我已经发布了 Datasette 1.0 的第三个 alpha。 1.0a2 版本引入了对新 JSON API 的更新插入支持,并对 Datasette 权限系统进行了一些重大改进。
以下是带注释的版本(见上文)。
您可以使用以下方法安装和试用 alpha:
pip install datasette==1.0a2
JSON API 的更新
新的
/db/table/-/upsertAPI,在此处记录。 Upsert 是一种更新或插入:现有行将更新指定的键,但如果没有行与传入的主键匹配,则会插入一个全新的行。 ( #1878 )
几周前发布第一个 alpha 版时,我写了关于新的 JSON Write API的文章。
API 可用于创建和删除表,以及插入、更新和删除这些表中的行。
新的/db/table/-/upsert API 添加了对数据集的更新插入支持。
upsert是更新或插入。考虑以下:
POST /books/authors/-/upsert Authorization: Bearer $TOKEN Content-Type: application/json
{ “行” :[ { “编号” : 1 , “姓名” : “厄休拉·勒金” , “出生” : “ 1929-10-21 ” }, { “编号” : 2 , “名字” : “特里普拉切特” , “出生” : “ 1948-04-28 ” }, { “编号” : 3 , “名字” : “尼尔·盖曼” , “出生” : “ 1960-11-10 ” } ] }
该表的主键为id 。如果表为空,上述 API 调用将创建三个记录。但是,如果该表已经有与这些主键中的任何一个相匹配的记录,它们的name和born列将被更新以匹配传入的数据。
Upserts 是一种与外部数据源同步数据的非常方便的方法。当我发布第一个 alpha 时,我对它们有一些询问,所以我决定将它们作为这个版本的一个关键特性。
忽略并替换创建表 API
此功能不太明显,但我认为它会非常有用。
/db/-/create API 可用于创建新表。您可以为它提供一个明确的列列表,但您也可以给它一个或多个行,并让它根据这些示例推断出正确的架构。
Datasette从 sqlite-utils继承了这个特性——几年来我一直发现这是一种非常高效的使用 SQLite 数据库的方式。
此功能的真正魔力在于您可以将数据通过管道传输到 Datasette 中,甚至无需首先检查是否已创建适当的表。这是一种从数据到填充数据库和工作 API 的非常快速的方法。
在 1.0a2 之前,您可以多次调用/db/-/create with "rows"并且它可能会工作……除非您尝试插入具有已被使用的主键的行 – 在这种情况下您会得到一个错误。这限制了该功能的实用性。
现在您可以将"ignore": true或"replace": true传递给 API 调用,以告诉 Datasette 在遇到表中已存在的主键时该怎么做。
下面是一个使用上述作者数据的示例:
POST /books/-/create Authorization: Bearer $TOKEN Content-Type: application/json
{ “表” : “作者” , “pk” : “ id ” , “替换” :真, “行” :[ { “编号” : 1 , “姓名” : “厄休拉·勒金” , “出生” : “ 1929-10-21 ” }, { “编号” : 2 , “名字” : “特里普拉切特” , “出生” : “ 1948-04-28 ” }, { “编号” : 3 , “名字” : “尼尔·盖曼” , “出生” : “ 1960-11-10 ” } ] }
这将创建authors表(如果它不存在)并确保这三行以它们的确切状态存在于其中。如果一行已经存在,它将被替换。
请注意,这与 upsert 略有不同。 upsert 只会更新传入数据中提供的列,而其他列保持不变。替换将替换整行。
细粒度的权限
这是此版本中最重要的改进领域。
- 新的register_permissions(datasette)插件挂钩。插件现在可以注册命名权限,然后将在显示可用权限的各种界面中列出。 ( #1940 )
在此之前,权限只是字符串——比如"view-instance"或"view-table"或"insert-row" 。
插件可以引入自己的权限——许多插件已经这样做了,比如datasette-edit-schema添加了"edit-schema"权限。
为了开始构建用于管理权限的 UI,我需要 Datasette 来了解它们是什么!
register_permissions() 挂钩让他们可以做到这一点,Datasette 核心也使用它来注册自己的默认权限集。
使用以下命名元组注册权限:
许可=收藏。命名元组( “许可” ,( “名称” , “缩写” , “描述” , “takes_database” , “takes_resource” , “默认” ) )
abbr是缩写 – 例如insert-row可以缩写为ir 。这对于在空间非常宝贵的地方创建诸如签名的 API 令牌之类的东西很有用。
takes_database和takes_resource是布尔值,指示权限是否可以选择性地应用于特定数据库(例如execute-sql )或“资源”,这是我现在使用的名称,可以是 SQL 表,a SQL 视图或固定查询。
例如, insert-row权限可以授予整个 Datasette,或特定数据库中的所有表,或特定表。
最后, default值是一个布尔值,指示权限应该是默认允许( view-instance )还是默认拒绝( create-table等)。
下一个功能解释了为什么我需要让 Datasette 知道这些权限名称:
Datasette 现在对 API 令牌具有细粒度的权限!
