机器学习和人工智能领域的研究,现在几乎是每个行业和公司的一项关键技术,对于任何人来说都过于庞大,无法通读。本专栏Perceptron旨在收集一些最相关的最新发现和论文——特别是但不限于人工智能——并解释它们为何重要。
在最近的这批研究中,Meta 开源了一个语言系统,它声称这是第一个能够翻译 200 种不同语言并具有“最先进”结果的语言系统。谷歌不甘示弱,详细介绍了一种机器学习模型Minerva ,它可以解决包括数学和科学问题在内的定量推理问题。微软还发布了一种语言模型Godel ,用于生成类似于 Google 广为宣传的Lamda的“现实”对话。然后我们有了一些新的文本到图像的生成器。
Meta 的新型号 NLLB-200 是该公司“不让语言落后”计划的一部分,该计划旨在为世界上大多数语言开发机器驱动的翻译功能。受过训练,能够理解诸如坎巴语(班图族使用)和老挝语(老挝的官方语言)等语言,以及 540 多种以前的翻译系统无法很好支持或根本不支持的非洲语言,NLLB-200 将用于Meta 最近宣布,除了维基媒体基金会的内容翻译工具外,还可以翻译 Facebook News Feed 和 Instagram 上的语言。
人工智能翻译有可能大大扩展——并且已经扩展——无需人类专业知识即可翻译的语言数量。但正如一些研究人员所指出的那样,在人工智能生成的翻译中可能会出现跨越不正确术语、遗漏和误译的错误,因为这些系统主要是根据来自互联网的数据进行训练的——并非所有这些都是高质量的。例如,谷歌翻译曾经假设医生是男性,而护士是女性,而 Bing 的翻译器将诸如“桌子很软”之类的短语翻译成德语中的女性“die Tabelle”(指的是一张表格)。
对于 NLLB-200,Meta 表示它通过“主要过滤步骤”和针对全套 200 种语言的毒性过滤列表“彻底改革”了其数据清理管道。它在实践中的效果还有待观察,但是——正如 NLLB-200 背后的 Meta 研究人员在一篇描述他们方法的学术论文中所承认的那样——没有一个系统是完全没有偏见的。
同样,Godel 是一种基于大量网络文本训练的语言模型。然而,与 NLLB-200 不同,Godel 旨在处理“开放”对话——关于一系列不同主题的对话。
图片来源:微软
Godel 可以回答有关餐厅的问题,或者就特定主题(例如社区的历史或最近的体育比赛)进行来回对话。有用的是,和谷歌的 Lamda 一样,该系统可以利用网络上不属于训练数据集的内容,包括餐厅评论、维基百科文章和公共网站上的其他内容。
