一幅完整的图片。这让人工智能能够创造出更加令人印象深刻、更加精确的图像。不仅保证不会出现大象,而且这个图像创作过程的最终结果体现了LLM“思维”的智慧,以及清晰的文字和精确的控制。

Microsoft Copilot 的传统图像生成器(左)和 GPT-4o 的多模态模型(右)中提示“向我显示一个没有大象的房间,请确保对图像进行注释以向我显示为什么不可能有大象”的结果。请注意,传统模型不仅显示多头大象,而且还具有扭曲的文本。
虽然这些新图像模型的影响是巨大的(稍后我将讨论一些问题),但让我们首先通过一些示例来探索这些系统实际上可以做什么。
提示,但对于图像
在我的书中和许多帖子中,我谈到了促进人工智能的一种有用方法是像人一样对待它,即使它不是。给出明确的方向、迭代时的反馈以及做出决策的适当背景都有助于人类,也有助于人工智能。以前,这只能对文本执行,但现在您也可以对图像执行此操作。
例如,我提示 GPT-4o“创建一个关于如何构建优秀棋盘游戏的信息图。”对于以前的图像生成器,这会导致无意义的结果,因为没有智能来指导图像生成,因此文字和图像会被扭曲。现在,我第一次就取得了良好的成绩。然而,我没有提供有关我正在寻找的内容或任何其他内容的背景信息,因此人工智能做出了所有创造性的选择。如果我想改变怎么办?我们来试试吧。
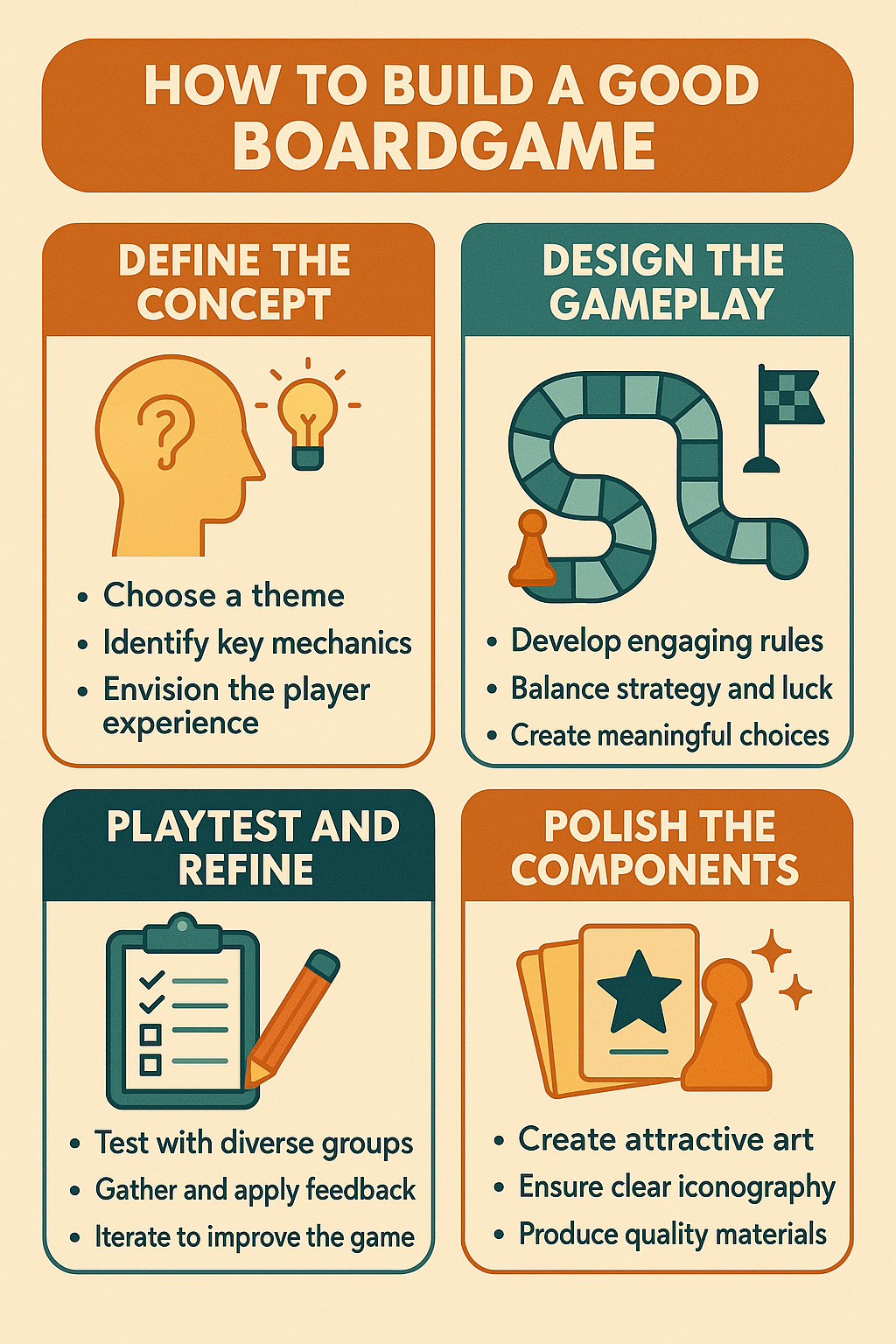
首先,我要求它“让图形看起来超现实” ,你可以看到它如何从最初的草稿中提取概念并更新它们的外观。我想要进行更多更改: “我希望颜色少一些大地色,而更像有纹理的金属,保持其他一切不变,还要确保小项目符号文本更浅,这样更容易阅读。”我喜欢新的外观,但我注意到引入了一个错误,“Define”一词变成了“Definc”——这表明这些系统虽然很好,但尚未接近完美。我提示“您将 Define 拼写为 Definc,请修复”并得到了合理的输出。

