通常,在设计系统时,我们的目标是在数据一致性、可用性、延迟等方面追求完美。
系统设计最困难的部分是很难(如果不是不可能)设计出同时具有完美一致性、完美可用性、极低延迟和极高吞吐量的系统。
相反,当我们进行系统设计时,最好将这些属性中的每一个视为不同轴上的点,我们平衡这些点以找到我们所支持的应用程序的“正确匹配”。
我最近在Bluesky 的Follow Feed/Timeline 的设计中进行了一些重大权衡,以牺牲一致性为代价来提高写入性能,同时不会对用户产生负面影响,但将 P99 减少了 96% 以上。
时间轴扇出
当您在 Bluesky 上发布帖子时,您的帖子会被我们的系统索引并保存到数据库中,我们可以在数据库中获取它以进行水合并在 API 响应中提供服务。
此外,对您帖子的引用会“扇出”给您的关注者,以便他们可以在自己的时间轴中看到它。
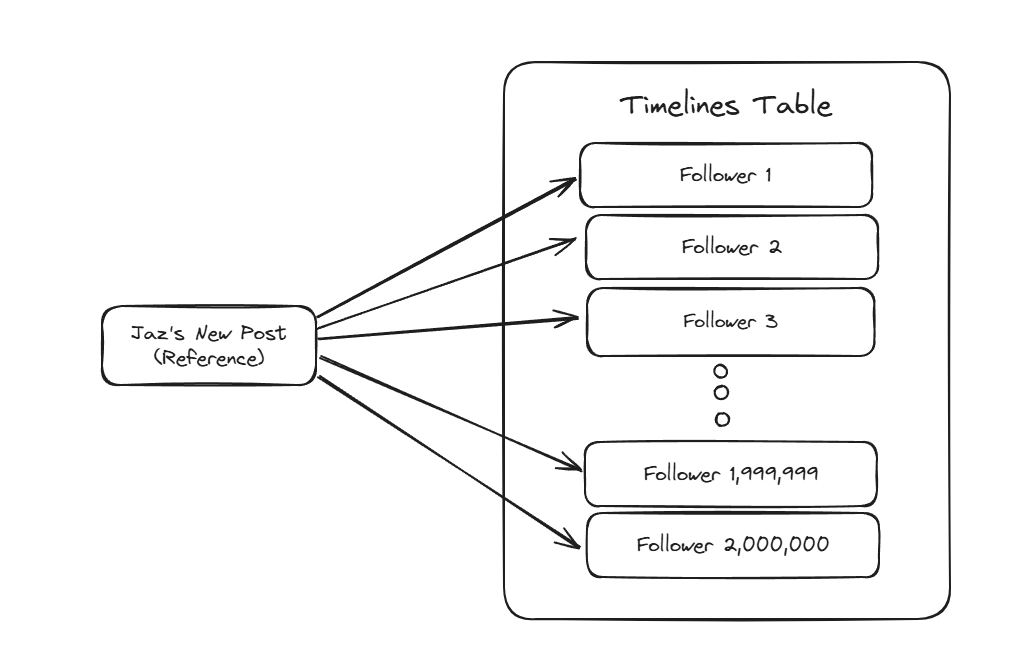
此过程涉及查找您的所有关注者,然后以相反的时间顺序将新行插入到他们的每个时间轴表中,并引用您的帖子。
当用户加载他们的时间轴时,我们会获取一页帖子引用,然后同时合并帖子/参与者以快速构建 API 响应,让他们看到他们关注的人的最新内容。
时间线表由用户进行分片。这意味着每个用户都有自己的时间线分区,随机分布在我们的水平可扩展数据库 (ScyllaDB) 的分片中,跨多个分片复制以实现高可用性。
写入时会定期修剪时间线,使其接近目标长度并删除较旧的帖子引用以节省空间。
您所在地区的热门碎片
Bluesky 目前拥有约3200 万用户,我们的时间轴数据库分为数百个分片。
为了在如此少量的分片上支持数百万个分区,每个用户的时间轴分区与数万个其他用户的时间轴位于同一位置。
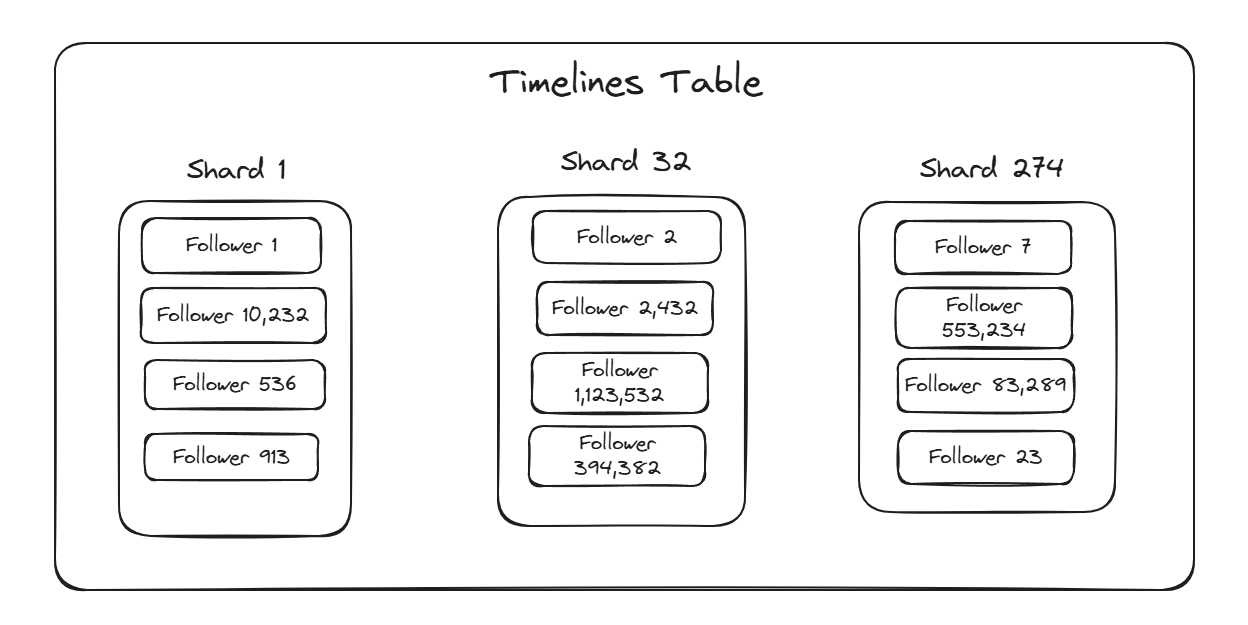
在所有用户都表现良好的正常情况下,这不会出现问题,因为单个时间轴的工作足够小,一个分片可以处理数以万计的用户的工作,而不会产生沉重的负担。
