LLM 0.23今天发布,其标志性功能是对模式的支持 – 一种从与用户提供的规范相匹配的模型提供结构化输出的新方法。我还升级了llm-anthropic和llm-gemini插件以添加对模式的支持。
TLDR:您现在可以执行以下操作:
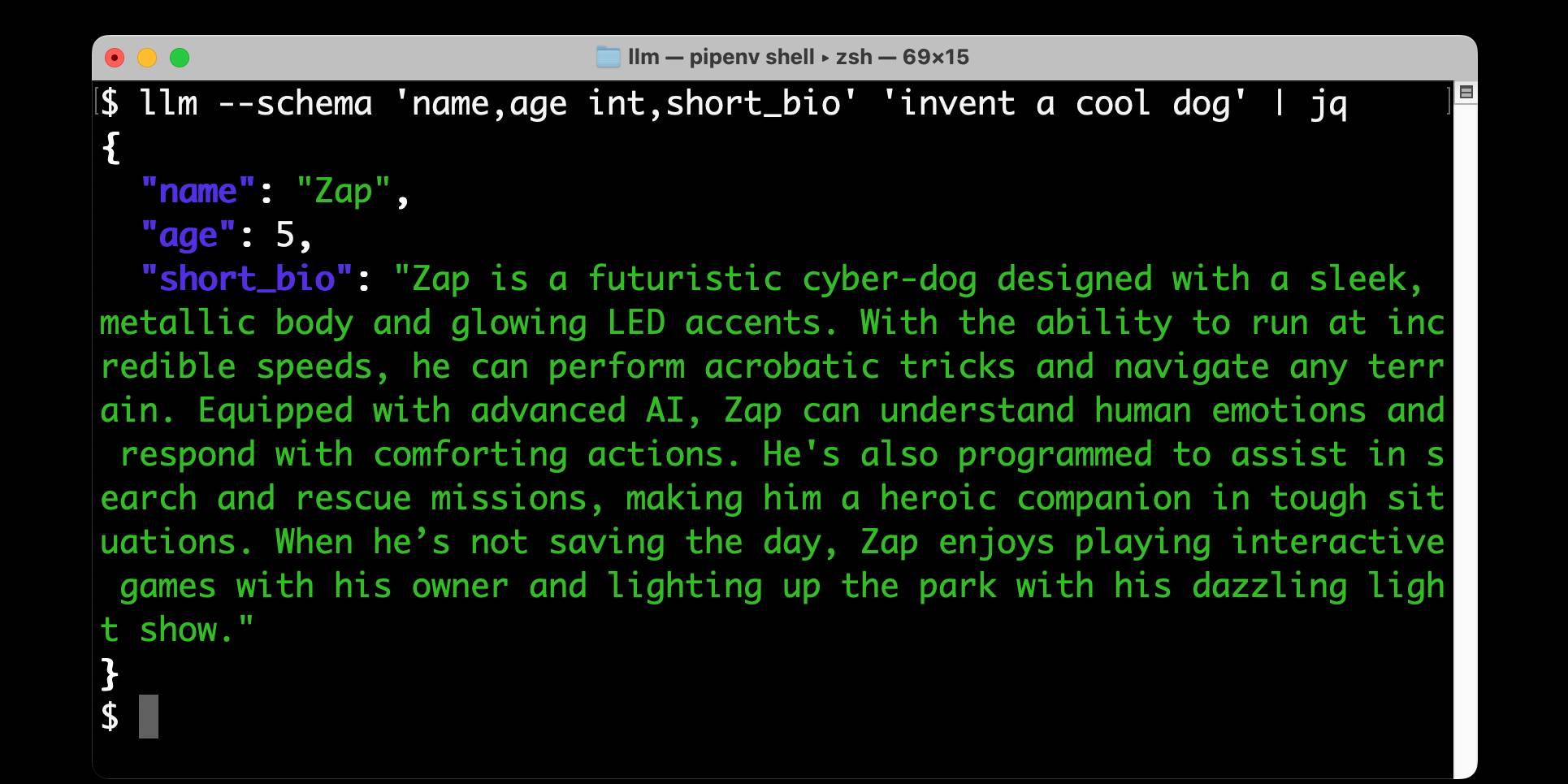
llm --schema ' name,age int,short_bio ' '发明一只很酷的狗'
并返回:
{ “名称” : “ Zylo ” , “年龄” : 4 , "short_bio" : " Zylo 是一种独特的杂交品种,是西伯利亚哈士奇和柯基犬的混种。Zylo 拥有醒目的蓝眼睛和随季节变换色调的蓬松多彩皮毛,体现了冬季和夏季的精神。Zylo 以其顽皮的个性和聪明才智而闻名,可以表演各种技巧,喜欢捡起他最喜欢的飞盘。他时刻准备着冒险,就像在山里徒步旅行一样快乐经过一整天的玩耍后,他正依偎在沙发上。 ” }
更多详细信息,请参阅发行说明和LLM 模式教程,其中包括一个比发明狗更有用的示例(从新闻文章中提取人物)!
