我刚刚发布了llm-smollm2 ,这是一个LLM的新插件,它将SmolLM2-135M-Instruct LLM 的量化副本捆绑在 Python 包内。
这意味着您现在可以pip install完整的 LLM!
如果您已经在使用LLM,您可以像这样安装它:
llm 安装 llm-smollm2
然后运行提示如下:
llm -m SmolLM2 '狗是真的吗? '
(小型模型的新的最喜欢的测试提示,由Tim Duffy提供。这是结果)。
如果您还没有 LLM,请首先按照这些安装说明进行操作,或者根据您获取 Python 工具的首选方式,使用brew install llm或pipx install llm或uv tool install llm 。
如果您有uv设置,则根本不需要安装任何东西!以下命令将一次性启动一个临时环境、安装必要的软件包并启动与模型的聊天会话:
uvx --with llm-smollm2 llm 聊天 -m SmolLM2
![$ uvx --with llm-smollm2 llm chat -m SmolLM2 与 SmolLM2 聊天 输入“exit”或“quit”退出 输入“!multi”输入多行,然后输入“!end”结束 > 告诉我一个关于狗的长故事 狗的故事是一个关于爱、失去和宇宙潜规则的故事。故事要从一只名叫麦克斯的小而胆怯、胆怯的狗开始。马克斯出生在一个充满爱的家庭,但他的生活却被残酷无情的主人永远改变了。他只能自己照顾自己,他也只能自己照顾自己。 麦克斯的主人是一位善良而温柔的灵魂,名叫埃琳娜,但她却是一位残忍而残忍的人。她没有耐心,没有爱,她会做任何事情来让麦克斯远离她。麦克斯只能自己照顾自己,他也只能自己照顾自己。 麦克斯的主人埃琳娜决心让麦克斯快乐。她带着麦克斯来到了一个美丽又美丽的地方,在那里麦克斯可以自由地漫步。允许麦克斯自由地漫游,允许麦克斯自由地漫游。 [然后多次重复这句话]](https://static.simonwillison.net/static/2025/smol.gif)
寻找一个小模型
该模型几乎恰好为 100MB 这一事实并非巧合:这是可以上传到 Python 包索引 (PyPI) 的 Python 包的默认大小限制。
我在 Bluesky 上询问是否有人见过小于 100MB 的几乎可用的 GGUF 模型,Artisan Loaf向我推荐了SmolLM2-135M-Instruct 。
我最终使用了QuantFactory的量化方法,因为它是我尝试过的第一个有效的 100MB 以下模型。
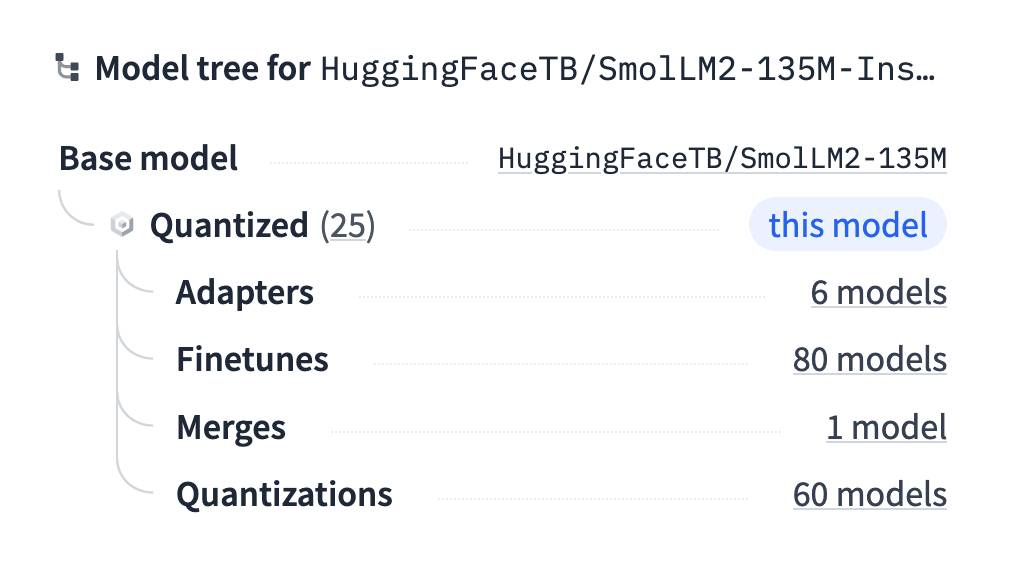
查找量化模型的技巧:Hugging Face 在其模型页面的侧面板中有一个简洁的“模型树”功能,其中包括相关量化模型的链接。我发现我的大多数 GGUF 都使用该功能。
构建插件
我首先使用 Python 和llama-cpp-python库尝试了该模型,如下所示:
uv run --with llama-cpp-python python
然后:
从llama_cpp导入Llama 从pprint导入pprint llm =骆驼( model_path = "SmolLM2-135M-Instruct.Q4_1.gguf" ) 输出= llm 。 create_chat_completion (消息= [ { “角色” : “用户” , “内容” : “嗨” } ]) 打印(输出)
这给了我预期的输出:
{ '选择' : [{ '完成原因' : '停止' ,
‘索引’ : 0 ,
'logprobs' :无,
'消息' : { '内容' : '您好!今天我能为您提供什么帮助吗? ,
'角色' : '助理' }}],
“创建” : 1738903256 ,
'id' : 'chatcmpl-76ea1733-cc2f-46d4-9939-90efa2a05e7c' ,
'模型' : 'SmolLM2-135M-Instruct.Q4_1.gguf' ,
'对象' : '聊天完成' ,
'用法' :{ 'completion_tokens' : 9 , 'prompt_tokens' : 31 , 'total_tokens' : 40 }}
但它也向我的终端发送了大量的调试输出 – 开始是这样的:
llama_model_load_from_file_impl: using device Metal (Apple M2 Max) - 49151 MiB free llama_model_loader: loaded meta data with 33 key-value pairs and 272 tensors from SmolLM2-135M-Instruct.Q4_1.gguf (version GGUF V3 (latest)) llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output. llama_model_loader: - kv 0: general.architecture str = llama
然后又持续了500多行!