不幸的是,由于用户数量众多,其中一些人会做出异常的事情,例如……嗯……关注数十万其他用户。
一般来说,这可以通过策略和审核来解决,以防止滥用用户对系统造成过大的负载,但这些过程需要时间并且可能并不完美。
当用户关注数十万其他用户时,他们的时间线就会变得异常活跃,写入和修剪的速度会大幅提高。
这种负载会减慢用户时间线的各个操作,这对于行为不良的用户来说没什么问题,但会给与他们共享分片的数以万计的其他用户带来问题。
我们通常将这种情况称为“热分片”:分片中的某些居民拥有“热”数据,这些数据的写入或读取速度比其他分片高得多。由于分片上的数据仅被复制几次,因此我们无法有效地利用数据库的水平规模来处理所有这些额外的工作。
相反,“热分片”最终会花费大量时间为单个分区工作,导致对并置分区的操作也会减慢。
堆叠延迟
回到我们的扇出流程,让我们考虑一个用户扇出后跟随 2,000,000 个其他用户的情况。
正常情况下,写入单个时间轴平均需要大约 600 微秒。如果我们按顺序向用户关注者的时间轴写入内容,我们最多需要 20 分钟才能扇出这篇文章。
相反,如果我们同时扇出到 1,000 个时间线,我们可以在约 1.2 秒内完成此扇出作业。
这听起来不错,但它过度简化了系统的一个重要属性: 尾部延迟。
写入的平均延迟约为 600 微秒,但有些写入所需的时间要少得多,有些则需要更多。事实上,写入 Timelines 集群的 P99 延迟可能高达 15 毫秒!
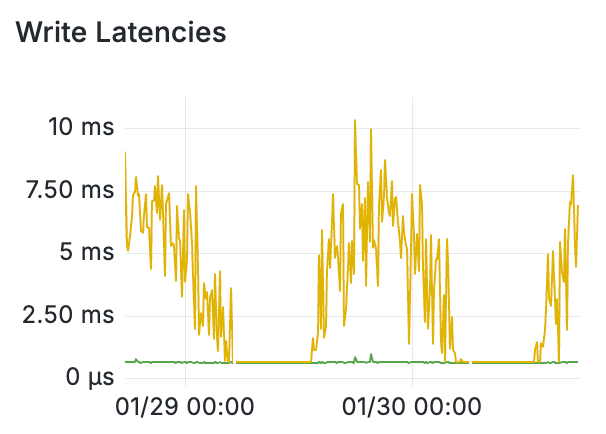
这对我们的扇出意味着什么?好吧,如果我们同时写入 1,000 个时间线,从统计上看,我们会看到 10 个写入速度慢于或慢于 15 毫秒。
在时间线的情况下,关注者的每个“页面”有 10,000 个用户大,并且在我们获取下一页之前,必须将每个“页面”展开。
这意味着我们最慢的写入将阻碍下一页的获取和扇出。这对我们预期的扇出时间有何影响?