结构化数据提取是法学硕士的杀手级应用
一段时间以来,我一直怀疑法学硕士最具商业价值的应用是将非结构化内容转变为结构化数据。这就是你向 LLM 提供一篇文章、PDF 或屏幕截图,然后用它将其转换为 JSON 或 CSV 或其他结构化格式的技巧。
仅通过提示就可以取得很好的结果:将数据输入 LLM,为其提供您想要的输出示例,并让它找出详细信息。
许多领先的法学硕士提供商现在都将此作为一项功能。 OpenAI、Anthropic、Gemini 和 Mistral 都通过其 API 提供“结构化输出”的变体作为附加选项:
- OpenAI:结构化输出
- Gemini:使用 Gemini API 生成结构化输出
- Mistral:自定义结构化输出
- Anthropic 的工具使用可用于此目的,如使用 Claude 提取结构化 JSON 和工具使用食谱示例所示。
这些机制都非常相似:您将JSON 模式传递给定义所需形状的模型,然后它们使用该模式来指导模型的输出。
这有多可靠可能会有所不同!一些提供程序使用类似Jsonformer的技巧,将 JSON 模式编译为在运行时与模型的下一个令牌生成交互的代码,限制其仅生成在模式上下文中有效的令牌。
其他提供商 YOLO it – 他们相信他们的模型“足够好”,向其展示模式将产生正确的结果!
在实践中,这意味着您需要意识到有时这些东西会出错。与任何法学硕士一样,永远无法保证 100% 的可靠性。
从我迄今为止的实验来看,根据您选择的模型,这些错误很少见。如果您使用顶级模型,它几乎肯定会做正确的事情。
为 LLM 设计此功能
我想要这个功能已经很久了。我认为这是全面使用工具的重要一步,我很高兴将其引入 CLI 工具和 Python 库。
LLM 被设计为不同模型上的抽象层。这使得构建新功能变得更加困难,因为我需要找出一个共同点,然后构建一个抽象,以捕获尽可能多的价值,同时仍然足够通用以跨多个模型工作。
对跨多个供应商的结构化输出的支持现已成熟,我已准备好致力于设计。
我的此功能的第一个版本专门用于 JSON 模式。本教程的早期版本从此示例开始:
卷曲 https://www.nytimes.com/ | uvx 条带标签| \ llm --schema ' { “类型”:“对象”, “特性”: { “项目”: { “类型”:“数组”, “项目”: { “类型”:“对象”, “特性”: { “标题”:{ “类型”:“字符串” }, “短摘要”:{ “类型”:“字符串” }, “关键点”:{ “类型”:“数组”, “项目”: { “类型”:“字符串” } } }, “必需”:[“标题”,“short_summary”,“key_points”] } } }, “必需”:[“项目”] } ' |杰克
在这里,我们将完整的 JSON 模式文档提供给新的llm --schema选项,然后通过管道传输到《纽约时报》的主页(通过strip-tags运行之后),并请求页面上多个项目的headline 、 short_summary和key_points 。
这个示例仍然适用于已完成的功能 – 您可以在此处查看示例 JSON 输出– 但手动构建这些长格式模式是一个很大的痛苦。
所以…我发明了自己的快捷语法。
前面的例子是一个简单的说明:
llm --schema ' name,age int,short_bio ' '发明一只很酷的狗'
这里的模式是一个以逗号分隔的字段名称列表,具有可选的空格分隔类型。
此处描述了完整简洁的模式语法。本教程中有一个更复杂的示例,它使用换行符分隔的形式来提取有关新闻文章中提到的人员的信息:
卷曲' https://apnews.com/article/trump-federal-employees-firings-a85d1aaf1088e050d39dcf7e3664bb9f ' | \ uvx 条带标签| \ llm --模式多“ 姓名:人的名字 组织:他们代表谁 角色:他们的职位或角色 学到的东西:我们从这个故事中学到了什么 Article_headline:故事的标题 Article_date:发布日期,格式为 YYYY-MM-DD " --system '提取本文提到的人'
这里的--schema-multi选项告诉 LLM 采用单个对象的模式并将其升级为这些对象的数组(实际上是一个具有单个"items"属性的对象,它是一个对象数组),这是请求针对单个输入多次返回相同模式的快速方法。