但是 Godel 遇到了与 NLLB-200 相同的陷阱。在一篇论文中,负责创建它的团队指出,由于用于训练它的数据中的“社会偏见和其他毒性的形式”,它“可能会产生有害的反应”。消除甚至减轻这些偏见在人工智能领域仍然是一个未解决的挑战——一个可能永远无法完全解决的挑战。
Google 的 Minerva 模型的潜在问题较少。正如其背后的团队在一篇博文中所描述的那样,该系统从包含数学表达式的 118GB 科学论文和网页的数据集中学习,以解决定量推理问题,而无需使用计算器等外部工具。 Minerva 可以生成包括数值计算和“符号操作”的解决方案,在流行的 STEM 基准测试中实现领先的性能。
Minerva 并不是为解决此类问题而开发的第一个模型。仅举几例,Alphabet 的 DeepMind展示了多种算法,可以帮助数学家完成复杂和抽象的任务,OpenAI 已经尝试了一个经过训练的系统来解决小学级别的数学问题。但该团队表示,Minerva 结合了最近的技术来更好地解决数学问题,其中包括一种方法,该方法涉及在向模型提出新问题之前,通过几个分步解决现有问题的方法来“提示”模型。

图片来源:谷歌
Minerva 仍然犯了相当多的错误,有时它会得出正确的最终答案,但推理错误。尽管如此,该团队仍希望它将作为“帮助推动科学和教育前沿”的模型的基础。
人工智能系统实际上“知道”什么的问题比技术更具有哲学意义,但它们如何组织这些知识是一个公平且相关的问题。例如,一个物体识别系统可能表明它“理解”家猫和老虎在某些方面是相似的,方法是允许概念在识别它们时有目的地重叠——或者它可能并没有真正理解,而这两种类型的生物与它完全无关。
加州大学洛杉矶分校的研究人员想看看语言模型是否“理解”了这种意义上的单词,并开发了一种称为“语义投影”的方法,表明是的,他们理解。虽然您不能简单地要求模型解释鲸鱼与鱼的不同之处和原因,但您可以看到它将这些词与其他词(如哺乳动物、大型、鳞片等)的联系紧密程度。如果鲸鱼与哺乳动物高度相关,并且与大型但与鳞片无关,那么您知道它对它在谈论什么有一个不错的了解。
动物属于模型概念化的从小到大范围的示例。
举个简单的例子,他们发现动物与大小、性别、危险和潮湿的概念相吻合(选择有点奇怪),而状态与天气、财富和党派关系相吻合。动物是无党派的,国家是无性别的,所以所有的轨道。