每个“页面”将有约 100 次写入,与 P99 延迟一样慢或更慢。如果我们运气不好,他们可能会全部叠加在一个例程上,最终将单个扇出页面的速度减慢至 1.5 秒。
在最坏的情况下,对于我们 2,000,000 名粉丝的名人来说,他们的帖子 Fanout 最终可能需要长达 5 分钟的时间!
这甚至没有考虑 P99.9 和 P99.99 延迟,它们最终可能 >1 秒,这可能会让我们等待扇出作业数十分钟。
现在想象一下,对于拥有超过 20,000,000 名粉丝的用户来说,这将是多么糟糕!
那么,我们如何解决这个问题呢?当然是拥抱不完美!
有损时间线
想象一下一个关注了数十万其他人的用户。他们的时间线每秒被写入数百次,移动速度如此之快,即使这是他们的全职工作,人类也无法跟上整个时间线。
对于给定的用户来说,存在一个阈值,超过该阈值他们就无法跟上他们的时间线。除此之外,他们可能通过各种其他提要消费内容,并且不主要使用他们的关注提要。
此外,除此之外,我们不必拥有他们所关注的数千名用户发布的所有内容的完美年表,但提供足够的内容以使时间轴始终有新内容,这是合理的。
请注意,在这种情况下,我使用“合理”一词来宽松地表达,作为社交媒体服务,我们期望为单个用户完成的工作量必须受到限制。
如果我们引入一种机制来降低时间线的正确性,从而限制单个时间线可以在数据库分片上放置的工作量,该怎么办?
我们可以对用户应该拥有健康且活跃的时间线的关注数量设定一个reasonable limit ,然后在超过该限制后增加其时间线的“损失”。
loss_factor可以定义为min(reasonable_limit/num_follows, 1) ,并且可用于概率性地删除对时间轴的写入以防止热分片。
在 Fanout 中写入页面之前,我们可以生成一个0到1之间的随机浮点数,然后将其与页面中每个用户的loss_factor进行比较。如果用户的loss_factor小于生成的浮点数,我们会将用户过滤出页面,并且不会写入他们的时间轴。
现在,用户都拥有相同数量的扇出“关注价值”。例如, reasonable_limit为 2,000 时,关注其他 4,000 名用户的用户的loss_factor将为0.5 ,这意味着对其时间线的一半写入将被丢弃。对于关注其他 8,000 名用户的用户来说,他们的丢失系数为0.25将导致其时间线中 75% 的写入丢失。