但这些模型的迷人之处在于,它们几乎能够生成任何图像:“将这张信息图放在站在火山前的水獭手中,它应该看起来像一张照片,就像水獭拿着这张雕刻在金属板上的照片”

为什么停在那里? “现在是晚上,手电筒直接照射在平板电脑的中心(无需显示手电筒) ”——结果比看起来更令人印象深刻,因为它在没有任何底层照明模型的情况下重新进行了照明。 “制作一个水獭的动作人偶,并配有包装,将棋盘游戏作为侧面的配件之一。将其称为“游戏设计水獭”,并给它一些其他配件。” “使用笔记本电脑在飞机上制作水獭,他们在一个名为 OtterExpress 的网站上购买了 Game Design Otter 的副本。”令人印象深刻,但不太正确:“修复键盘,使其更加逼真,并移除他拿着的水獭动作玩偶。 ”

正如您所看到的,这些系统并非完美无缺……但还要记住,下面的图片是两年半前提示“水獭在飞机上使用 wifi”的结果。最先进的技术正在迅速发展。

但它有什么用呢?
过去几年我们一直在努力找出文本人工智能模型的优势,并且不断开发新的用例。基于图像的法学硕士也是如此。图像生成可能会以我们目前无法理解的方式产生巨大的破坏性。尤其如此,因为您可以上传法学硕士现在可以直接查看和操作的图像。一些示例,全部使用 GPT-4o 完成(尽管您也可以在 Google 的Gemini Flash中上传和创建图像):
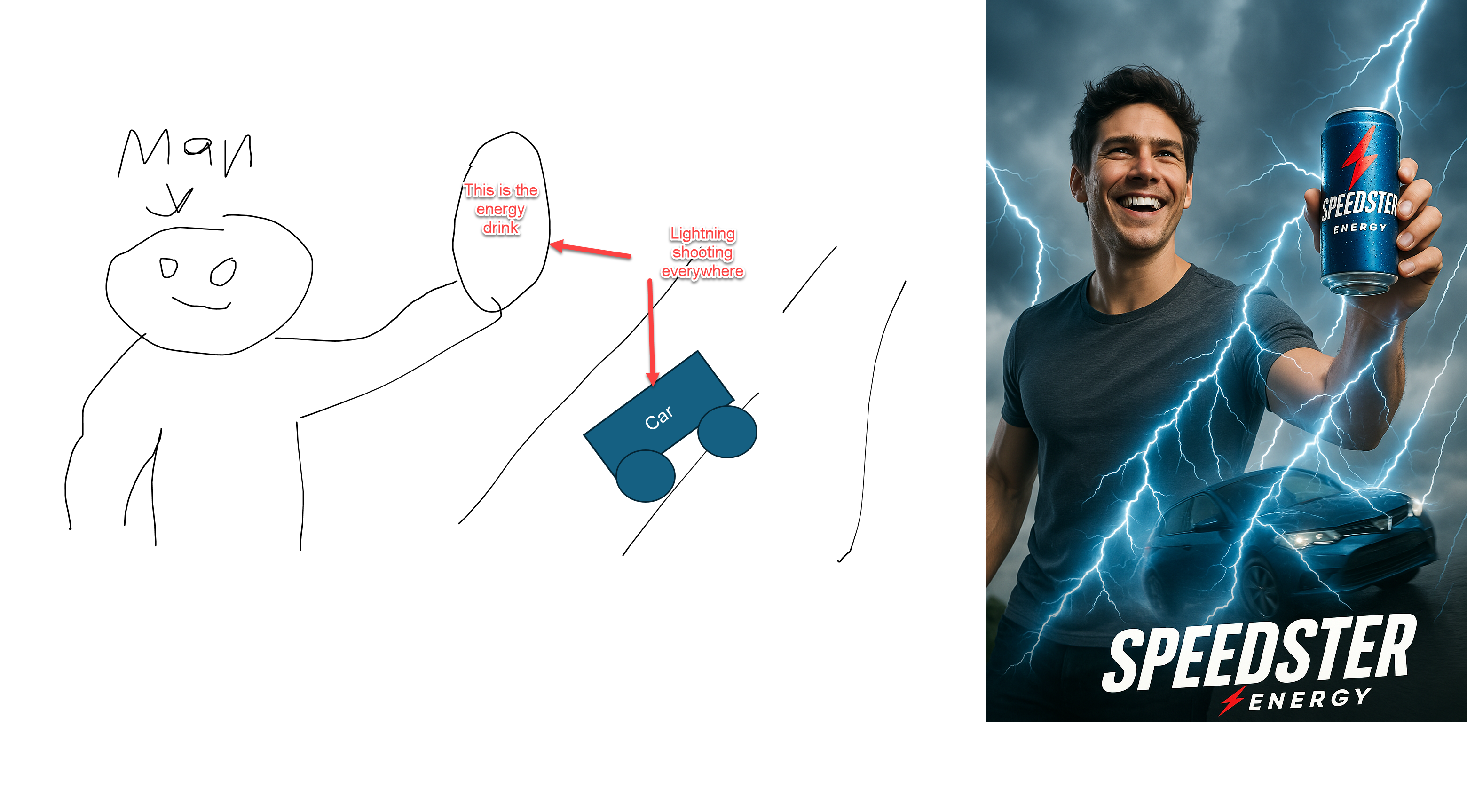
我可以拍一张手绘图像,然后要求人工智能“将此作为 Speedster 能量饮料的广告,确保包装和徽标很棒,这应该看起来像一张照片。 ”(这需要两次提示,第一次是在标签上拼错了 Speedster)。结果虽然不如专业设计师所能创造的那么好,但仍然是令人印象深刻的第一个原型。
我可以给 GPT-4o 两张照片,并提示“你能把图像中的咖啡桌和蓝色沙发换成白色沙发吗? ”(注意新的玻璃桌面如何显示图像中原始图像中不存在的部分。另一方面,被交换的桌子并不完全相同)。我又问:“你能让地毯不那么褪色吗?”同样,有几个细节并不完美,但这种用简单英语进行图像编辑以前是不可能的。