这是我在使用其他 API 时一直想要的功能:能够创建只能执行受限操作子集的令牌。
例如,当我使用 GitHub API 时,我经常发现自己想要创建一个只能从特定存储库读取问题的“个人访问令牌”。令人气愤的是,有多少 API 将此功能排除在外。
/-/create-token接口(您可以先以 root 身份登录然后访问此页面,在latest.datasette.io上试用)让您创建一个 API 令牌,它可以代表您…然后可选指定允许令牌执行的操作子集。
由于新的权限注册系统,该页面上的 UI 知道哪些权限可以应用于 Datasette 本身中的哪些实体。
这是用户界面的部分屏幕截图:
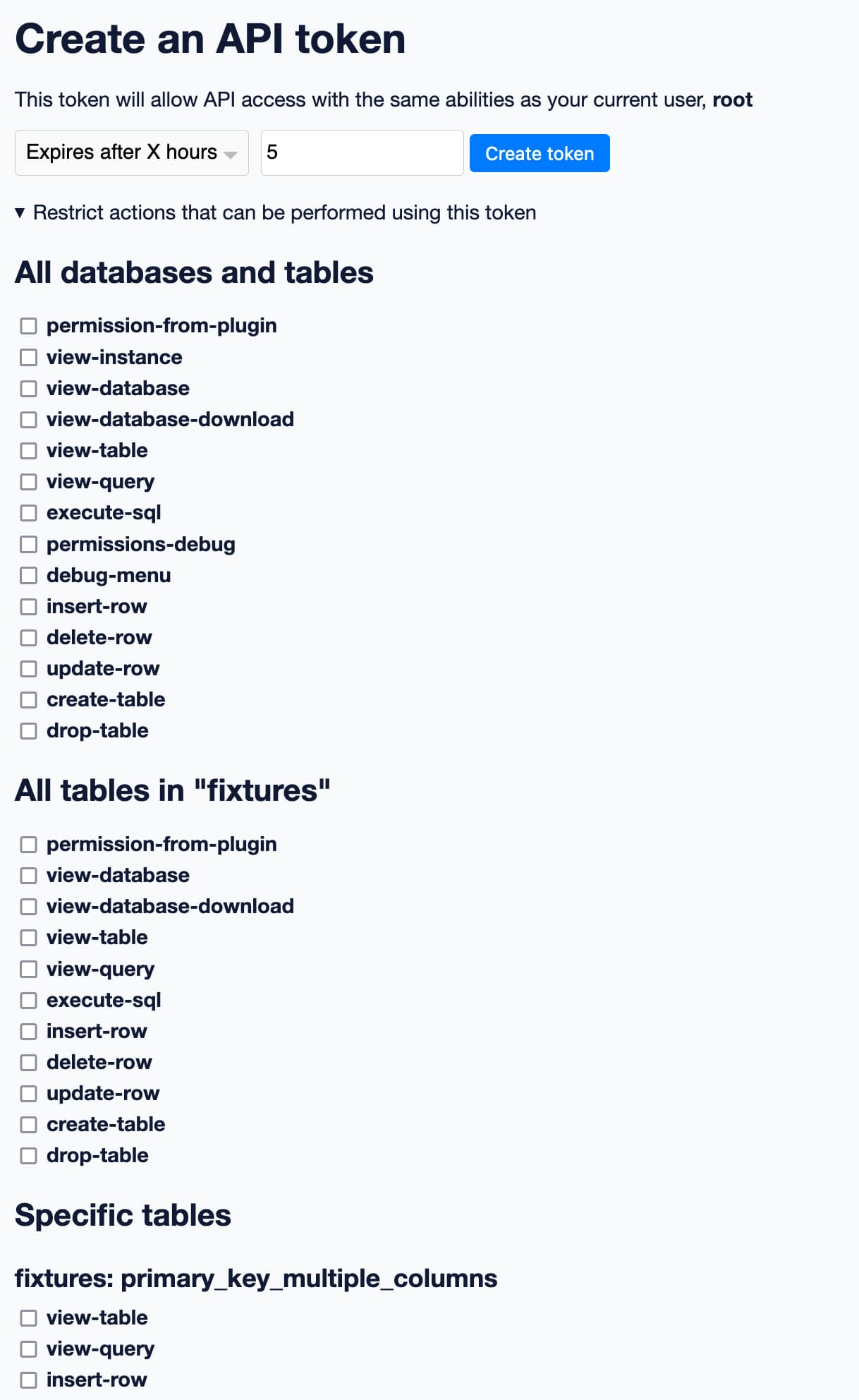
选择权限的一个子集,点击“创建令牌”,结果将是一个访问令牌,您可以将其复制并粘贴到另一个应用程序中,或者使用curl调用 Datasette。
这是我创建的一个示例令牌,它授予对所有 Datasette 的view-instance权限,以及对ephemeral数据库的view-database和execute-sql权限,在该演示中,临时数据库对匿名 Datasette 用户是隐藏的。
dstok_eyJhIjoicm9vdCIsInQiOjE2NzEwODUzMDIsIl9yIjp7ImEiOlsidmkiXSwiZCI6eyJlcGhlbWVyYWwiOlsidmQiLCJlcyJdfX19.1uw0xyx8UND_Y_vTVg5kEF6m3GU
这是我创建它时看到的屏幕截图:

我扩展了“令牌详细信息”部分以显示捆绑在已签名令牌中的 JSON。 "_r"块记录了令牌授予的具体权限:
-
"a": ["vi"]表示对所有数据集授予view-instance权限。 -
"d": {"ephemeral": ["vd", "es"]}表示针对ephemeral数据库授予view-database和execute-sql权限。
令牌还包含创建它的用户的 ID ( "a": "root" ) 和创建令牌的时间 ( "t": 1671085302 )。如果令牌设置为过期,则过期时间也会在此处烘焙。
您可以像这样使用curl在命令行上看到它的效果:
curl 'https://latest.datasette.io/ephemeral.json?sql=select+3+*+5&_shape=array'
这将返回一个禁止的错误。但是,如果您添加签名令牌:
curl 'https://latest.datasette.io/ephemeral.json?sql=select+3+*+5&_shape=array' -H 'Authorization: Bearer dstok_eyJhIjoicm9vdCIsInQiOjE2NzEwODUzMDIsIl9yIjp7ImEiOlsidmkiXSwiZCI6eyJlcGhlbWVyYWwiOlsidmQiLCJlcyJdfX19.1uw0xyx8UND_Y_vTVg5kEF6m3GU'
您将收到一个 JSON 响应:
[{ "3 * 5" : 15 }]
数据集创建令牌 CLI 工具
- 同样,