重用模式和创建模板
我最初的模式计划是提供一个单独的llm extract命令来运行此类操作。我最终走向了不同的方向 – 我意识到将--schema添加到默认的llm prompt命令将使其能够与其他现有功能(例如用于输入图像和 PDF 的附件)进行互操作。
应用模式最有价值的方法是跨越许多不同的提示,以便从许多不同的来源收集相同的信息结构。
我在--schema选项中投入了很多思考。它需要各种不同的值 – 引用文档:
此选项可以采用多种形式:
- 提供 JSON 架构的字符串:
--schema '{"type": "object", ...}'- 精简模式定义:
--schema 'name,age int'- 磁盘上包含 JSON 架构的文件的名称或路径:
--schema dogs.schema.json- 先前记录的模式的十六进制 ID:
--schema 520f7aabb121afd14d0c6c237b39ba2d– 可以使用llm schemas命令找到这些 ID。
- 已保存在模板中的架构:
--schema t:name-of-template
本教程演示了通过使用一次模式来保存模式,然后通过新的llm schemas命令获取其 ID,然后将其保存到模板(以及系统提示符),如下所示:
llm --架构 3b7702e71da3dd791d9e17b76c88730e \ --system '提取本文提到的人' \ ——救人
现在我们可以使用llm -t people快捷方式输入新文章来应用新保存的模板:
卷曲 https://www.theguardian.com/commentisfree/2025/feb/27/billy-mcfarland-new-fyre-festival-fantasist | \ 条形标签| llm-t人
利用记录的结构化数据做更多事情
运行了一些使用相同架构的提示后,下一步显然是对已收集的数据执行某些操作。
我最终在现有的llm 日志机制之上实现了这一点。
LLM 已经默认记录它对 SQLite 数据库做出的每个提示和响应 – 根据以下查询,我的数据库现在包含超过 4,747 条这样的记录:
sqlite3 " $( llm 日志路径) " '从响应中选择 count(*) '
对于模式,其中越来越多的部分是有效的 JSON。
由于 LLM 记录用于每个响应的架构 – 使用架构 ID,该 ID 源自扩展 JSON 架构的内容哈希 – 现在可以向 LLM 询问使用特定架构的所有响应:
llm 日志 --schema 3b7702e71da3dd791d9e17b76c88730e --short
我回来了:
-型号: gpt-4o-mini 日期时间: ' 2025-02-28T07:37:18 ' 对话: 01jn5qt397aaxskf1vjp6zxw2a system :提取本文中提到的人 提示:菜单 美联社标志菜单 世界 美国 政治 体育 娱乐 商业 科学 事实核查怪事,健康时事通讯 N... -型号: gpt-4o-mini 日期时间: ' 2025-02-28T07:38:58 ' 对话: 01jn5qx4q5he7yq803rnexp28p system :提取本文中提到的人 提示:跳到主要内容跳到导航跳到导航打印订阅新闻通讯 登录USUS版UK版A... -型号: GPT-4O 日期时间: ' 2025-02-28T07:39:07 ' 对话: 01jn5qxh20tksb85tf3bx2m3bd system :提取本文中提到的人 附件: -类型:图像/jpeg 网址: https ://static.simonwillison.net/static/2025/onion-zuck.jpg
正如您所看到的,我已经使用 GPT-4o mini 运行该示例模式三次(在构建教程时) – 针对来自curl ... | strip-tags和一次针对JPEG 屏幕截图来演示附件支持。
{kind=link}
从日志中提取收集的 JSON 显然是有用的下一步…因此我向llm logs添加了几个选项来支持该用例。
第一个是--data – 添加将导致LLM logs仅输出使用模式收集的数据。将其与-c混合以查看最新响应中的 JSON:
llm 日志-c --data
输出:
{ “姓名” : “ Zap ” , “年龄” : 5 , “short_bio” :...
