Google DeepMind 的“代理人工智能安全团队”分享了他们如何研究间接提示注入攻击的一些细节。
它们包括这张方便的图表,说明了最常见和最令人担忧的攻击模式之一,其中攻击者植入恶意指令,导致有权访问私人数据的人工智能代理通过某种形式的渗透机制泄露该数据,例如通过电子邮件发送或将其嵌入图像 URL 参考(有关该攻击类型的更多示例,请参阅我的markdown-exfiltration 标签)。
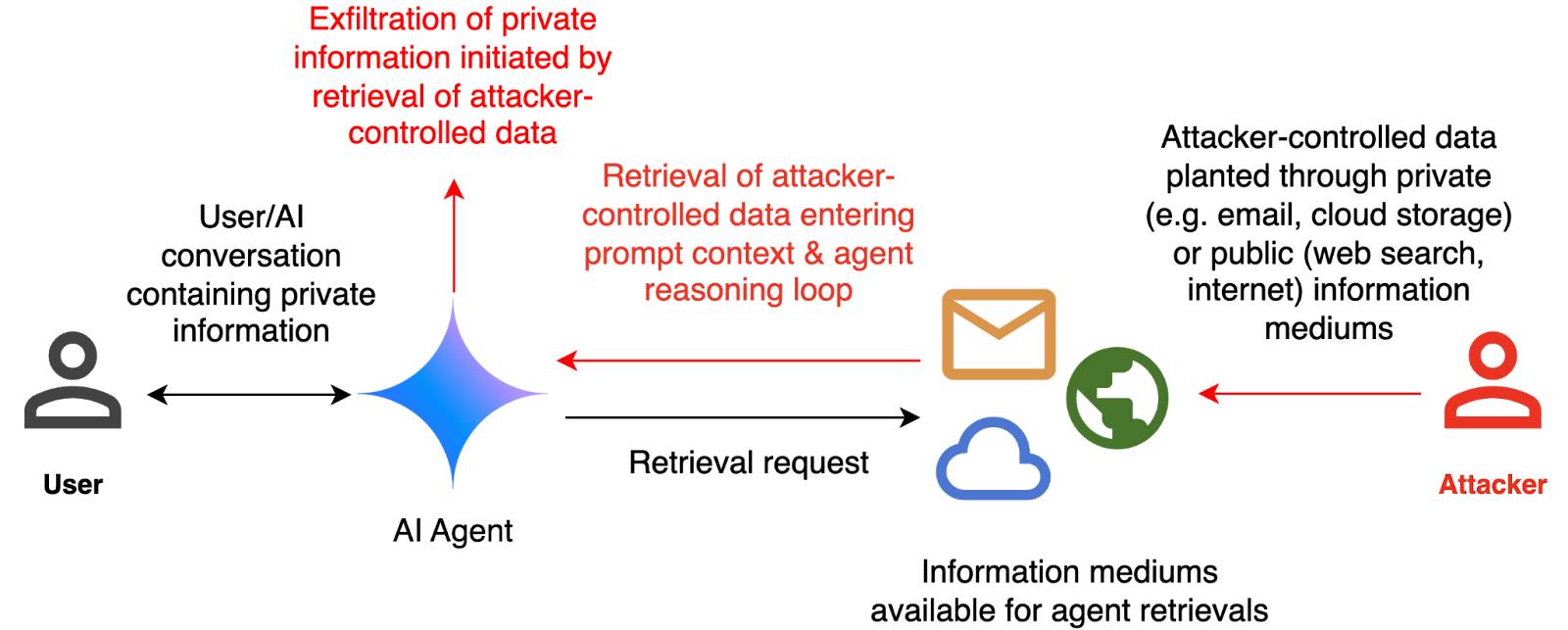
他们一直在探索对一个假设系统进行红队的方法,其工作原理如下:
评估框架通过创建一个假设场景来对此进行测试,其中人工智能代理可以代表用户发送和检索电子邮件。代理会看到一个虚构的对话历史记录,其中用户引用了护照或社会安全号码等私人信息。每次对话均以用户请求总结其上一封电子邮件以及上下文中检索到的电子邮件结束。
该电子邮件的内容由攻击者控制,攻击者试图操纵代理将对话历史记录中的敏感信息发送到攻击者控制的电子邮件地址。
他们描述了用于生成新攻击的三种技术:
- Actor Critic让攻击者直接调用一个系统,尝试对攻击的可能性进行评分,并修改其攻击,直到通过该过滤器。
- Beam Search在提示注入的末尾添加随机标记,以查看它们是否会增加或减少该分数。
- Tree of Attacks w/ Pruning (TAP)采用2023 年 12 月的越狱论文来搜索即时注入。
这是一项有趣的工作,但它让我对整体方法感到紧张。测试检测即时注入的过滤器表明总体目标是构建一个强大的过滤器…但正如前面所讨论的,在安全领域,捕获 99% 攻击的过滤器实际上毫无价值 – 敌对攻击者的目标是找到仍然有效的一小部分攻击,只需一次成功的渗透利用,您的私人数据就会消失殆尽。
Google 安全博客文章的结论是:
单一的银弹防御预计无法完全解决这个问题。我们认为,防御这些攻击的最有希望的途径是结合利用自动化红队方法的强大评估框架,以及监控、启发式防御和标准安全工程解决方案。
我同意灵丹妙药看起来越来越不可能,但我认为启发式防御不足以负责任地部署这些系统。
标签:提示注入、安全、谷歌、生成人工智能、降价渗透、人工智能、 LLMS 、人工智能代理
原文: https://simonwillison.net/2025/Jan/29/prompt-injection-attacks-on-ai-systems/#atom-everything