我过去在llama-cpp-python和llama.cpp中遇到过这个问题,并且很遗憾地发现文档仍然没有关于如何避免这种情况的很好的答案。
所以我转向了刚刚发布的Gemini 2.0 Pro(实验版) ,因为我知道它是一个具有较长输入限制的强大模型。
我通过它运行了整个llama-cpp-python代码库,如下所示:
cd /tmp git 克隆 https://github.com/abetlen/llama-cpp-python cd llama-cpp-python 要提示的文件 -e py . -c | llm -m gemini-2.0-pro-exp-02-05 \ '我怎样才能阻止这个库在运行时记录任何信息 - 没有 stderr 或类似的东西'
这是我回复的答案。它建议将记录器设置为logging.CRITICAL ,将verbose=False传递给构造函数,最重要的是,使用以下上下文管理器来抑制所有输出:
从contextlib导入contextmanager , redirect_stderr , redirect_stdout @上下文管理器 def抑制输出(): ”“” 抑制上下文中的所有 stdout 和 stderr 输出。 ”“” 将open ( os . devnull , "w" )作为devnull : 使用redirect_stdout ( devnull ), redirect_stderr ( devnull ): 屈服
这有效!事实证明,大部分输出来自初始化LLM类,所以我将其包装如下:
使用suppress_output (): model = Llama ( model_path = self . model_path , verbose = False )
概念证明在手后,我开始编写插件。我从我的simonw/llm-plugin cookiecutter 模板开始:
uvx cookiecutter gh:simonw/llm-插件
[1/6] plugin_name (): smollm2 [2/6] description (): SmolLM2-135M-Instruct.Q4_1 for LLM [3/6] hyphenated (smollm2): [4/6] underscored (smollm2): [5/6] github_username (): simonw [6/6] author_name (): Simon Willison该插件的其余部分大部分是从我现有的llm-gguf插件借用的,并根据llama-cpp-python项目的最新 README 进行更新。
有关编写插件的教程中有有关构建插件的更多信息
打包插件
一旦我完成了这项工作,最后一步就是弄清楚如何为 PyPI 打包它。我不太确定将二进制文件捆绑到 Python 包中的最佳方法,尤其是使用pyproject.toml文件的方法…因此我将现有pyproject.toml文件的副本转储到 o3-mini-high 中并提示:
修改此以将 SmolLM2-135M-Instruct.Q4_1.gguf 文件捆绑到包内。我不想使用舱口或清单或任何东西,我只想使用安装工具。
这是共享的文字记录– 它给了我我想要的东西。我通过将其添加到toml文件的末尾来捆绑它:
[工具。设置工具。包数据] llm_smollm2 = [ “ SmolLM2-135M-Instruct.Q4_1.gguf ” ]
然后将该.gguf文件放入llm_smollm2/目录中,并将我的插件代码放入llm_smollm2/__init__.py中。
我通过运行以下命令在本地进行了测试:
python -m pip 安装构建 蟒蛇-m构建
我启动了一个新的虚拟环境并运行pip install ../path/to/llm-smollm2/dist/llm_smollm2-0.1-py3-none-any.whl以确认该包按预期工作。
发布到 PyPI
我的 cookiecutter 模板附带了GitHub Actions 工作流程,当使用 GitHub Web 界面创建新版本时,该工作流程会将包发布到 PyPI。这是相关的 YAML:
部署: 运行: ubuntu-latest 需求: [测试] 环境:发布 权限: id-token :写入 步骤: -使用: actions/checkout@v4 -名称:设置Python 使用: actions/setup-python@v5 和: python-版本: “ 3.13 ” 缓存:点 缓存依赖路径: pyproject.toml -名称:安装依赖项 运行: | pip install setuptools 轮构建 -名称:构建 运行: | 蟒蛇-m构建 -名称:发布 使用: pypa/gh-action-pypi-publish@release/v1
这在test作业通过后运行。它使用pypa/gh-action-pypi-publish操作来发布到 PyPI – 我在这个 TIL 中写了更多关于它如何工作的内容。
模型好用吗?
这个真的不是啊!这并不奇怪,但事实证明 94MB 的空间对于一个可以做任何有用事情的模型来说确实不够。
它玩起来非常有趣,而且我仍然认为,小而弱的模型是帮助建立该技术实际工作原理的心智模型的好方法。
这并不是说 SmolLM2 不是一个出色的模型系列。我在这里运行最小、最受限制的版本。 SmolLM – 速度极快且功能强大,描述了完整的模型系列 – 有 135M、360M 和 1.7B 尺寸。更大的版本功能更强大。
如果有人能找出 94MB 版本真正有用的东西,我很乐意听到。
标签: pip 、插件、项目、 pypi 、 python 、 ai 、 github-actions 、 generative-ai 、 edge-llms 、 llms 、 ai-辅助编程、 llm 、 gemini 、 uv 、 smollm 、 o3 、 llama-cpp
原文: https://simonwillison.net/2025/Feb/7/pip-install-llm-smollm2/#atom-everything