将其与--schema选项相结合是事情变得非常有趣的地方。您可以使用前面描述的任何机制指定模式,这意味着您可以通过将--data与--schema X组合(以及-n 0表示所有内容)来查看使用该模式收集的所有数据。
这是我发明的所有狗:
llm 日志 --schema ' name,age int,short_bio ' --data -n 0
输出(此处被截断):
{ "name" : " Zap " , "age" : 5 , "short_bio" : " Zap 是一个未来派...... " } { "name" : " Zephyr " , "age" : 3 , "short_bio" : " Zephyr 是一款充满冒险精神的...... " } { "name" : " Zylo " , "age" : 4 , "short_bio" : " Zylo 是一个独特的...... " }
一些模式收集多个项目,产生如下所示的输出(来自教程):
{"items": [{"name": "Mark Zuckerberg", "organization": "... {"items": [{"name": "Billy McFarland", "organization": "...
我们可以通过添加--data-key items来取回各个对象。在这里,我还使用--schema t:people快捷方式来指定之前保存到people模板中的架构。
llm 日志 --schema t:people --data-key items
输出:
{"name": "Katy Perry", "organization": ... {"name": "Gayle King", "organization": ... {"name": "Lauren Sanchez", "organization": ...
此功能默认输出以换行符分隔的 JSON,但您可以添加--data-array标志来取回 JSON 对象数组。
…这意味着您可以将其通过管道传输到sqlite-utils insert中以创建 SQLite 数据库!
llm 日志 --schema t:people --data-key items --data-array | \ sqlite-utils 插入 data.db 人们 -
将所有这些加在一起,我们可以构建一个模式,针对一堆源运行它,并将生成的结构化数据转储到 SQLite 中,我们可以使用 SQL 查询(和Datasette )来探索它。这是一个非常强大的组合。
使用 LLM 的 Python 库中的模式
如今,在 Python 中使用模式最流行的方法是使用Pydantic ,以至于许多模型的官方 API 库都直接将 Pydantic 纳入此目的。
LLM 已经依赖于 Pydantic,对于这个项目,我最终放弃了对 Pydantic v1 和 v2 的双重支持,只致力于 v2 。
Pydantic 如此受欢迎的一个关键原因是使用它构建 JSON 模式文档非常简单:
导入pydantic , json 类Dog ( pydantic . BaseModel ): 名称: str 年龄:整数 简介: str 模式=狗。 model_json_schema () print ( json . dumps ( schema , indent = 2 ))
输出:
{ “特性” : { “姓名” : { "标题" : "姓名" , “类型” : “字符串” }, “年龄” : { "title" : "年龄" , “类型” : “整数” }, “生物” :{ “标题” : “简历” , “类型” : “字符串” } }, “必需的” : [ “姓名” , “年龄” , “生物” ], “标题” : “狗” , “类型” : “对象” }
LLM 的 Python 库不要求您使用 Pydantic,但它支持将 Pydantic BaseModel子类或完整的 JSON 模式传递给新的model.prompt(schema=)参数。这是文档中的用法示例:
导入llm , json 从pydantic导入BaseModel 狗类(基础模型): 名称: str 年龄:整数 型号= llm 。 get_model ( “gpt-4o-mini” ) 响应=模型。提示( “描述一只好狗” ,模式=狗) 狗= json .负载(响应。文本()) 打印(狗) # {"姓名":"好友","年龄":3}
LLM 模式的下一步是什么?
到目前为止,我已经实现了对 OpenAI、Anthropic 和 Gemini 模型的模式支持。插件作者文档包含有关如何将其添加到其他插件的详细信息 – 我很想看到本地模型插件之一也实现此模式。
我将在下周的NICAR 2025数据新闻会议上举办一个关于尖端网络抓取技术的研讨会。 LLM 模式是 NDD(NICAR 驱动开发)的一个很好的例子,我正在其中大量生产该会议所需的功能(另请参阅 shot-scraper 的新HAR 支持)。
我预计研讨会将是进一步完善此功能的设计和实现的绝佳机会!
我还将使用这个新功能向我的datasette-extract 插件添加多个模型支持,该插件提供用于结构化数据提取的 Web UI,将结果记录直接写入 SQLite 数据库表。
标签:项目、人工智能、带注释的发行说明、生成人工智能、 LLMS 、 LLM 、结构化提取
原文: https://simonwillison.net/2025/Feb/28/llm-schemas/#atom-everything