datasette create-tokenCLI 命令现在可以创建具有权限子集的令牌。 ( #1855 )- 用于以编程方式创建已签名 API 令牌的新datasette.create_token() API 方法。 ( #1951 )
另一种创建 Datasette 令牌的方法是在命令行上,使用datasette create-token 命令。
这已经升级为也支持细粒度的权限。
以下是如何为与我上面的临时示例相同的一组权限创建令牌:
datasette create-token root \ --all view-instance \ --database ephemeral view-database \ --database ephemeral execute-sql \ --secret MY_DATASETTE_SECRET
为了签署令牌,您需要传入服务器使用的--secret – 尽管它会从DATASETTE_SECRET环境变量中获取它(如果可用)。
这有一个有趣的副作用,您可以使用该命令为其他 Datasette 实例创建有效令牌,前提是您知道它们使用的秘密。我认为这种能力对于像我这样在无状态托管平台(如 Vercel 和 Google Cloud Run)上运行大量不同 Datasette 实例的人来说非常有用。
在 metadata.json/yaml 中配置权限
Datasette 长期以来一直能够使用命名越来越差的metadata.json/yaml 文件中的配置块来设置查看数据库和表的权限。
当我构建了引入新权限的新插件时,我发现自己希望有一种更简单的方式来为任意其他权限说“允许用户 X 执行操作 Y”。
metadata.json/yaml 文件中的新"permissions"键允许您这样做。
以下是如何指定具有"id": "simon"被允许使用 API 创建表并将数据插入docs数据库:
数据库: 文档: 权限: 创建表: 身份证:西蒙 插入行: 身份证:西蒙
这是您可以在自己的机器上运行的演示。将以上内容保存到permissions.yaml并在一个终端窗口中运行以下命令:
datasette docs.db --create --secret sekrit -m permissions.yaml
这将创建docs.db数据库(如果尚不存在),并使用permissions.yaml元数据文件启动 Datasette。
它将--secret设置为已知值(您应该始终在生产中使用随机安全密码),以便我们可以在下一步中轻松地将其与create-token一起使用:
然后在另一个终端窗口运行:
export TOKEN=$( datasette create-token simon \ --secret sekrit ) curl -XPOST http://localhost:8001/docs/-/create \ -H "Authorization: Bearer $TOKEN" \ -d '{ "table": "demo", "row": {"id": 1, "name": "Simon"}, "pk": "id" }'
第一行创建一个令牌,可以代表simon演员。然后,第二条curl行使用该标记通过/-/create端点创建一个表。
运行它,然后访问http://localhost:8001/docs/demo以查看新创建的表。
下一步是什么?