对于模型是否理解某些单词,现在没有比要求它绘制它们更可靠的测试了——而且文本到图像的模型一直在变得更好。 Google 的“Pathways Autoregressive Text-to-Image”或 Parti 模型看起来是迄今为止最好的模型之一,但很难将其与没有访问权限的竞争对手(DALL-E 等)进行比较,这是很少有模型提供的.无论如何,您都可以在此处阅读有关 Parti 方法的信息。
谷歌文章的一个有趣方面是展示了模型如何随着参数数量的增加而工作。看看随着数字的增加,图像如何逐渐改善:

提示是“一只穿着橙色连帽衫和蓝色太阳镜的袋鼠站在悉尼歌剧院前的草地上的肖像照片,胸前举着一个写着欢迎朋友的牌子!”
这是否意味着最好的模型都将拥有数百亿个参数,这意味着它们需要很长时间才能在超级计算机上训练和运行?就目前而言,当然——这是一种改进事物的蛮力方法,但人工智能的“滴答作响”意味着下一步不仅仅是让它变得更大更好,而是让它变得更小和等价。我们将看看谁能成功实现这一目标。
Meta 本周也展示了一种生成式 AI 模型,尽管它声称它为使用它的艺术家提供了更多代理权,但也不容错过。我自己经常使用这些生成器,其中一部分乐趣在于看看它会产生什么,但它们经常会提出无意义的布局或者没有“得到”提示。 Meta 的 Make-A-Scene 旨在解决这个问题。
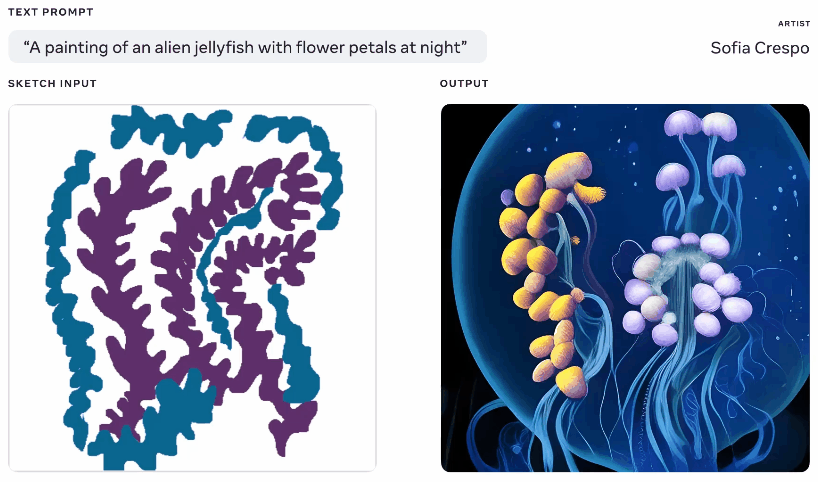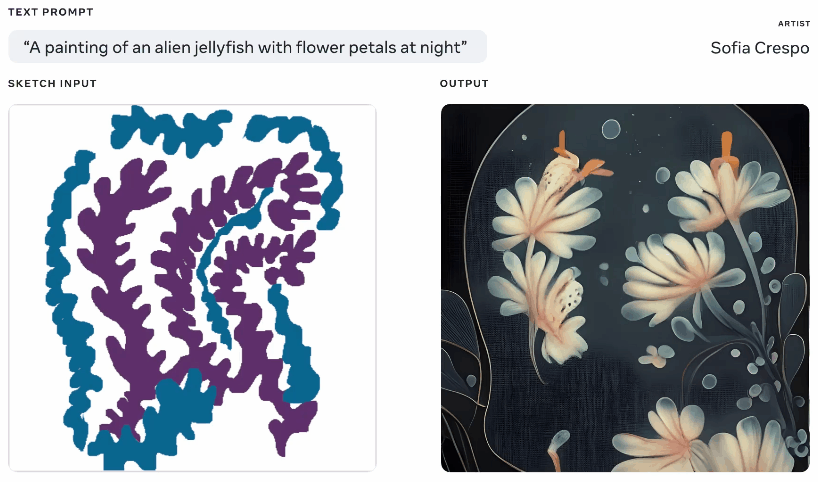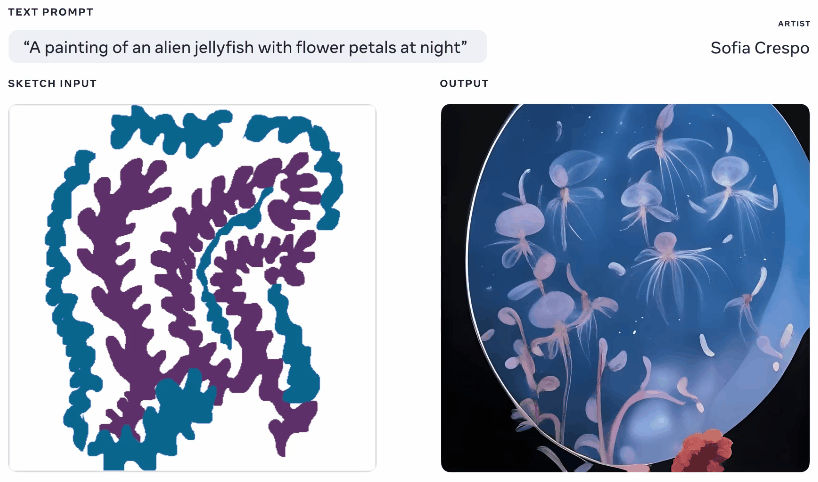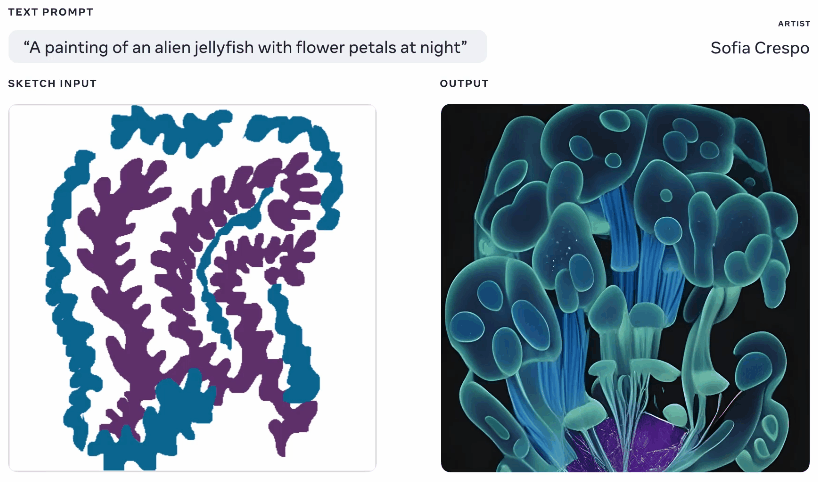
来自相同文本和草图提示的不同生成图像的动画。
这不是一个原创的想法——你画出你正在谈论的东西的基本轮廓,它用它作为在上面生成图像的基础。我们在 2020 年使用Google 的噩梦生成器看到了类似的情况。这是一个类似的概念,但经过放大以允许它使用草图作为基础从文本提示创建逼真的图像,但有很大的解释空间。对于对自己的想法有一个大致了解但想要包含模型的无限和怪异创造力的艺术家来说可能很有用。
像大多数这些系统一样,Make-A-Scene 实际上并不可供公众使用,因为与其他系统一样,它在计算方面非常贪婪。别担心,我们很快就会在家里得到这些东西的体面版本。