或者,我可以为我出色的创业想法创建一个即时网站模型、广告概念和宣传材料,其中无人机根据需要向您提供鳄梨酱(我确信它会很受欢迎)。您可以看到,这还不能替代人类设计师的见解,但它仍然是一个非常有用的第一个原型。
除此之外,我和其他人还发现了许多其他用途,包括:视觉食谱、主页、视频游戏纹理、插图诗歌、精神错乱的独白、照片改进和视觉冒险游戏,仅举几例。
复杂性
如果您一直在关注有关这些新图像生成器的在线讨论,您可能会注意到,我还没有展示它们最热门的用途 – 进行风格转换,即人们要求人工智能将照片转换为看起来像是为辛普森一家或吉卜力工作室制作的图像。这类应用凸显了将人工智能用于艺术的所有复杂性:是否可以使用人工智能重现其他艺术家来之不易的风格?谁拥有由此产生的艺术品?谁从中获利?人工智能的训练数据中有哪些艺术家,使用受版权保护的作品进行训练的法律和道德地位如何?这些在多模式人工智能之前是重要的问题,但现在寻找这些问题的答案变得越来越紧迫。此外,当然,多模式人工智能还存在许多其他潜在风险。至少一年来,制作 Deepfakes 一直很简单,但多模式人工智能让它变得更容易,包括增加创建各种其他视觉错觉的能力,比如假收据。我们还不了解多模式人工智能可能会给图像生成带来哪些偏见或其他问题。
但很明显,文本发生的情况也会发生在图像上,最终也会发生在视频和 3D 环境上。这些多模式系统正在重塑视觉创作的格局,提供强大的新功能,同时提出有关创意所有权和真实性的合理问题。人类和人工智能创作之间的界限将继续模糊,促使我们重新考虑在一个任何人都可以通过一些提示生成复杂视觉效果的世界中什么是原创性。一些创意职业将会适应;有些可能没有改变,还有一些可能会完全改变。与任何重大技术变革一样,我们需要经过深思熟虑的框架来应对未来复杂的地形。问题不在于这些工具是否会改变视觉媒体,而在于我们是否会足够深思熟虑,有意识地塑造这种变化。
{kind=link}
原文: https://www.oneusefulthing.org/p/no-elephants-breakthroughs-in-image