随着 1.0a2 版本的发布,我有理由相信 Datasette 1.0 是新功能完备的。在最终版本发布之前还有很多工作要做,但剩下的工作更令人生畏:我需要对大量现有功能进行干净的向后不兼容的破坏,以便发布一个我可以保持稳定的 1.0越长越好。
首先:我要重新设计 Datasette 的默认 API 输出。
简单表的当前默认 JSON 输出如下所示:
{ “数据库” : “固定装置” , “表” : “ facet_cities ” , “is_view” :假的, “human_description_en” : “按名称排序” , “行” :[ [ 3 、 “底特律” ], [ 2 、 “洛杉矶” ], [ 4 、 “记忆力” ], [ 1 , “旧金山” ] ], “截断” :假的, “filtered_table_rows_count” : 4 , “扩展列” :[], “可扩展列” :[], “专栏” :[ “身份证” , “名字” ], “主键” :[ “身份证” ], “单位” :{}, “查询” :{ “sql” : “从 facet_cities 中选择 id、名称,按名称限制排序 101 ” , “参数” :{} }, “facet_results” :{}, “suggested_facets” :[], “下一个” :空, “下一个网址” :空, “私人” :假的, “allow_execute_sql” :真, “query_ms” : 6.718471999647591 , “来源” : “测试/fixtures.py ” , “source_url” : “ https://github.com/simonw/datasette/blob/main/tests/fixtures.py ” , “许可证” : “ Apache 许可证 2.0 ” , “license_url” : “ https://github.com/simonw/datasette/blob/main/LICENSE ” }
除了非常冗长之外,您还会注意到行本身是这样表示的:
[ [ 3 、 “底特律” ], [ 2 、 “洛杉矶” ], [ 4 、 “记忆力” ], [ 1 , “旧金山” ] ]
我最初是这样设计的,因为我认为节省为每一行重复列名会更有效率。
实际上,每次我使用 Datasette 的 API 时,我都发现自己使用的是?_shape=array参数,它输出的是这种格式:
[ { “编号” : 3 , “名称” : “底特律” }, { “编号” : 2 , “名称” : “洛杉矶” }, { “编号” : 4 , “名称” : “ Memnonia ” }, { “编号” : 1 , “名称” : “旧金山” } ]
使用起来更加方便!
所以新的默认格式将如下所示:
{ “行” :[ { “编号” : 3 , “名称” : “底特律” }, { “编号” : 2 , “名称” : “洛杉矶” }, { “编号” : 4 , “名称” : “ Memnonia ” }, { “编号” : 1 , “名称” : “旧金山” } ] }
rows键在那里,所以我可以根据额外的?_extra=请求参数向输出添加额外的键。您将能够取回您在当前全脂表 API 中可以获得的所有内容,但您必须提出要求。
我想对整个 Datasette 进行大量其他更改 – 例如将metadata.yaml重命名为config.yaml以反映它作为将元数据附加到数据库的一种方式已经超出了其起源。
1.0 里程碑是其中许多想法的垃圾场。但这不是规范的参考:如果该里程碑中的所有当前内容都进入最终的 1.0 版本,我会感到非常惊讶。
当我接近 1.0 时,我会完善那个里程碑,因此它应该随着时间的推移变得更加准确。
再一次:现在是时候提供关于这些东西的反馈了! Datasette Discord对我来说是一种特别有价值的方式,可以让我获得对迄今为止工作的反馈以及我对未来的计划。
原文: http://simonwillison.net/2022/Dec/15/datasette-1a2/#atom-everything