因此,每个用户对其时间线完成的扇出工作量都有一个有效的上限。
通过规定合理的用户行为的界限,并接受超出界限的用户的不完美,我们可以在不牺牲系统可扩展性的情况下,继续提供满足用户期望的服务。
除了缓存
在一天中的繁忙时段,我们以每秒超过一百万次的速度写入时间线。在向给定用户分发之前查找其关注数量将需要每秒对我们的主数据库集群进行超过一百万次的额外读取。我们的数据库不会很好地接受这种额外的负载,并且额外的成本不值得为了更快的时间线扇出而付出代价。
相反,我们实现了一种方法,将高关注度帐户缓存在 Redis 排序集中,然后扇出服务的每个实例每 30 秒将该集的更新版本加载到内存中。
这使我们能够在每个 Fanount 服务实例上每秒数百万次地查找高关注帐户的关注计数。
在这种情况下,通过缓存不需要完美即可正常运行的值,我们可以再次接受系统中的缺陷,以提高性能和可扩展性,而不会影响服务的功能。
结果
几周前,我们在生产系统上实施了有损时间线,并发现时间线数据库集群上的热分片大幅减少。
事实上,现在集群中似乎根本没有热分片,Fanout 工作的一个页面的 P99 已经减少了 90% 以上。
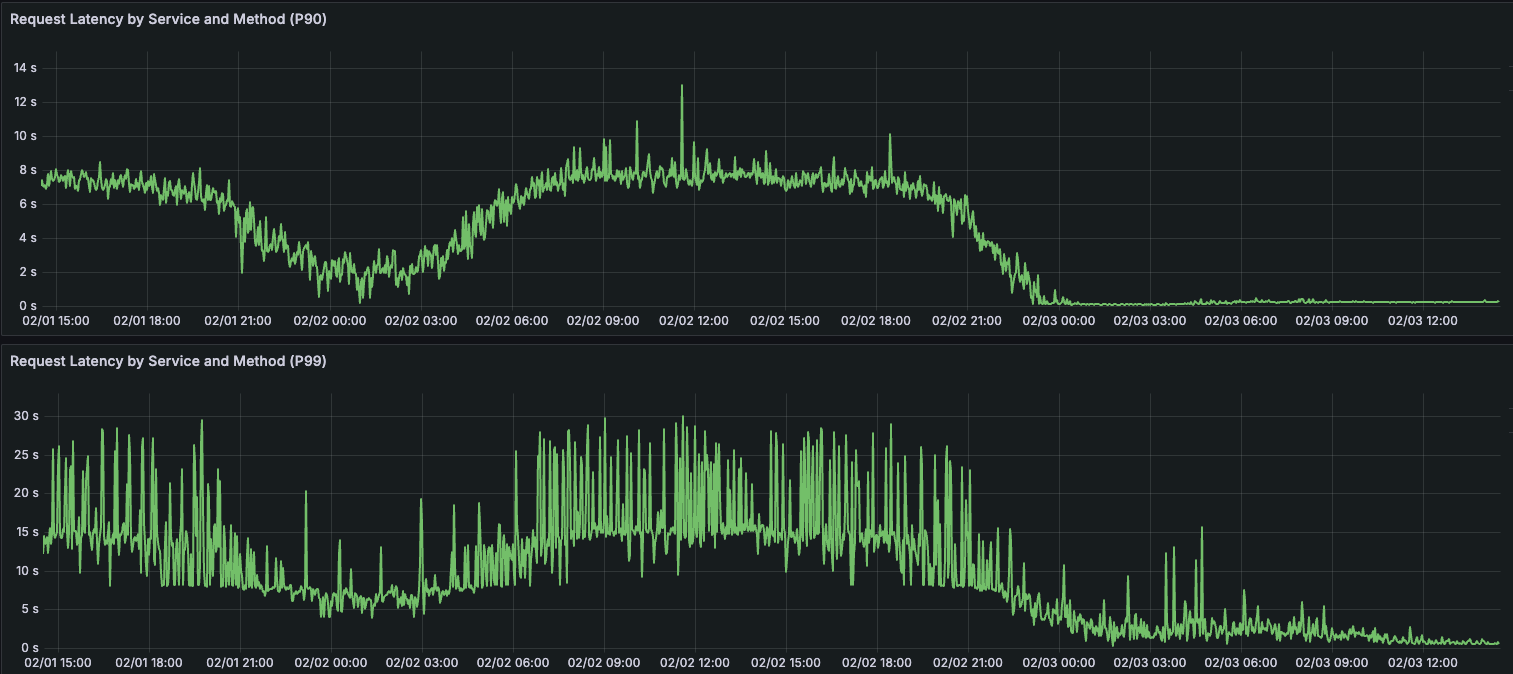
此外,随着写入 P99 的减少,完整后扇出的 P99 持续时间减少了 96% 以上。过去大型客户需要 5-10 分钟才能完成的工作现在只需不到 10 秒。
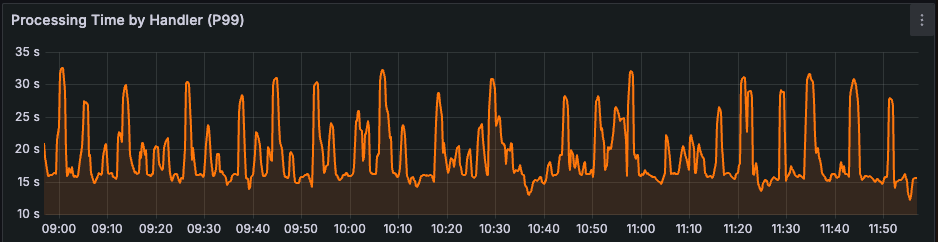
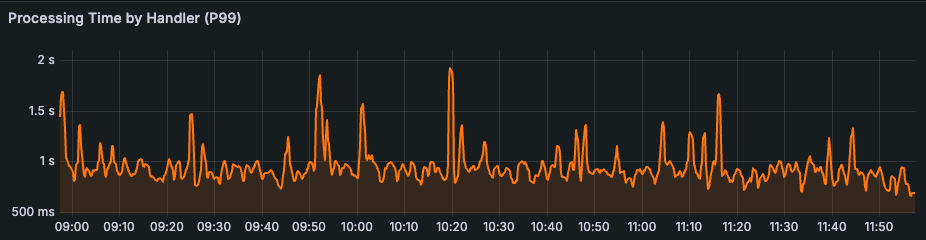
了解哪里可以不完美,让您可以用一致性来换取系统的其他理想方面,并扩大规模。
我们的时间线架构还有很多其他地方需要改进,但这一步对于提高 Bluesky 时间线的吞吐量和可扩展性来说是一大进步。
如果您对此类问题感兴趣并希望帮助我们构建为 Bluesky 提供支持的核心数据服务,请查看此职位列表。
如果您对 Bluesky 的其他空缺职位感兴趣,可以在这里找到。